






この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第100回)では、ByteDanceから発表された3つの技術と、Appleの新たな画像生成AIをご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、オープンウェイトの大規模言語モデル(LLM)が著作権のある書籍をどの程度記憶し、再現できるかを定量的に検証した研究を別で単体記事として取り上げています。

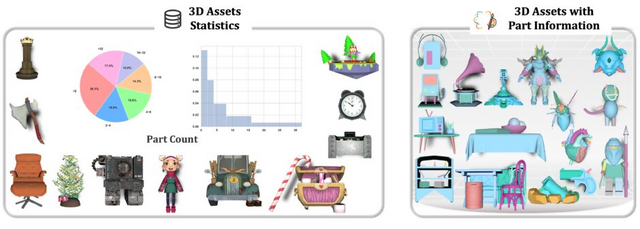
1枚の画像から複数の3Dパーツを同時生成するAIモデル「PartCrafter」
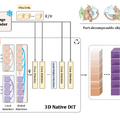
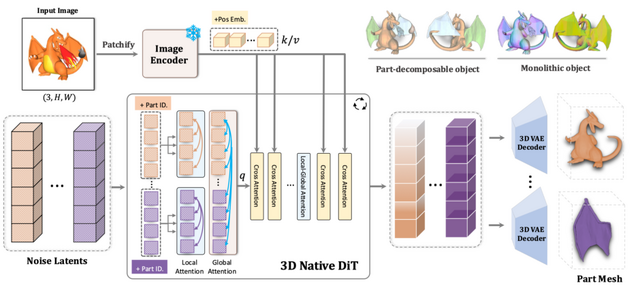
北京大学、ByteDance、カーネギーメロン大学の研究チームが開発した「PartCrafter」は、単一のRGB画像から複数の意味のある3Dパーツを同時に生成できる技術です。
従来の手法では画像を事前にセグメント化してから各部分を3D化する必要がありましたが、PartCrafterは統一されたアーキテクチャにより、この2段階プロセスを不要にしました。例えば、ハサミの画像を入力すると、2つの刃を別々のパーツとして認識し、それぞれを独立した3Dメッシュとして生成します。
技術的には、事前学習済みの3D拡散モデルをベースに、各パーツを独立した潜在トークンで表現し、階層的アテンションメカニズムで個々のパーツと全体の一貫性を保ちます。これにより、入力画像に見えていない部分も推論して生成することが可能です。
実験では既存手法と比較して優れた生成品質と効率を実証しました。特に、オクルージョンが激しいシーンでも高品質な3D生成が可能で、元となった3Dオブジェクト生成モデルよりも高い再構築精度を達成しています。

