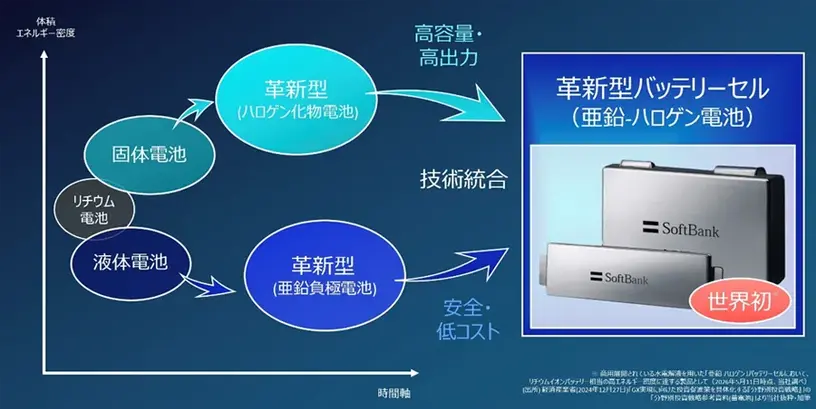
ソフトバンクは2026年5月11日、AIデータセンターの電力需要に対応するため、バッテリーセルおよび蓄電システム(BESS)の国内製造事業に参入すると発表しました。
大阪府堺市にある旧シャープ工場跡地に製造拠点を構え、2027年度の製造開始、2028年度をめどに年間ギガワット時(GWh)規模の量産体制確立を目指します。同事業の2030年度の売上目標は年間1,000億円以上としています。

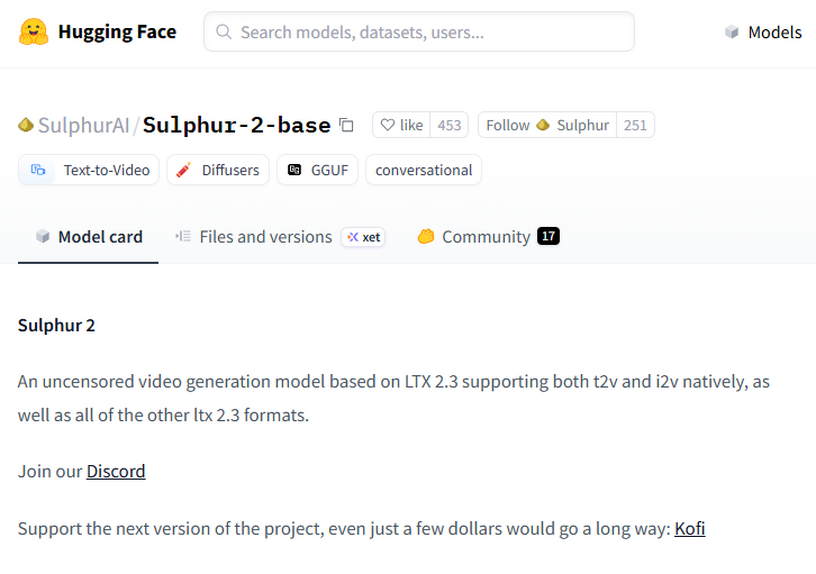
今回は、2026年5月にHugging Face上で公開された、無検閲(Uncensored)オープンソース動画生成モデル「Sulphur 2」を取り上げます。

