


この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第103回)は、プレイしながらプロンプトでゲームの世界をリアルタイム生成していくAIゲームエンジン「Mirage」や、Appleの新コーディング生成AI「DiffuCoder」を取り上げます。
また、長時間のアニメーションに自動着色できるAI技術「LongAnimation」と、中国発オープンソースなマルチモーダル推論AI「GLM-4.1V-Thinking」をご紹介します。
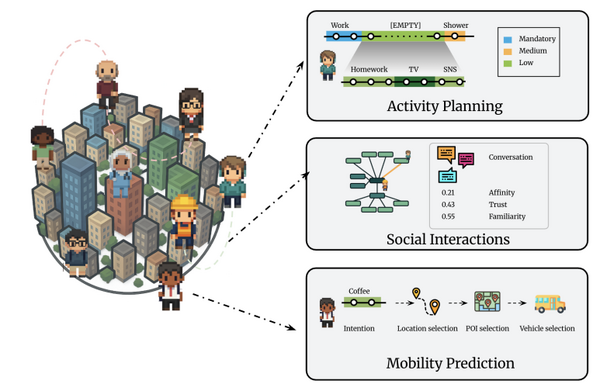
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、東京都市圏に人格を持ったAIエージェント1000体(最大100万体)を生活させた人間行動シミュレーターを別の単体記事で取り上げています。
Apple、コーディング生成AI技術「DiffuCoder」発表
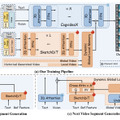
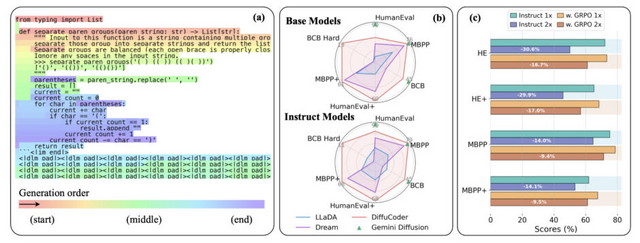
Appleと香港大学の研究チームが、プログラムコードを生成する新しいAI技術「DiffuCoder」を開発しました。DiffuCoderは1300億個のコードトークンを使って学習させた、70億パラメータのモデルです。
従来のAIがコードを左から右へ順番に生成するのに対し、DiffuCoderは画像生成AIで使われる拡散モデルを応用し、マスクで隠されたコード全体を徐々に明らかにしていく方法を採用しています。これにより、コード全体を計画し、繰り返し修正しながらより良いコードを作り出すことができます。
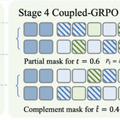
この知見を基に、研究チームは「coupled-GRPO」という新しい強化学習手法を提案しています。coupled-GRPOでは、相補的なマスクペアを用いることで、すべてのトークンが少なくとも一度は評価されることを保証しながら、より正確な確率推定を実現しています。
実験では、わずか2万1000サンプルでの追加学習により、コード生成精度が4.4%向上しました。
HumanEval、MBPP、BigCodeBenchなどの主要なコード生成ベンチマークにおいて、DiffuCoderは同規模の自己回帰モデルと競合する性能を示しています。特にQwen2.5-CoderやOpenCoderと同等の性能を達成しています。

DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation
