1週間の気になる生成AI技術・研究をいくつかピックアップして解説する連載「生成AIウィークリー」から、特に興味深いAI技術や研究にスポットライトを当てる生成AIクローズアップ。
今回は、OpenAIとジョージア工科大学の研究チームが発表した論文「Why Language Models Hallucinate」を取り上げます。大規模言語モデル(LLM)がなぜ事実と異なる情報「幻覚」(ハルシネーション)を自信満々に生成してしまうのか、その根本原因を明らかにして解決策を提案した研究です。

▲論文のトップページ
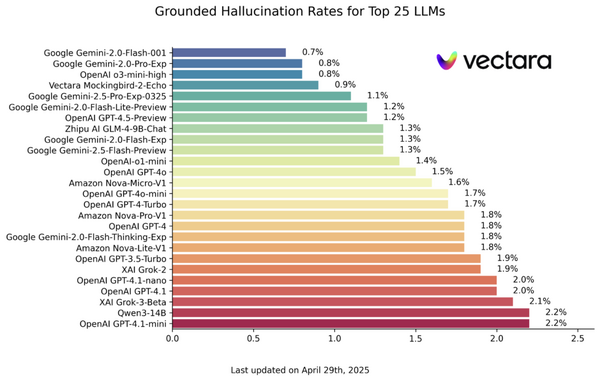
LLMの「幻覚」とは、AIが不確実な情報について「分かりません」と答える代わりに、もっともらしいが誤った内容を生成してしまう現象です。
研究チームは、この現象を「難しい試験問題に直面した学生の行動」になぞらえて説明しています。正解が分からない場合、学生は空欄にするよりも推測して何か答えを書く傾向があります。これは現在の採点システムが、無回答や「分からない」という回答に対して確実に0点を与えるため、運良く正解する可能性がある推測した回答の方が期待値が高くなるからです。
現在のAI評価システムも同じ問題を抱えています。主要なベンチマーク(GPQA、MMLU-Pro、SWE-benchなど)の多くが二値的な採点を採用しており、「分からない」という回答に点数を与えません。その結果、不確実でも推測して答えるモデルの方が高評価を得てしまい、開発者には幻覚を減らすインセンティブが働きにくい状況が生まれています。
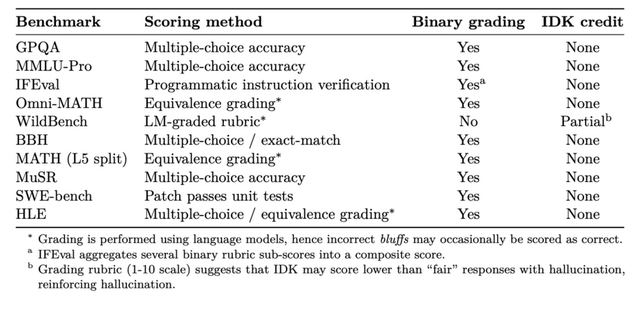
▲主要なAI評価ベンチマークの採点方法を分析した表
研究チームは数学的分析により、AIにとって「答えが正しいかどうかを判定する」ことと「正しい答えを自分で作り出す」ことでは、難易度に大きな差があることを証明しました。AIが答えを生成する際の間違いの確率は、既存の答えの正誤を判定する際の間違いの確率の少なくとも2倍になることがわかりました。
このような幻覚が発生する状況の中での解決策も提案しています。例えば「75%以上の確信がある場合のみ回答してください。誤答は2点減点、正答は1点加点、『分からない』は0点です」といった指示を追加することです。これにより、モデルが適切に分からないことを表明できるようになります。
重要なのは、新しい幻覚評価手法を追加するだけでなく、既存の主流ベンチマークそのものを修正し、リーダーボードで採用される必要があるという点です。