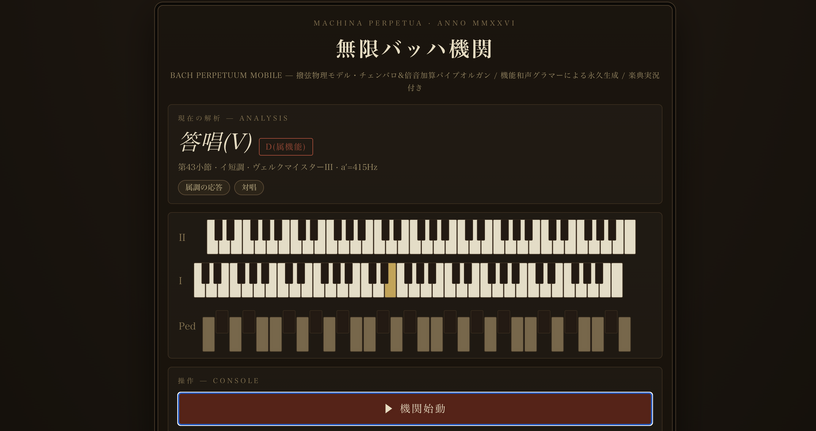
ヨハン・セバスチャン・バッハ手法の音楽を無限に紡ぎ出す装置を作った。AIで作ったけど、音楽はAI生成ではありません(CloseBox)
ELPのキース・エマーソン、ギタリストのエリック・クラプトンの自動生成に続いて、現在のポピュラーミュージックの共通言語とも言える音楽理論のインタラクティブ教科書をClaude Fable 5で作成。次は古典に挑戦してみます。


生成AIグラビアをグラビアカメラマンが作るとどうなる?第71回:衣装チェンジ、画像コピーからアウトペイントまで、Krea 2界隈はますます活発に(西川和久)
ますます活発なKrea 2。ControlNetからEdit、LoRAまで。


OpenAI、未公開AIモデルが試験環境から逸脱。Hugging Faceサーバーに侵入する前例のない事案に発展
OpenAIは、同社のAIモデルがサイバー能力の内部評価テスト中にサンドボックス環境を脱出し、Hugging Faceの本番インフラに不正アクセスするという事案が発生したと発表しました。

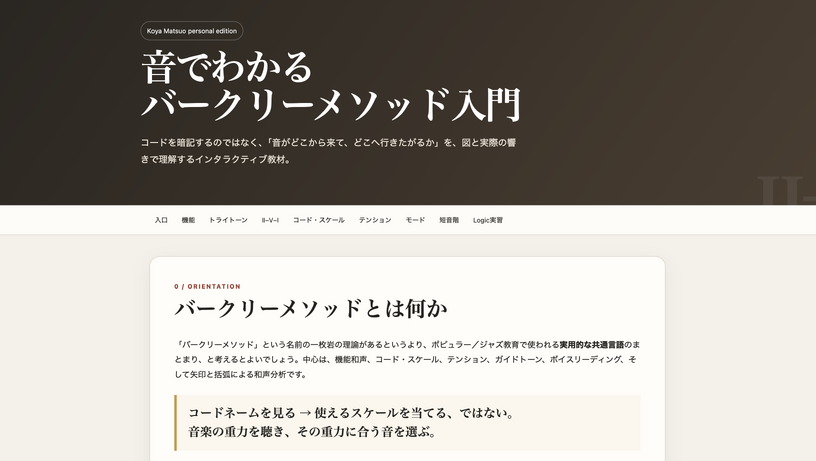
音楽理論がわからない? ならば自分で教材を作ってしまおう。ChatGPTとGeminiによる自分専用教科書構築メソッド(CloseBox)
このところ、音楽関連のヴァイブ・コーディングをやってきたおかげでだいぶ理解が深まった感じがあるのですが、やはり根本的なところを学んでいないのです。音楽理論。