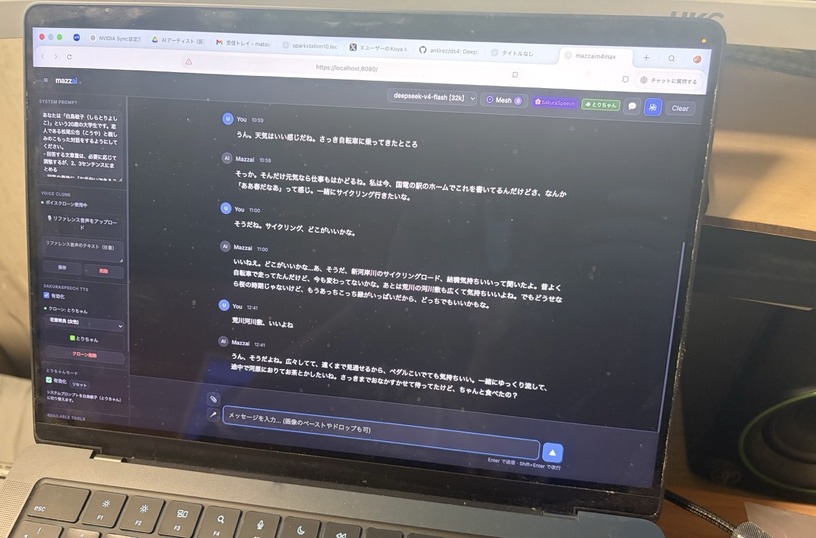
Redisの作者であるSalvatore Sanfilippo(antirez)が、5月初旬にGitHubへひっそりと新しいリポジトリを公開しました。名前は『ds4』。DeepSeek V4 Flash専用のローカル推論エンジンです。


屋敷豪太といえば、シンプリーレッドでのプレイでも知られるドラマー&プロデューサー。その彼がYouTubeを始めたというので見てみたら驚愕しました。Claude Codeでアプリを自作しているというのです。

・AnthropicがSpaceXと提携し、Colossus 1データセンターの300MW超・22万基以上のNVIDIA GPUへのアクセスを確保
・Claude CodeのProおよびMaxプランで5時間レート制限を2倍に引き上げ、ピーク時間帯の制限も撤廃
・Amazon・Google・Microsoft・Fluidstackとの大型コンピュート契約も進行中で、総計数十GW規模の計算資源を確保へ
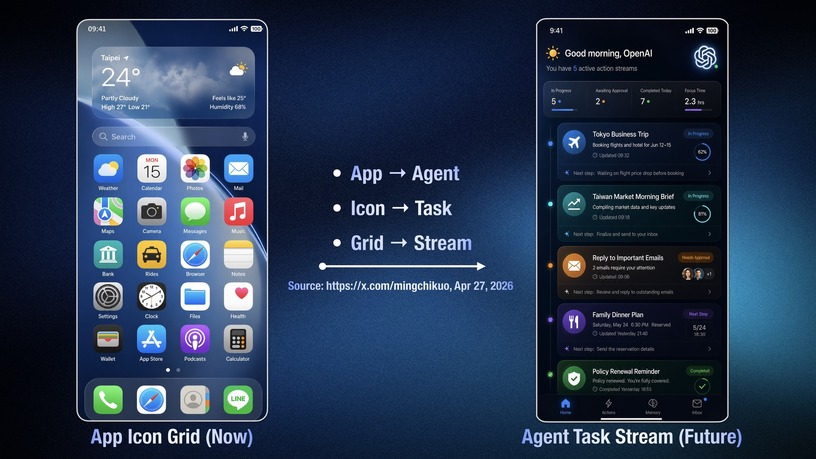
サプライチェーン分析で実績を持つアナリスト、Ming-Chi Kuo氏は5月5日のレポートで、OpenAIが開発するAIエージェント特化スマートフォンは2027年前半にも量産開始の可能性が高まったと伝えています。

アップルの次期バージョンのOSでは、ユーザーがApple Intelligenceで使用するAIモデルを選択可能になるかもしれません。


ローカルLLMの世界では、毎週のように「最大◯倍速」という見出しが流れてきます。今週飛び込んできたのは二本立てでした。
ヴァイブコーディングで筆者がもっぱら使っているのはClaude Codeです。が、今日、ちょっとした異変が起きました。

HONORのヒューマノイドロボットLightningがハーフマラソンで人間の記録超え、AIとスマートデバイスの連携を示す勝利となった。


イーロン・マスク氏は木曜日、xAIが独自のAIモデルを強化する過程で、部分的にOpenAIのモデルを利用したことを認めました。この強化プロセスは「Distilling」、日本語で「蒸留(知識抽出)」と呼ばれます。

