




この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第105回)は、脳を読み取って画像を編集できるAI技術「LoongX」や、大規模言語モデルを3分の1に小型化し推論速度2倍を実現する技術「MoR」を取り上げます。
またロボットが実世界を「見て、考え、行動する」を実現するAIモデル「RoboBrain 2.0」や、写真1枚から重さや素材、動く仕組みなどの物理法則まで再現する3D生成AI「PhysX」をご紹介します。
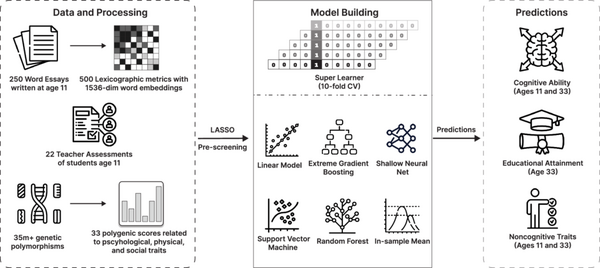
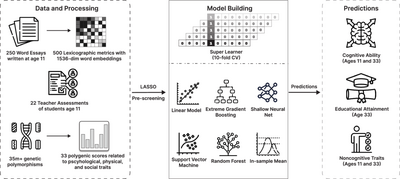
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、子どもが11歳のときに書いた短い作文から、その子の認知能力や将来の最終学歴をAIが予測できるかを調査した研究を別の単体記事で取り上げています。
脳波を読み取り、手を使わず画像編集できるAI技術「LoongX」
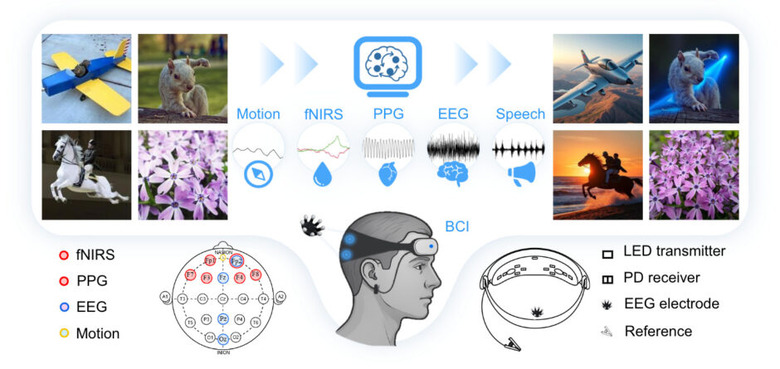
脳波を読み取って画像を編集できるAI技術「LoongX」が開発されました。シンガポール国立大学などの研究チームが発表したこのシステムは、手を使わずに思い通りの画像編集を可能にします。
LoongXは脳波(EEG)、近赤外分光法(fNIRS)、脈波(PPG)などの生体信号を読み取ることで、ユーザーの意図を理解します。研究では12名の参加者から2万3928組の画像編集データと生体信号を収集し、Diffusion Transformer(DiT)モデルの学習に使用しました。
実験の結果、生体信号のみでもテキスト入力による従来手法と同等の編集性能を達成しました。さらに生体信号と音声を組み合わせることで、テキストのみの方法を上回る精度を実現しています。
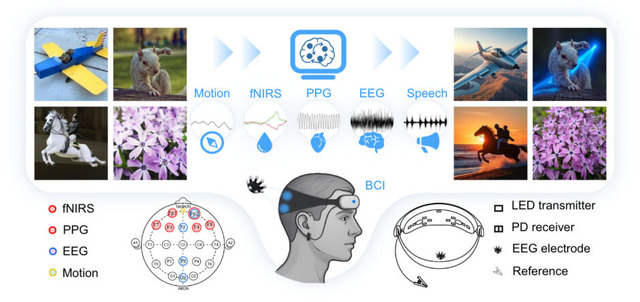
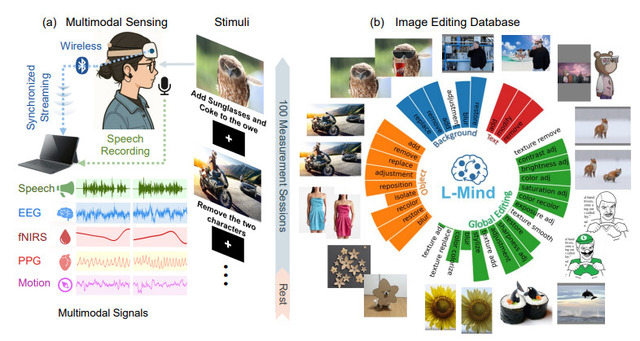
