


この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第117回)は、過度な圧縮をしない画像生成AI技術「RAE」や、長時間動画をリアルタイムに理解できるAIモデル「StreamingVLM」を取り上げます。
また、32BパラメータのAIモデルを1台のH100 GPUで強化学習できるフレームワーク「QeRL」や、音声合成と音楽生成の両方を実行できるAIモデル「UniMoE-Audio」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、AIの生成において、同じような答えばかり返ってしまう問題を解決する方法を提案した研究を別の単体記事で取り上げています。

VAEを代替する過度に圧縮しない新しい画像生成AI技術「RAE」、品質が向上し高速に
ニューヨーク大学の研究チームが、画像生成AIの新しい手法「Representation Autoencoders」(RAE)を発表しました。
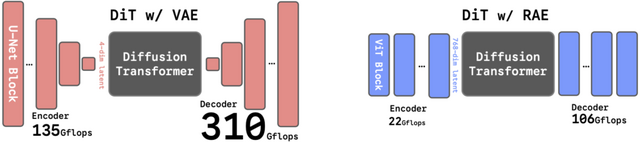
これまでの画像生成AI(Diffusion Transformersなど)は、VAEエンコーダーと呼ばれる古い技術を使って画像データを圧縮していました。しかし、この圧縮プロセスで画像の細かい情報や意味的な理解が失われ、生成品質に限界がありました。RAEは、このVAEによる過度な圧縮をやめて、代わりに最新の画像認識AIを活用するというアプローチを行います。
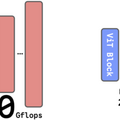
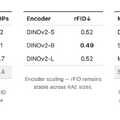
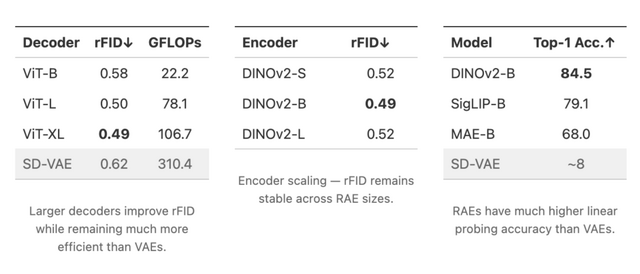
RAEでは、画像認識AI(DINOv2、SigLIP、MAEなど)と軽量な学習済みデコーダーを組み合わせます。仕組みは、画像の意味的な特徴を保持したまま処理でき、従来のVAEが画像を過度に圧縮していたのに対し、RAEは豊富な情報を維持しながら効率的に画像を生成できます。
研究チームは、この高次元データを扱うための技術的工夫を導入し、安定した学習を実現しました。さらに、計算効率を高めるため「DiTDH」というモデル構造も開発しました。これにより、少ない計算量で高品質な画像を生成できるようになりました。
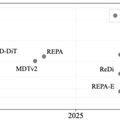
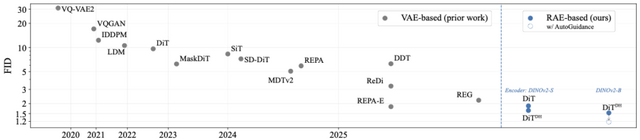
実験では、ImageNetデータセットで高いレベルの画像品質を達成しました。256×256ピクセルの画像(ガイダンスなし)でFIDスコア1.51、256×256と512×512ピクセルの両方の画像でFIDスコア1.13(ガイダンスあり)を記録し、従来の最高記録を大幅に更新しました。また、学習速度も従来の手法と比べて最大47倍高速化され、より効率的な開発が可能になりました。
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, Saining Xie
Project | Paper | GitHub
“ほぼ無限”の長時間動画をリアルタイムに理解できるAIモデル「StreamingVLM」をMITとNVIDIAの研究者らが開発
MITとNVIDIAの研究チームが、理論的に無限に長い動画をリアルタイムで理解できるAIモデル「StreamingVLM」を開発しました。長時間の動画をリアルタイムに理解し、説明できるAIは、例えば、スポーツの試合を見ながら実況したり、監視カメラの映像を常時チェックしたりする用途で活躍が期待されています。