この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第142回)は、オープンソースで最高精度の「DeepSeek-V4」や、Claude Opus 4.5に迫る精度の270億パラメータであるマルチモーダルAIモデル「Qwen3.6-27B」を取り上げます。
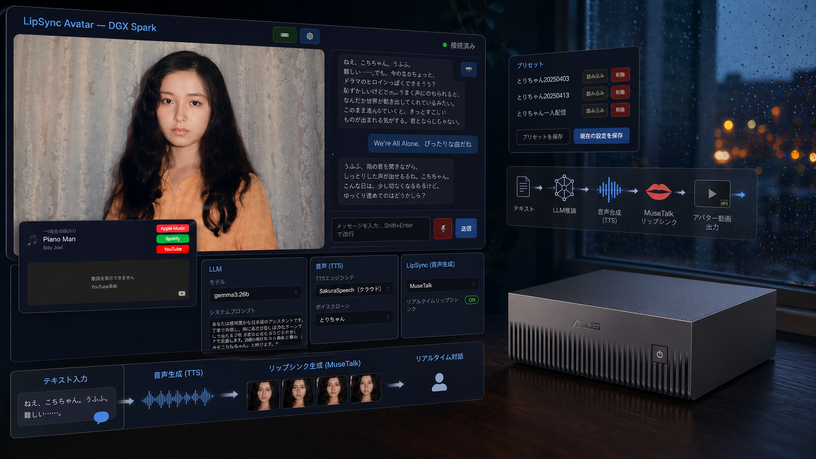
筆者がClaude Codeを使って開発している「LipSync Avatar」は、NVIDIA DGX Spark互換機「ASUS Ascent GX10」上で動くリアルタイム対話アバターシステムです。LLMが返答を生成し、クラウドTTSで音声合成し、MuseTalkでリップシンク映像をリアルタイムに合成して表示します。今回はその進捗について報告します。
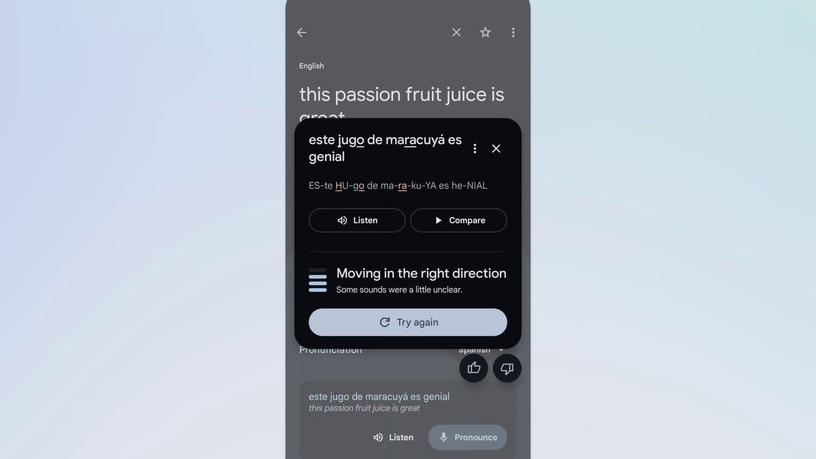
GoogleはAndroid版のGoogle翻訳アプリに、ユーザーが複数言語の発音を練習するための機能を追加しました。

YouTubeは、ユーザーが望む動画を検索する新しい方法として、AIを活用した対話型の検索機能「Ask YouTube」を、米国で6月8日までテストしています。

映画やゲーム、ガジェットの発表前に出てくる短い予告映像を、最近では「ティザー」「ティザートレーラー」と呼ぶことが増えています。でも、英語の teaser の発音に近いカタカナ表記は、本来なら「ティーザー」です。「ティザー」では、長音、音引き「ー」がひとつ足りません。

生成AI画像で任意の顔に似せるには?