Shansan Gong, Ruixiang Zhang, Huangjie Zheng, Jiatao Gu, Navdeep Jaitly, Lingpeng Kong, Yizhe Zhang
Paper | GitHub
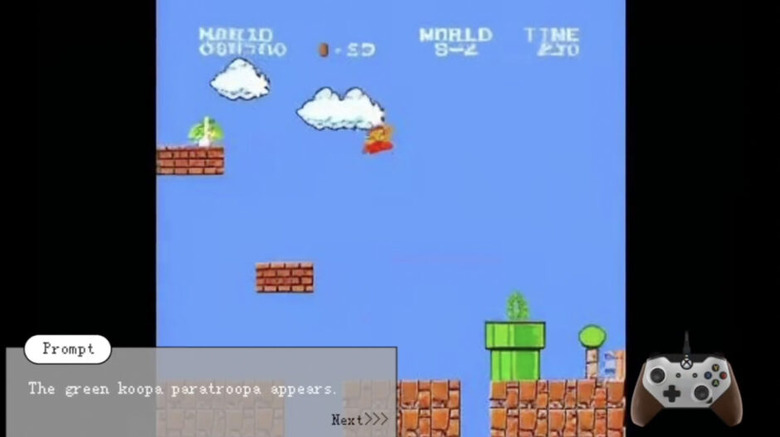
プレイしながらプロンプトでゲーム世界をリアルタイム生成していくAIゲームエンジン「Mirage」
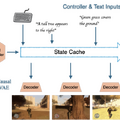
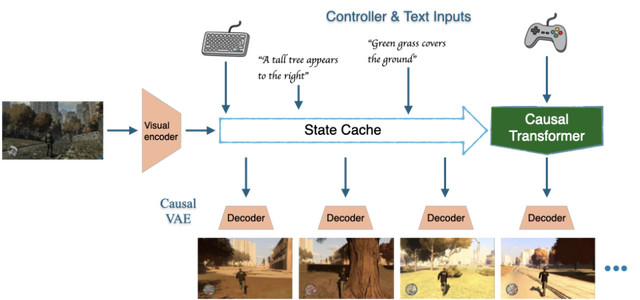
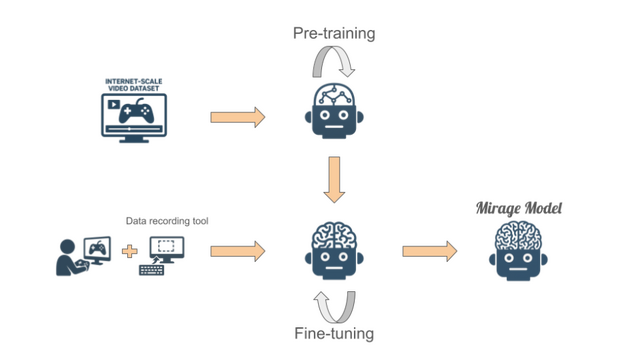
Dynamics Labがユーザー生成コンテンツ(UGC)AIゲームエンジン「Mirage」を発表しました。このエンジンは、プレイヤーが自然言語やコントローラー入力でリアルタイムにゲーム世界を生成・変更できるシステムです。
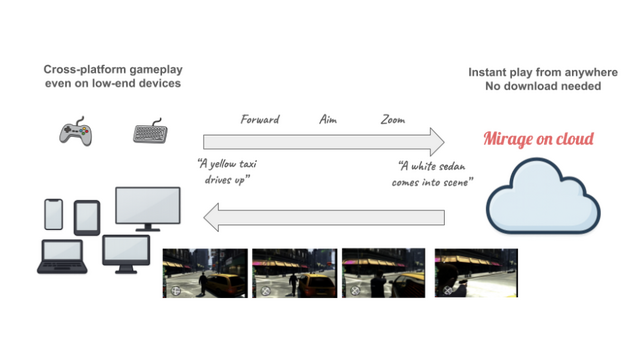
従来のゲームとは異なり、Mirageではプレイ中に「雨を降らせて」「逃走用の路地を作って」「車を出現させて」といった指示を入力するだけで、ゲーム世界が瞬時に変化します。
技術的には、大規模なトランスフォーマーベースの自己回帰拡散モデルを採用し、GoogleのAI DoomやGenie、DecartのAI Minecraft、MicrosoftのAI Quake IIの先行研究を超える優位性を持っています。例えば、ゲームプレイ中のテキスト入力によるUGC、より写実的なビジュアル、そして10分以上の長時間プレイが可能な点です。
開発チームはGoogle、NVIDIA、Amazon、SEGA、Apple、Microsoftなどの大手企業出身者で構成され、インターネットから収集した大規模なゲームデータと人間のプレイデータを組み合わせて、ゲーム専用のAIモデルを訓練しました。現在は16FPSでクラウドストリーミング経由でプレイ可能で、どのデバイスからでも即座にアクセスできます。
Mirageは現在リサーチプレビュー段階にあり、GTAスタイルの「Urban Chaos」とレーシングゲーム「Coastal Drift」のデモをご利用いただけます。
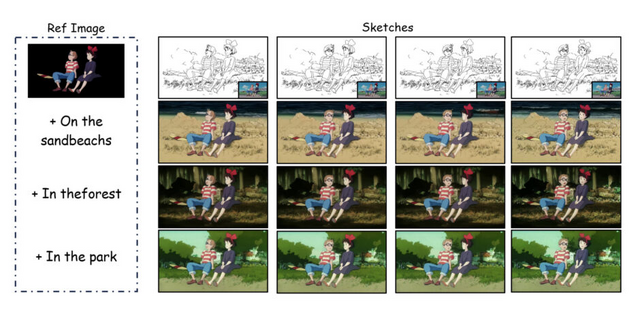
平均500フレームの長時間アニメーション自動着色ができるAI技術「LongAnimation」
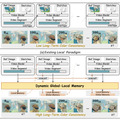