PartCrafter: Structured 3D Mesh Generation via Compositional Latent Diffusion Transformers
Yuchen Lin, Chenguo Lin, Panwang Pan, Honglei Yan, Yiqiang Feng, Yadong Mu, Katerina Fragkiadaki
Project | Paper | GitHub
Veo 3やKling 2.0、Soraを超えるByteDanceの最新動画生成AIモデル「Seedance 1.0」
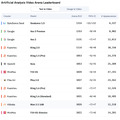
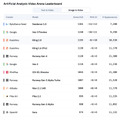
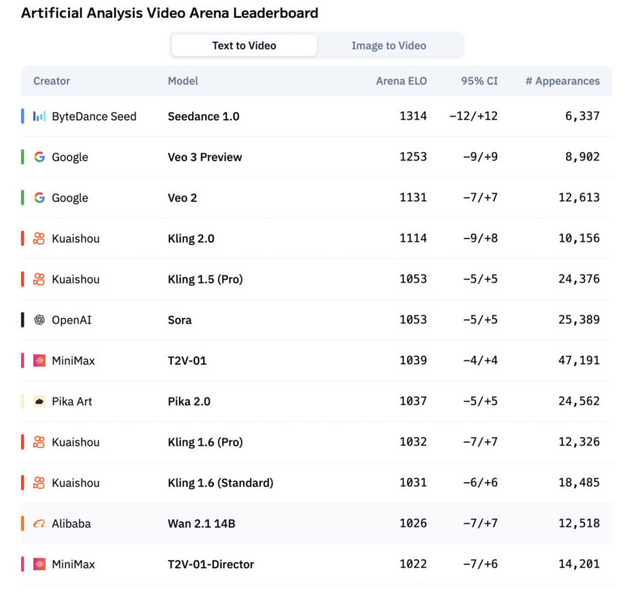
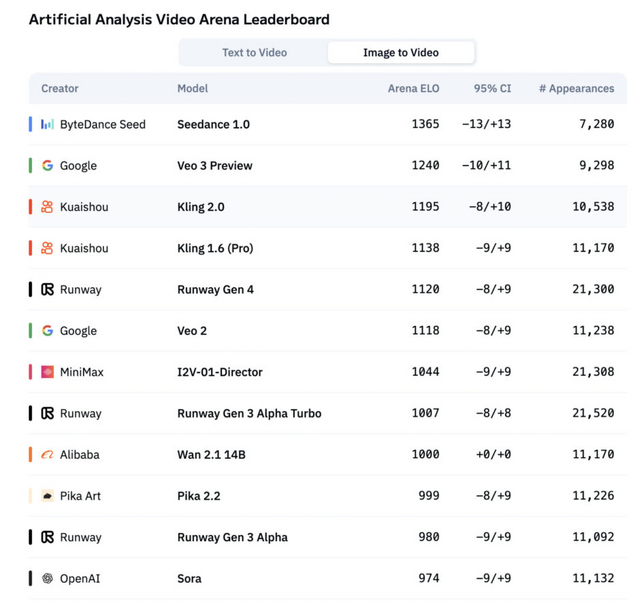
ByteDanceは最新の動画生成モデル「Seedance 1.0」を発表しました。このモデルは、テキストから動画を生成するT2Vと画像から動画を生成するI2Vの両タスクにおいてリーダーボードでトップの座を獲得しています。
Seedance 1.0の特徴は、1080p解像度の5秒動画をわずか41.4秒で生成できる高速性です(NVIDIA-L20使用時)。これは従来の商用モデルと比較して推論速度が10倍以上向上しています。
技術面では、大規模な動画データセットと精密なキャプショニングシステム、空間層と時間層を分離した効率的なアーキテクチャ、人間のフィードバックを用いた強化学習(RLHF)、そして多段階蒸留による推論高速化という4つの技術を統合しています。
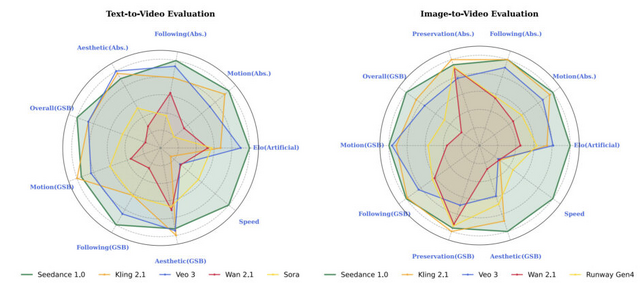
評価プラットフォームArtificial Analysis Arenaにおいて、Seedance 1.0はT2VとI2Vの両リーダーボードで首位を獲得しました。特にI2Vタスクでは、2位のVeo 3モデルを100ポイント以上引き離す圧倒的な性能を示しています。


Seedance 1.0: Exploring the Boundaries of Video Generation Models
Yu Gao, Haoyuan Guo, Tuyen Hoang, Weilin Huang, Lu Jiang, Fangyuan Kong, Huixia Li, Jiashi Li, Liang Li, Xiaojie Li, Xunsong Li, Yifu Li, Shanchuan Lin, Zhijie Lin, Jiawei Liu, Shu Liu, Xiaonan Nie, Zhiwu Qing, Yuxi Ren, Li Sun, Zhi Tian, Rui Wang, Sen Wang, Guoqiang Wei, Guohong Wu, Jie Wu, Ruiqi Xia, Fei Xiao, Xuefeng Xiao, Jiangqiao Yan, Ceyuan Yang, Jianchao Yang, Runkai Yang, Tao Yang, Yihang Yang, Zilyu Ye, Xuejiao Zeng, Yan Zeng, Heng Zhang, Yang Zhao, Xiaozheng Zheng, Peihao Zhu, Jiaxin Zou, Feilong Zuo
Project | Paper
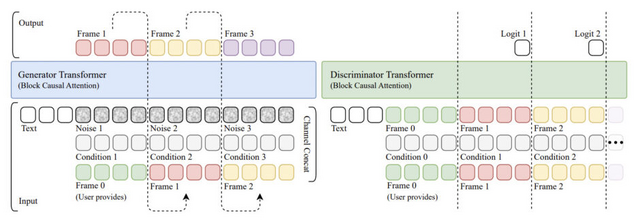
リアルタイムにインタラクティブ動画を生成し続けるAIモデルへ変換させる技術「AAPT」をByteDanceが開発
従来の動画生成モデルは、高品質な映像を生成できる一方で、計算量が非常に多く、リアルタイムアプリケーションへの適用が困難でした。例えば、数秒の高解像度ビデオを生成するのに数分かかることも珍しくありません。このような制約により、インタラクティブなゲームエンジンやワールドシミュレーターとしての活用は大きく制限されていました。
ByteDance Seedの研究チームは、リアルタイムでインタラクティブなビデオ生成を可能にする手法「AAPT」(Autoregressive Adversarial Post-Training)を発表しました。AAPTの最大の特徴は、その圧倒的な速さです。1枚の画像から始めて、次々とフレームを生成し、滑らかな動画を作り出します。
80億パラメータのモデルが単一のH100 GPUで736×416解像度、24fpsのリアルタイムビデオ生成を実現しています。8台のH100 GPUを使用すれば、1280×720解像度での生成も可能です。レイテンシはわずか0.16秒で、最大60秒(1440フレーム)の連続したビデオストリームを生成できます。