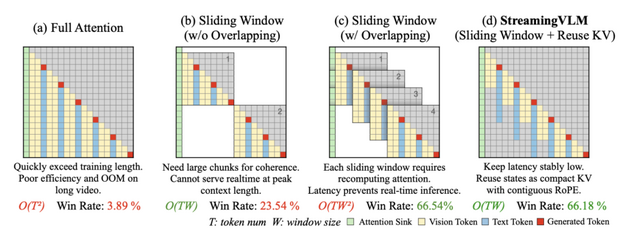
従来の動画理解AIは、長時間の動画を処理しようとすると深刻な問題に直面していました。動画全体を一度に処理するとメモリが不足し、かつ処理時間が増加します。一方で、動画を小さく区切って処理すると、前後の文脈が失われて内容の一貫性が保てなくなる問題がありました。
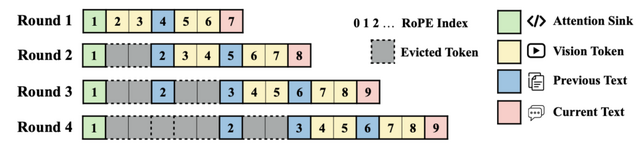
StreamingVLMは、動画の重要な部分(512トークン)と最近見た部分(最新16秒の動画)だけをメモリに保持し、古い部分は徐々に忘れる仕組みです。過去に一度計算した結果(KVキャッシュ)を再利用することで、同じ計算を繰り返さず効率的に処理できます。この「選択的な記憶」と「計算結果の再利用」により、少ないメモリで長時間の動画を途切れなく理解できるようになりました。
このフレームワークを用いて、4000時間以上のスポーツ実況データセット「Inf-Streams-Train」と、平均2時間以上の動画の評価ベンチマーク「Inf-Streams-Eval」を構築しました。StreamingVLMは、Qwen-2.5-VL-7B-Instructをファインチューニングして開発されました。
評価実験では、Inf-Streams-Evalで性能を検証し、OpenAIのGPT-4O miniに対して66.18%の勝率を達成しています。
実際の使用例として、StreamingVLMは2時間を超えるサッカーの試合を最初から最後まで実況解説できることが実証されました。キックオフの場面から試合終了まで、過去の出来事を記憶しながら一貫性のある解説を提供します。
1台のNVIDIA H100 GPUで毎秒8フレームの処理速度を維持し、リアルタイム性能を実現しています。



StreamingVLM: Real-Time Understanding for Infinite Video Streams
Ruyi Xu, Guangxuan Xiao, Yukang Chen, Liuning He, Kelly Peng, Yao Lu, Song Han
Paper | GitHub
1台のH100 GPU上で320億パラメータLLMの強化学習を可能にするフレームワーク「QeRL」をNVIDIAなどが開発
大規模言語モデルの推論能力向上には強化学習が重要ですが、膨大なGPUメモリと長時間の計算が必要という課題がありました。NVIDIAやMITなどの研究チームが開発した「QeRL」は、この問題を解決する新しいフレームワークです。
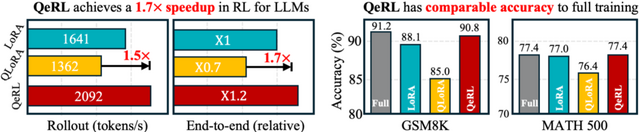
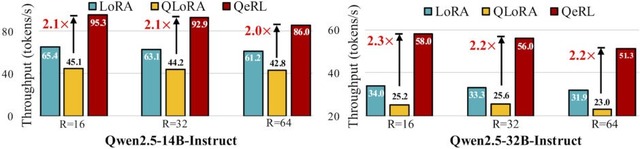
QeRLは、「NVFP4」という4ビット量子化形式とLoRAを組み合わせることで、モデルのメモリ使用量を大幅に削減しながら、訓練速度を向上させます。従来の16ビット精度モデルと比較して、メモリ使用量を削減し、訓練速度を1.5倍以上向上させることに成功しています。
研究チームは興味深い発見をしています。量子化によって生じるノイズが、強化学習における探索能力を向上させるというものです。量子化で生じるノイズは、通常の学習では精度を下げる欠点となります。しかし強化学習では、このノイズがAIの判断を「あいまい」にすることで、一つの答えに固執せず様々な選択肢を試すようになり、強化学習では逆に利点となることを示しています。