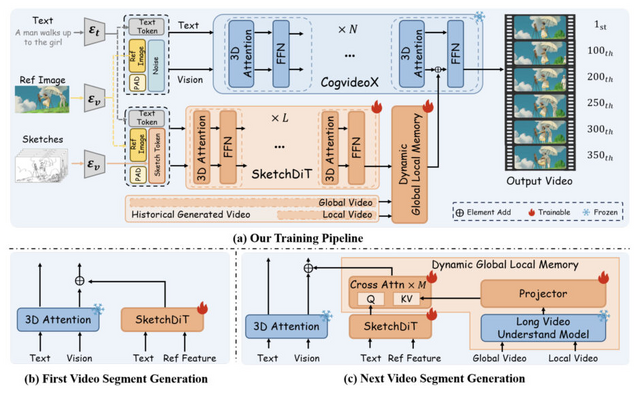
中国科学技術大学と香港科技大学の研究チームが、DiT(Diffusion Transformer)をベースにした長時間アニメーションの自動着色技術「LongAnimation」を開発しました。
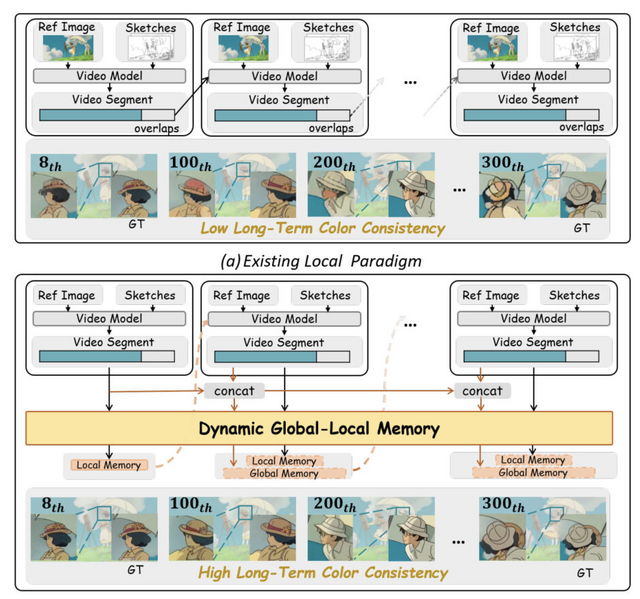
アニメーション制作において、300~1000フレームに及ぶ長時間シーケンスの着色は非常に労力を要する作業です。従来の手法では100フレーム程度が限界で、それ以上になると色の一貫性が保てず、キャラクターの帽子の色が途中で変わってしまうなどの問題がありました。
LongAnimationは「Dynamic Global-Local Memory」(DGLM)という新しいアプローチを採用し、過去の生成結果から色の特徴を動的に抽出して現在の生成に活用します。これにより、平均500フレームという長時間にわたって色の一貫性を維持できるようになりました。
実験では、長時間アニメーション着色においてフレーム類似性で58.0%、ビデオ品質で49.1%という大幅な改善を達成しました。また、テキストガイドによる背景生成機能も備えており、従来手法では不可能だった複雑な制御も実現しています。
LongAnimation: Long Animation Generation with Dynamic Global-Local Memory
Nan Chen, Mengqi Huang, Yihao Meng, Zhendong Mao
Project | Paper | GitHub
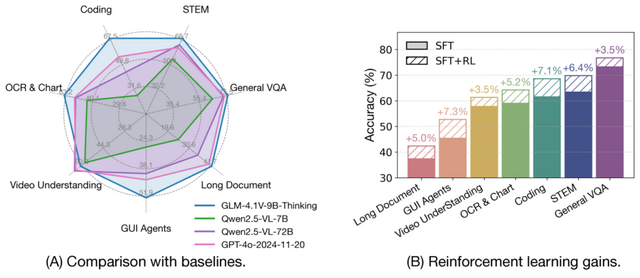
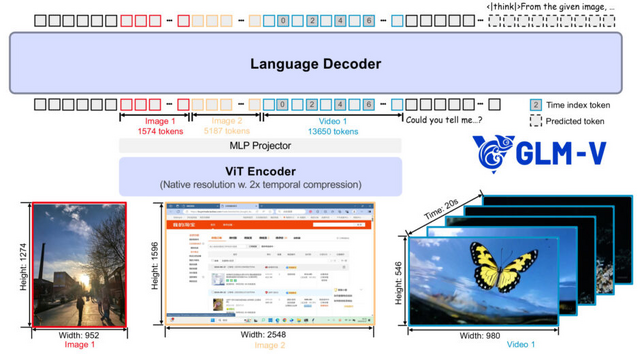
90億パラメータで720億レベル、中国発オープンソースなマルチモーダル推論AI「GLM-4.1V-Thinking」
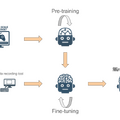
Zhipu AIと清華大学の研究チームが開発した「GLM-4.1V-Thinking」は、マルチモーダル推論に特化したオープンソース視覚言語モデルです。90億パラメータという中規模でありながら、720億パラメータの大規模モデルを超える性能を実現しています。
このモデルは推論中心のトレーニングフレームワークが特徴で、大規模な事前学習で強固な基盤を構築後、「Reinforcement Learning with Curriculum Sampling」(RLCS)という新手法を適用しました。RLCSは、モデルの現在の能力に応じて学習サンプルの難易度を動的に調整し、最も効率的な学習を可能にします。