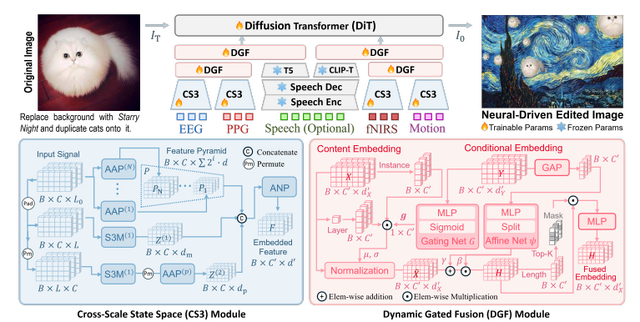
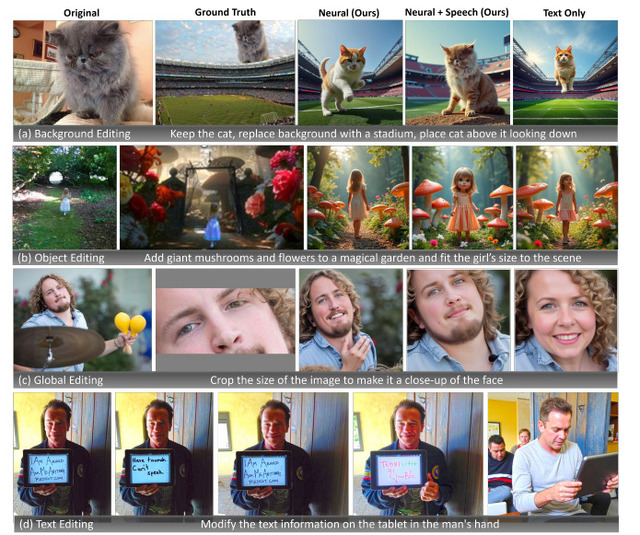
Neural-Driven Image Editing
Pengfei Zhou, Jie Xia, Xiaopeng Peng, Wangbo Zhao, Zilong Ye, Zekai Li, Suorong Yang, Jiadong Pan, Yuanxiang Chen, Ziqiao Wang, Kai Wang, Qian Zheng, Xiaojun Chang, Gang Pan, Shurong Dong, Kaipeng Zhang, Yang You
Project | Paper | GitHub
ロボットが実世界を「見て、考え、行動する」を実現するAIモデル「RoboBrain 2.0」
北京智源人工智能研究院(BAAI)の研究チームが、物理世界でロボットが見て、考え、行動することを可能にするAIモデル「RoboBrain 2.0」を発表しました。
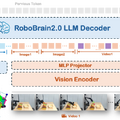
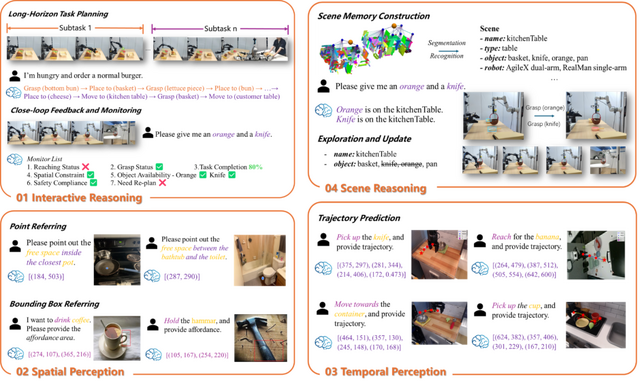
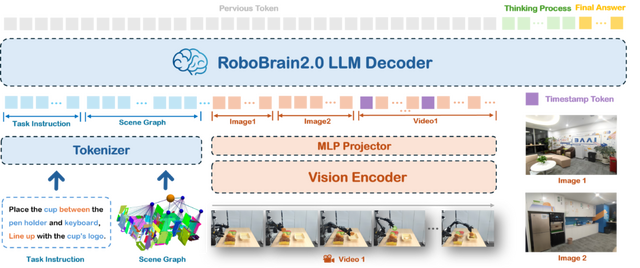
RoboBrain 2.0は、視覚と言語を統合した基盤モデルで、複雑な物理環境での知覚、推論、計画を処理できます。軽量版の7Bパラメータモデルと、フルスケール版の32Bパラメータモデルの2つのバリエーションが用意されています。
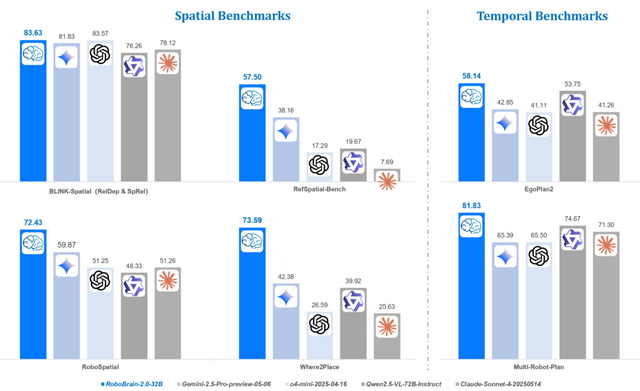
このモデルは、空間理解と時間的推論の両面で優れた性能を発揮します。空間理解では、物体の機能性を理解するアフォーダンス予測、複雑な指示から正確な位置を特定する空間認識、将来の動きを予測する軌道生成などが可能です。
時間的推論では、長期的な計画立案、複数のロボットの協調動作、リアルタイムのフィードバックに基づく行動調整などを実現します。