Autoregressive Adversarial Post-Training for Real-Time Interactive Video Generation
Shanchuan Lin, Ceyuan Yang, Hao He, Jianwen Jiang, Yuxi Ren, Xin Xia, Yang Zhao, Xuefeng Xiao, Lu Jiang
Project | Paper
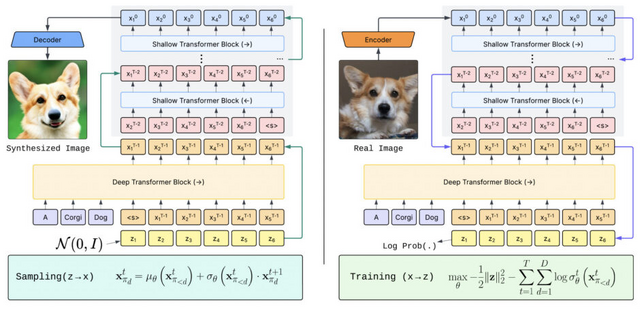
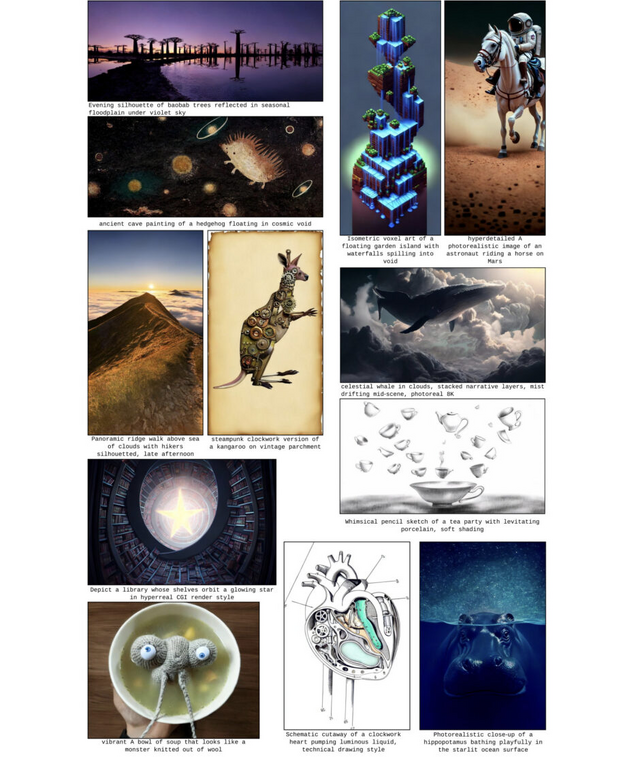
Apple、新たな方式の画像生成AI「STARFlow」を発表
Appleが新しい画像生成AI「STARFlow」を発表しました。これは、テキストから高品質な画像を生成できる38億パラメータの大規模モデルです。
STARFlowの特徴は、「正規化フロー」(Normalizing Flows)という技術を使っている点です。正規化フローは、単純な確率分布から複雑なデータ分布への可逆的な変換を学習する手法で、理論的に優れた性質を持ちながらも、これまで大規模な画像生成への応用は限定的でした。これまでの画像生成AIは「拡散モデル」や「自己回帰モデル」を使っていましたが、STARFlowは異なるアプローチで同等以上の品質を実現しています。
また技術的な特徴として、TARFlow(Transformer Autoregressive Flow)と呼ばれる手法を拡張し取り入れました。これは、強力なTransformerアーキテクチャと自己回帰型フローを融合したもので、画像の生成過程における一貫性を保ちながら高い表現力を実現します。
STARFlowでは、このTARFlowを基盤としつつ、最初に複雑な処理を行う深い層と、その後の微調整を行う浅い層を組み合わせることで、効率と品質の両立を実現しました。
ImageNetデータセットでの評価では、FIDスコア2.40(256×256解像度)および3.00(512×512解像度)を達成し、最先端の拡散モデルや自己回帰モデルと競合する性能を示しました。

STARFlow: Scaling Latent Normalizing Flows for High-resolution Image Synthesis
Jiatao Gu, Tianrong Chen, David Berthelot, Huangjie Zheng, Yuyang Wang, Ruixiang Zhang, Laurent Dinh, Miguel Angel Bautista, Josh Susskind, Shuangfei Zhai
Paper

