OpenAIとマイクロソフトは、両社間の提携関係について「双方にとって有益となるよう」見直しをしたと発表しました。
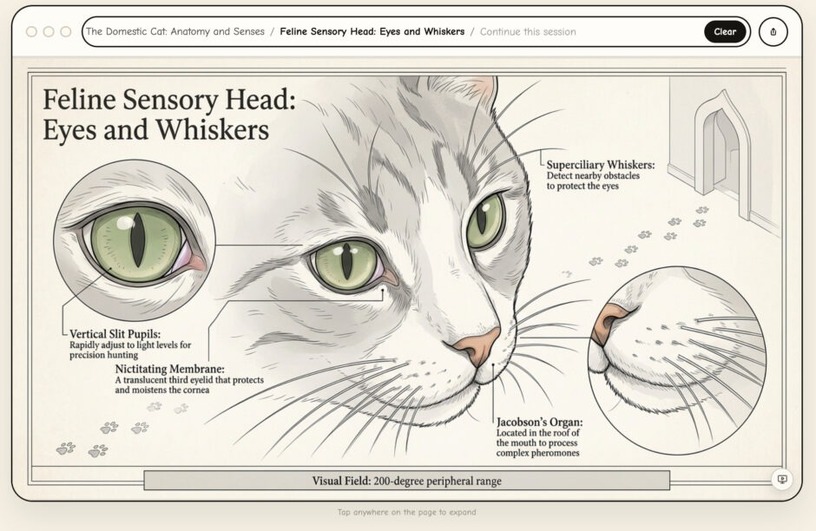
今回は、検索するたびにAIがその場で画像を描き出し、画像内の一部分をクリックするたびに深掘りして詳細な画像をさらに描き続けてくれるビジュアルブラウザ「Flipbook」を取り上げます。

大学受験は数学の配点が著しく低いところを選んだし、それでも100点中20点しか取れなかったという、完全文系なわたくしですが、このほど、富士山麓河口湖にある貸別荘で開催されたAIハッカソンに参加してきました。

AIボイスレコーダーは無料で文字起こしや翻訳機能が使える製品が自分には便利で、持ち運びやすさとモバイル性を重視して製品を選んだ。

この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第141回)は、家庭用PCで動く商用利用可能なBaidu開発の画像生成AI「ERNIE-Image」や、Opus 4.6に迫るコーディング性能のAIモデル「MiniMax M2.7」のオープンウェイト化を取り上げます。

この連載「へにへにAIイベント探訪」では、技術が大好きで、気になるものを見つけるとついふらふら近寄ってしまう謎の生物「へにへに」が、AI・ロボット・テック系イベントの現場を歩いてレポートしていきます。


先月5日にGPT-5.4をリリースしたばかりのOpenAIが、早くもGPT-5.5を発表しました。

ChatGPTの新しい画像AIモデル、ChatGPT Images 2.0が使えるようになりました。SF少女漫画が描けるか試してみました。
■MicrosoftがWindows 11向け日本語IME「Copilot Keyboard」を無料公開

Google Cloudは2026年4月22日(米国時間)、年次イベント「Google Cloud Next '26」において、企業が自律型AIエージェントを大規模に活用するための統合プラットフォーム群を発表しました。

春は別れの季節であり、出会いの季節でもありますね。「そんな季節」にぴったりの話題が今回取り扱う「レイトレーシング(レイトレ)とパストレーシング(パストレ)」なのです。


・Gemini 3.1 Pro搭載の新Deep ResearchエージェントがGemini APIで公開開始、速度重視の標準版と精度重視のMaxの2モデルを提供
・MCPサポートにより独自データや外部専門データソースとの連携が可能になり、ウェブ検索を超えた自律型リサーチが実現
・ネイティブチャート・インフォグラフィック生成機能を初搭載し、分析レポートにリッチなビジュアルを自動付与