QeRLは、トレーニング中にノイズを動的に調整する「Adaptive Quantization Noise」 (AQN) メカニズムを導入します。
実験では、Qwen2.5シリーズのモデル(3B、7B、14B、32B)を用いて、GSM8KやMATH500などの数学的推論ベンチマークで評価を行いました。QeRLは従来の16ビットLoRAやQLoRAを上回る性能を示し、完全パラメータ訓練に匹敵する精度を達成しています。例えば7Bモデルでは、GSM8Kベンチマークで90.8%の精度を達成し、16ビットLoRAの88.1%を上回りました。
特筆すべきは、32B(320億)パラメータのモデルを1台のH100 80GB GPUで強化学習訓練できるようになったことです。

QeRL: Beyond Efficiency - Quantization-enhanced Reinforcement Learning for LLMs
Wei Huang, Yi Ge, Shuai Yang, Yicheng Xiao, Huizi Mao, Yujun Lin, Hanrong Ye, Sifei Liu, Ka Chun Cheung, Hongxu Yin, Yao Lu, Xiaojuan Qi, Song Han, Yukang Chen
Paper | GitHub
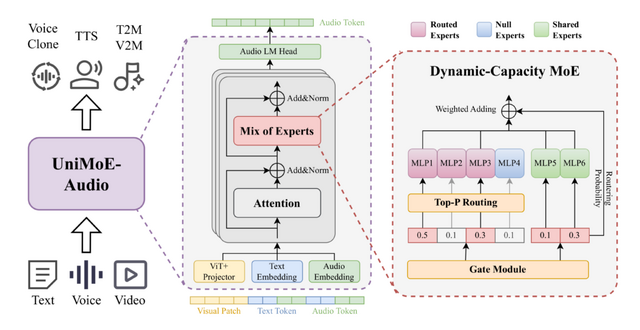
「音声合成」と「音楽生成」の両方を実行できるAIモデル「UniMoE-Audio」
「UniMoE-Audio」は、音声合成と音楽生成を単一モデルで実現する新しいAIフレームワークです。テキストや音声、ビデオ入力から音声合成や音楽生成、ボイスクローニングなどを可能にします。
従来、音声と音楽の生成は別々のモデルで行われてきました。音声生成では意味の明瞭性と話者の個性が重要である一方、音楽生成では和声やリズムの複雑な構造が重視されるため、これらを単一モデルで扱うことは困難でした。さらに、高品質な音声データが音楽データよりもはるかに豊富に存在するというデータの不均衡も、統合モデルの開発を妨げる要因となっていました。
このモデルは「Dynamic-Capacity MoE」アーキテクチャを採用し、両タスクを統合しています。各入力の複雑さに応じて専門家モジュールを動的に割り当てることで、効率的な処理を実現しています。
3段階の訓練プロセスにより、まず個別タスクの専門家を育成し、次にそれらを統合、最後に全体を最適化することで、データ不均衡の問題を解決しました。
実験では、音声合成で最先端の性能を達成し、音楽生成では特に美的品質で優れた結果を示しました。特に、28万時間の音声データのみで、1000万時間以上のデータで訓練された専門モデルと同等の性能を実現しています。
UniMoE-Audio: Unified Speech and Music Generation with Dynamic-Capacity MoE
Zhenyu Liu, Yunxin Li, Xuanyu Zhang, Qixun Teng, Shenyuan Jiang, Xinyu Chen, Haoyuan Shi, Jinchao Li, Qi Wang, Haolan Chen, Fanbo Meng, Mingjun Zhao, Yu Xu, Yancheng He, Baotian Hu, Min Zhang
Project | Paper | GitHub