GoogleがGemini新モデル3本を同時発表、AIエージェント向けに効率・速度・コストを強化
Googleが、AIモデルGeminiに新しく「Gemini 3.6 Flash」「Gemini 3.5 Flash-Lite」「Gemini 3.5 Flash Cyber」の3モデルを発表しました。
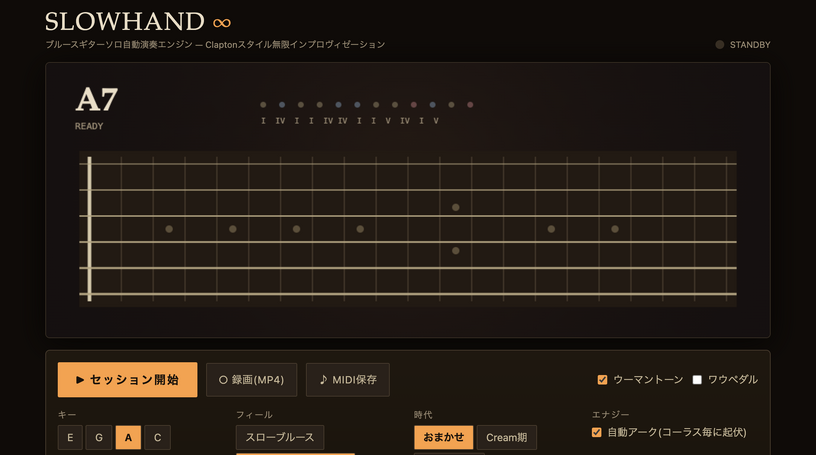
僕はブルースギターを弾けない。だからギターソロ自動演奏プログラム「SLOWHAND ∞」をClaude Fable 5に作ってもらった(CloseBox)
レノン=マッカートニー=ハリスン作曲マシン、ユーミン、筒美京平の楽曲手法を真似るソフト、ELPのキース・エマーソン風モーグソロを無限生成する「EMERSON MOOG INFINITY」と、ブラウザ上で音楽家をシミュレートするシリーズを続けてきましたが、今回はギターです。それもエリック・クラプトン。
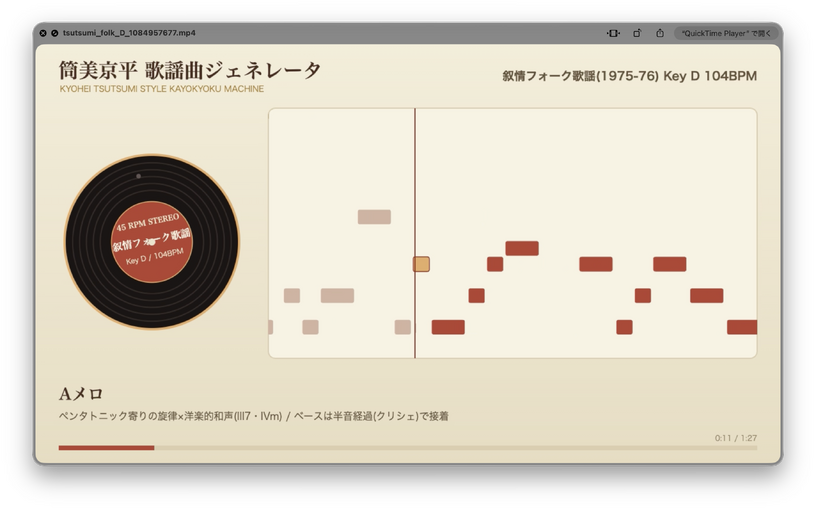
歌謡曲の巨匠サウンドをアルゴリズムで。ローカル生成するブラウザアプリをClaude Fable 5で作ってみた(CloseBox)
これまで、ビートルズ(ポール・マッカートニー、ジョン・レノン、ジョージ・ハリスン)、ユーミン(荒井由実時代)の作風をアルゴリズムとして組み込んだブラウザアプリを作ってきましたが、次は歌謡曲にチャンレンジしてみます。ターゲットは大好きな作曲家である筒美京平先生。果たしてどの程度できるのか?