性能面では、28の公開ベンチマークで評価を実施し、GLM-4.1V-9B-Thinkingは特に長文書理解、GUIエージェントタスク、コーディングにおいて、Qwen2.5-VL-72Bを大幅に上回りました。GPT-4oと比較しても、長文文書理解やSTEM推論といった高難度タスクにおいて競争力のある性能を示しています。

GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
GLM-V Team: Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, Shuaiqi Duan, Weihan Wang, Yan Wang, Yean Cheng, Zehai He, Zhe Su, Zhen Yang, Ziyang Pan, Aohan Zeng, Baoxu Wang, Boyan Shi, Changyu Pang, Chenhui Zhang, Da Yin, Fan Yang, Guoqing Chen, Jiazheng Xu, Jiali Chen, Jing Chen, Jinhao Chen, Jinghao Lin, Jinjiang Wang, Junjie Chen, Leqi Lei, Letian Gong, Leyi Pan, Mingzhi Zhang, Qinkai Zheng, Sheng Yang, Shi Zhong, Shiyu Huang, Shuyuan Zhao, Siyan Xue, Shangqin Tu, Shengbiao Meng, Tianshu Zhang, Tianwei Luo, Tianxiang Hao, Wenkai Li, Wei Jia, Xin Lyu, Xuancheng Huang, Yanling Wang, Yadong Xue, Yanfeng Wang, Yifan An, Yifan Du, Yiming Shi, Yiheng Huang, Yilin Niu, Yuan Wang, Yuanchang Yue, Yuchen Li, Yutao Zhang, Yuxuan Zhang, Zhanxiao Du, Zhenyu Hou, Zhao Xue, Zhengxiao Du, Zihan Wang, Peng Zhang, Debing Liu, Bin Xu, Juanzi Li, Minlie Huang, Yuxiao Dong, Jie Tang
Paper | GitHub