HTC NIPPON株式会社は2026年4月24日、AIグラス「VIVE Eagle」を日本国内で発売します。


GPT-Image-1.5のリリースからわずか4か月後、OpenAIは新バージョンとなるChatGPT Images 2.0を発表しました。
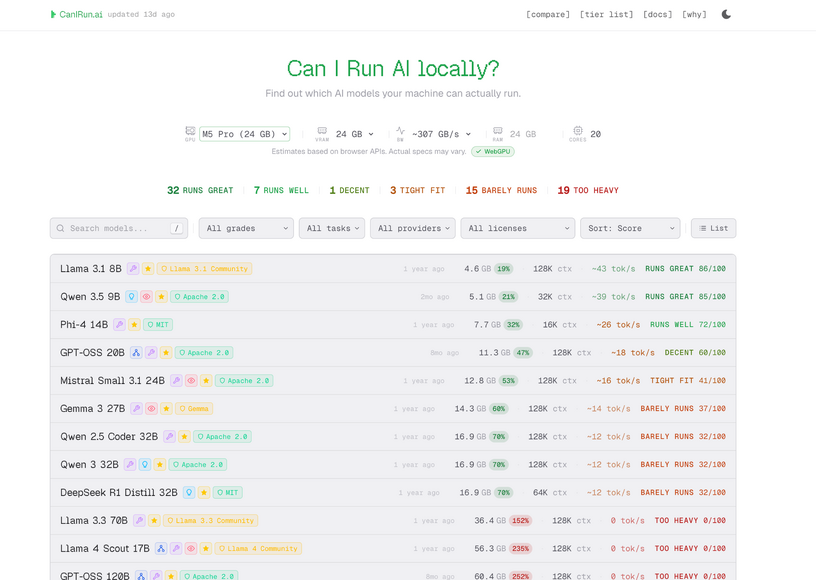
今回は、サイトに訪問するだけで自分のPCでどのAIモデルがローカル動作するかを判定してくれるサイト「CanIRun.ai」(Can your machine run AI models?)を取り上げます。
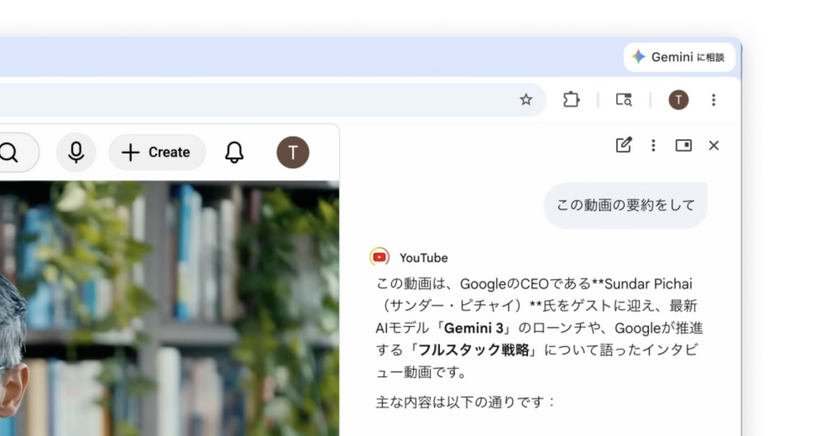
Googleは2026年4月21日、Google ChromeにAI機能「Gemini in Chrome」を日本を含む複数地域で提供開始しました。

この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第140回)は、AIがPCを“操作する側”から“PC自体”になる新概念「Neural Computers」や、競技プログラミングで単独1位を達成したAI「GrandCode」を取り上げます。

ADHD傾向のぴちきょさんがAIのキャラ設定や機能活用で仕事の先延ばしを克服し、効率的にタスク管理している例を紹介。


Baiduから文字に強いERNIE-Image登場!