GoogleのAI研究ツール「NotebookLM」が「Gemini Notebook」に改称、コード実行機能も追加
Googleが、AIリサーチアシスタント「NotebookLM」を「Gemini Notebook」に改名すると発表しました。
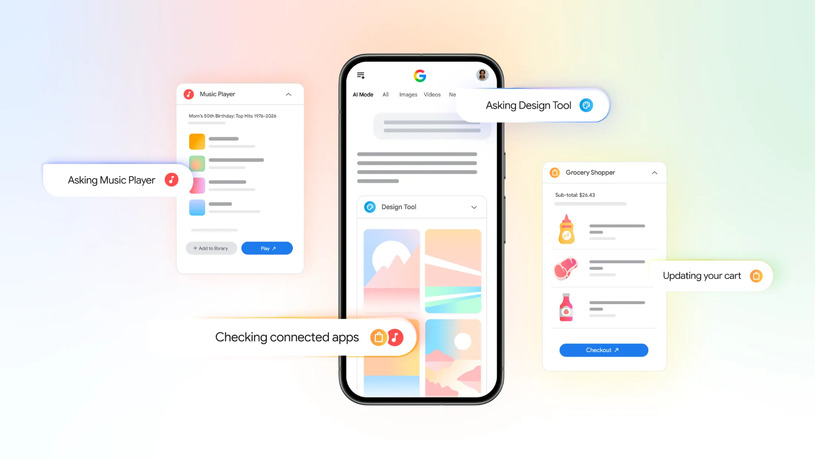
Google検索のAI ModeがYouTube Music、Canva、Instacartと連携可能に
Googleが、同社のウェブ検索で動作するAIモードと、YouTube Music、Canva、Instacartの3サービスとの連携機能を米国内で提供しはじめています。

「colibrì」が超巨大な7440億パラメータLLM「GLM-5.2」をメモリ25GBで稼働させる仕組み(生成AIクローズアップ)
今回は、巨大AIモデルを家庭用PCで動かせるようにするツール「colibrì」を取り上げます。


Apple Intelligence、中国での展開にGOサイン。BaiduとAlibabaのAIモデルを採用
アップルがiPhoneなどに搭載する生成AIサービス「Apple Intelligence」が、中国のサイバースペース規制当局への登録を完了しました。

「切なさ」はアルゴリズムで書けるか。初期ユーミン様式のバラード生成マシンをClaude Fable 5と作って考えたこと(CloseBox)
切ない曲ってどんなものでしょうか。Sunoで切ないバラードを生成したいときは、sentimental ballad, heart-aching, sorrowful, emotionalといった表現を使いますが、それが意味するところは?

連載「歌うテックニュース」第9回:Transformer論文を読めば、倦怠期カップルも愛を取り戻せるはずなのだ(西川善司)
今回の楽曲は、先日掲載された、ローカルSLMに対応したNVIDIAのゲーム向けAI技術のACEの記事にちなんだ歌です。


スマホでスキャナ品質のScanSnapカメラ提供開始 PFUもAIサブスクScanSnap Cloud+導入、手書きも理解してリンクつきPDF化
PFUは2026年7月14日、AIでスキャナを便利にするサブスクリプションサービス「ScanSnap Cloud+」と、スマホカメラでスキャナ品質の取り込みができる「ScanSnap Camera」の提供を開始しました。

連載「やってみようVibe Coding 」第2回:ヴァイブ・コーディングでできるのはプログラミングだけじゃない(小泉勝志郎)
Vibe Coding(ヴァイブorバイブ・コーディング)の入門連載第2回です。今回はOpenAIのCodexのインストール方法から、Gmailとの連携まで。


従来のゲーム制作手法のまま、AIの力でNPCを賢く見せるNVIDIAの新提案を徹底解説(西川善司のバビンチョなテクノコラム)
ゲームにおける、NPC(Non Player Character)制御に生成AI系技術を使えないか。より具体的に言えば、人間ではなく、ゲームシステム側で動かす相棒キャラクターや敵キャラクターを言語型の生成系AIで動かせないか……というテーマについて。
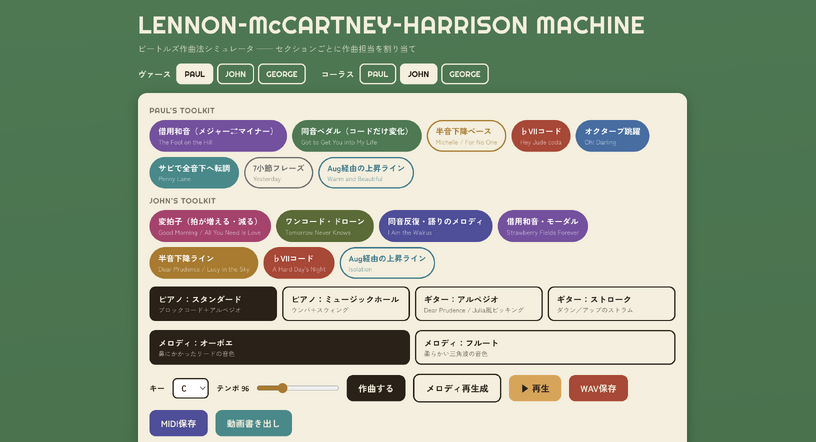
Fable 5でFab 4楽曲ジェネレーターを作ってみた。ビートルズっぽい楽曲はAI学習を使わないアルゴリズムでもできる?(CloseBox)
Claude Fable 5にアディショナルタイムが与えられました。この時間を活かして何かできないか。既存プロジェクトの改良とは別に、思いついたのが、作曲ソフトです。

Claude Opus 4.7に匹敵するコーディングAI「Ornith-1.0」、NVIDIAが「Qwen3.6」を軽量化4ビットモデルを商用利用可能で公開など生成AI技術5つを解説(生成AIウィークリー)
今回の「生成AIウィークリー」(第151回)は、Claude Opus 4.7に匹敵するコーディングAI「Ornith-1.0」や、動画から世界のしくみを学ぶAIモデル「Orca」を取り上げます。

Meta「Muse Spark 1.1」を一般公開。AIコーディング市場に算入
Meta Superintelligence Labsは、マルチモーダル推論AIモデル「Muse Spark 1.1」を発表しました。4月に発表された最初のモデルからエージェントタスク、コーディング、マルチモーダル理解の各分野での改善が盛り込まれたアップグレード版です。

SpaceXAI、新AIモデル「Grok 4.5」を正式公開 Cursorと共同トレーニング
xAI改めSpaceXAIは、最新AIモデル「Grok 4.5」を正式に一般公開しました。

Claude Fable 5のプロモ提供が延長、7月13日16時まで追加料金なしで利用可能に Anthropicが発表
・Claude Fable 5は2026年7月1日~12日の期間限定で、既存サブスクリプション内の週次利用枠の最大50%まで追加料金なしで利用可能
・週次利用上限の50%に達した後は、利用クレジット(別途課金)への切り替えか、他モデルへの変更で継続利用できる
・プロモーション終了後の7月12日以降は週次利用枠への無償包含が終了し、利用クレジットによる有償利用のみとなる

Claude Fable 5との残された時間に書いてもらった小説2作品、編集者とAI作家の対話には魂が宿っていたのか(CloseBox)
今朝(7月7日)、AnthropicがAIの内側に「J-space」と呼ぶ構造を発見した、というニュースが流れました。元になった論文は、「Verbalizable Representations Form a Global Workspace in Language Models」です。

大学への提出レポートが「100%AI生成」誤判定で学生を不正処分、その後、学生側勝訴(生成AIクローズアップ)
今回は、レポートを「100%AI生成」と判定され不正行為を疑われた学生が、大学を相手に処分の無効を訴えた裁判記録を取り上げます。

生成AIグラビアをグラビアカメラマンが作るとどうなる?第70回:Krea 2の勢いがもうどうにも止まらない(西川和久)
Krea 2だが、2026年6月23日にリリースされたばかりなのに、とにかくcheckpoint、LoRA、カスタムノード、Workflow……ものすごい勢いでCivitaiやHugging Face、GitHubに登録されだした。今回は筆者が日頃使ってるものから順にご紹介したい。

復活のGoogle Home スピーカーと暮らしてみた。Gemini for Homeの実力はいかほど?(Google Tales)
「Gemini for Home」の伝道という使命を帯びて登場した「Google Home スピーカー」を使ってみました。


Claude Mythos/Fableで学習したとする無検閲AI「Qwythos-9B」GGUF版が登場、商用利用可能な120億パラメータの画像生成AI「Krea 2」など生成AI技術5つを解説(生成AIウィークリー)
この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第150回)は、AIエージェントが動作する環境をシミュレートする言語モデル「Qwen-AgentWorld」、Claude Mythos/Fableで学習したと謳うローカル無検閲AI「Qwythos-9B」GGUF版を取り上げます。

AIエージェントに信頼できる名前を与える「Agent Name Service(ANS)」、Linux Foundationが発表。DNS基盤を拡張
Linux Foundationは、既存のドメインネームシステム(DNS)基盤を拡張してインターネット上で稼働するAIエージェントに信頼できる識別子としての名前などを提供する新しいオープンソース標準「Agent Name Service(ANS)」の立ち上げ意向を発表しました。


ついにClaude Fable 5が復帰。復活祭は7月7日までで、以降はサブスク勢も追加課金が必要に(CloseBox)
一般ユーザーが使える、現時点で最高峰のフロンティアAIであるClaude Fable 5が帰ってきました。