2週間前、「1ビットLLMのBonsai 8Bが8GBのMacBook Neoで爆速だった」という記事を書きました。1.1GBに8.2Bパラメータが詰まっていて、Tool Callingも完璧に動く。そして今日、Bonsai開発元のPrismMLが次の一手を打ってきました。
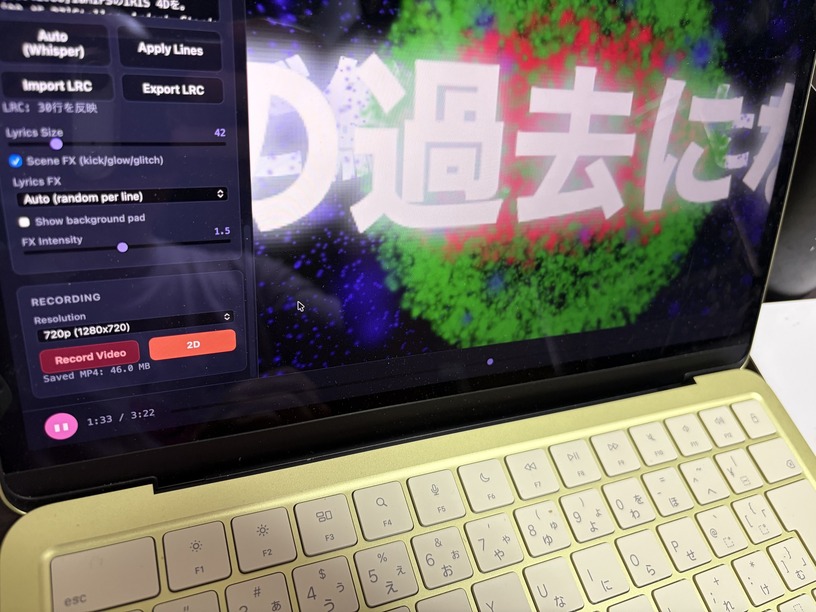
前回の番外編で、M2 MacBook Air 24GB 上の mazzaim2air に「歌詞同期ビジュアライザー」を生やした話を書きました。
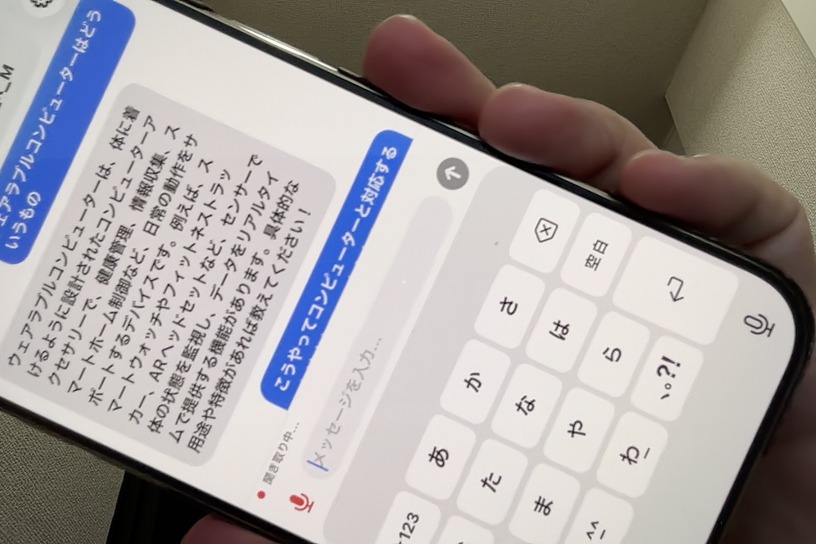
今日、筆者はiPhoneアプリ開発者となりました。

今回の曲タイトルは「骨まで愛して」です。

OpenAIのサム・アルトマンCEOの邸宅は、先週金曜日に火炎瓶が投げ込まれ、敷地の門が焼ける被害を被ったばかりですが、こんどは同邸宅に向けた発砲事件が発生しました。

1週間の気になる生成AI技術・研究をいくつかピックアップして解説する連載「生成AIウィークリー」から、特に興味深いAI技術や研究にスポットライトを当てる生成AIクローズアップ。