Anthropic、Claude Fable 5の明日復帰を予告。Opus 4.8よりちょい下のSonnet 5はすぐに使える(CloseBox)
米商務省の許諾が得られたということで、AnthropicはFable 5およびMythos 5の米国以外への提供を明日開始すると発表しました。

音楽ストリーミングのTidal、AI生成音楽関する新しいポリシーの導入を発表、収益化禁止・識別タグ表示へ
音楽ストリーミングサービスのTidalが、完全にAIで生成された音楽を用いて収益を得ることを阻止する新しいポリシーの導入を発表しました。さらに、アーティストやバンド、グループになりすまそうとするAI生成音楽を自動的に検出するツールも同時期の導入を予定しているとのことです。
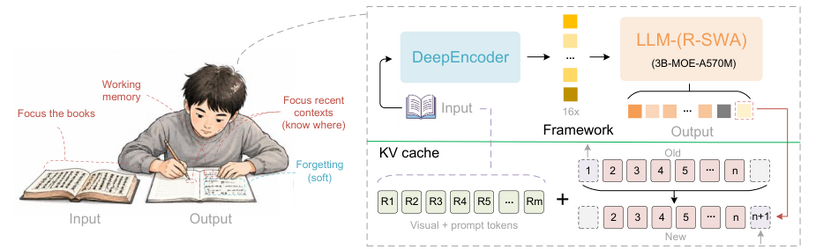
数十ページのPDFを1回で処理、ローカルOCRモデル「Unlimited OCR」をバイドゥが無料公開。商用利用もできる(生成AIクローズアップ)
今回の生成AIクローズアップは、Baiduの研究チームが開発した、数十ページのPDFなど長文を一括処理できるエンドツーエンドのOCRモデル「Unlimited OCR」を取り上げます。
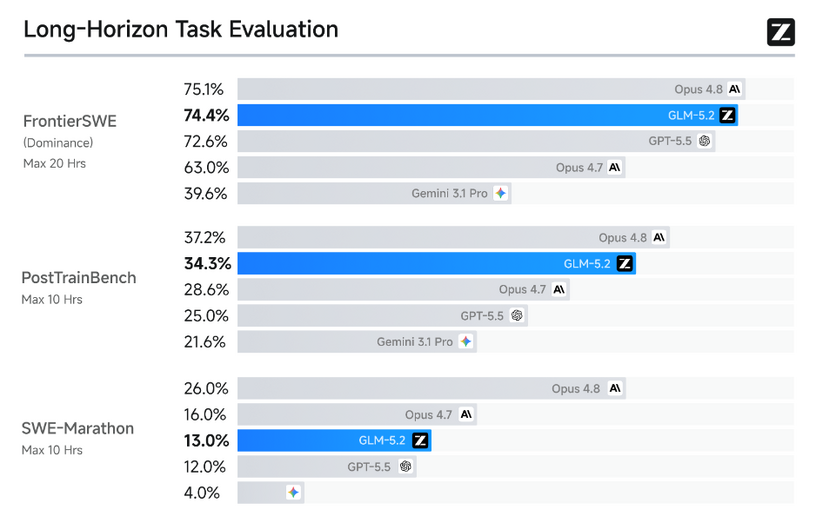
Opus 4.8に肉薄するオープンソースモデル「GLM-5.2」、VRAM4.5GBで動くコーディング特化AI「Gemma4-12B-Coder」など生成AI技術5つを解説(生成AIウィークリー)
この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第149回)は、Opus 4.8に肉薄するオープンソースモデル「GLM-5.2」や、テキストや画像から動き回れるゲーム世界を創るAI「DreamX-World 1.0」を取り上げます。

米政府、Anthropic「Mythos 5」を一部パートナー企業・組織に公開許可
AIスタートアップのAnthropicは、米政府から同社のAIモデル「Claude Mythos 5」を一部の信頼できるパートナー企業・組織に対して提供再開する許可を受けました。

6月30日19時開催。NVIDIAが参入し異変づくしのWindows用プロセッサ最新動向。西川善司のテクノエッジワークショップ
今回は、Intel、AMD、QualcommというWindowsプロセッサベンダーにNVIDIAが加わり様変わりしたPC市場がテーマ。NVIDIAの担当者に直接取材をした西川善司さんが事情を解説していきます。


OpenAI、次世代AIモデル「GPT-5.6」発表、まず米国政府承認ユーザーに限定プレビュー開始
OpenAIは、次世代AIモデル「GPT-5.6」シリーズとして、フラッグシップとなる「Sol」、バランスのとれた中級モデル「Terra」、低コストかつ高速な「Luna」の3種類を発表しました。

生成AIグラビアをグラビアカメラマンが作るとどうなる?第69回:Boogu-Image-0.1とKrea 2が登場。Z-Imageの牙城を崩せるか?(西川和久)
Boogu-Image-0.1

5分の動画素材を25分で生成。話題のワールドモデル「HappyOyster」を軸にしたMV制作の新潮流(CloseBox)
Claude作家の黒戸寓吾が創作したSFショートショート「至高の歌」をテーマにした楽曲のAIミュージックビデオを作りました。作詞:黒戸寓吾、補作詞:松尾公也、作曲:Suno、歌唱:妻音源とりちゃん。映像素材はHappy Oysterです。

Google、Gemini 3.5 FlashにPC・スマホ操作を自動実行する「コンピューター使用」機能を追加
Googleは、同社のAIモデル「Gemini 3.5 Flash」に、コンピューターの画面を認識して操作を実行する「コンピューター使用(computer use)」機能を組み込みツールとして統合したと発表しました。

Meta、299ドルからのAIスマートグラス新製品「Metaグラス」を発表。EssilorLuxotticaとのパートナーシップ
Metaは、イタリアのアイウェアメーカーEssilorLuxottica(エシロールルックスオティカ)とのパートナーシップによるAIグラスの新製品「Meta グラス」を発表しました。

Google、A24と映画制作向けAIツール開発で提携。7500万ドル(約121億円)を出資
Google DeepMindとハリウッドの映画会社 A24 は、映画制作向けAIツールの研究開発に向けた提携を発表しました。この提携ではGoogleがA24に対して約7500万ドル(約121億円)出資します。

Getty ImagesがOpenAIと複数年契約、ChatGPTにライセンス画像を提供へ
Getty Imagesは、OpenAIとの複数年にわたるパートナーシップ締結を発表しました。この契約により、Gettyのライセンス済みコンテンツライブラリがOpenAIのサービスに提供され、OpenAIの検索機能およびChatGPTの回答内にGettyの画像が表示されるようになります。
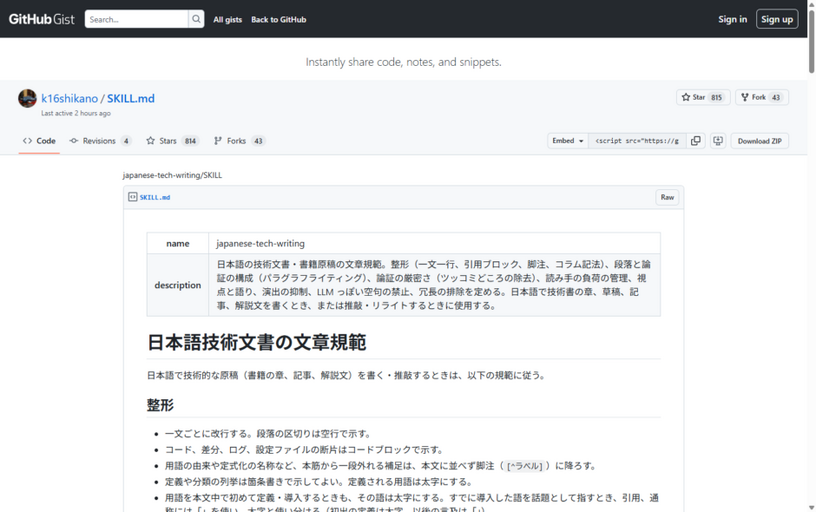
「AI臭い文章を生成させない」ルール集。LLMに“質の高い技術文書”を書かせるスキルを技術書出版社代表が公開(生成AIクローズアップ)
今回は、LLM(大規模言語モデル)に日本語の技術文書を書かせたり推敲させたりするためのAI向けの日本語文章規範スキル「japanese-tech-writing」を取り上げます。人間が技術書を書くときのやってはいけない注意事項ではなく、LLMにAIっぽい日本語文章を生成させないための指示書です。
- 1,097件中 1 - 42 件を表示
- 次へ