実際の応用例として、レストランでのハンバーガー調理と配膳、家庭でのオレンジとナイフの取り出し、スーパーマーケットでのギフト選択と包装など、複数のロボットが協調して作業を行うシナリオが示されています。

RoboBrain 2.0 Technical Report
BAAI RoboBrain Team: Mingyu Cao, Huajie Tan, Yuheng Ji, Minglan Lin, Zhiyu Li, Zhou Cao, Pengwei Wang, Enshen Zhou, Yi Han, Yingbo Tang, Xiangqi Xu, Wei Guo, Yaoxu Lyu, Yijie Xu, Jiayu Shi, Mengfei Du, Cheng Chi, Mengdi Zhao, Xiaoshuai Hao, Junkai Zhao, Xiaojie Zhang, Shanyu Rong, Huaihai Lyu, Zhengliang Cai, Yankai Fu, Ning Chen, Bolun Zhang, Lingfeng Zhang, Shuyi Zhang, Dong Liu, Xi Feng, Songjing Wang, Xiaodan Liu, Yance Jiao, Mengsi Lyu, Zhuo Chen, Chenrui He, Yulong Ao, Xue Sun, Zheqi He, Jingshu Zheng, Xi Yang, Donghai Shi, Kunchang Xie, Bochao Zhang, Shaokai Nie, Chunlei Men, Yonghua Lin, Zhongyuan Wang, Tiejun Huang, Shanghang Zhang
Project | Paper | GitHub
LLMを3分の1に小型化し推論速度2倍を実現した、韓国KAISTやGoogle参画の新技術「MoR」
大規模言語モデル(LLM)は優れた性能を持ちますが、その巨大さゆえに膨大な計算資源を必要とします。この問題を解決するため、韓国のKAISTやGoogleなどの研究チームが「Mixture-of-Recursions」(MoR)という技術を開発しました。
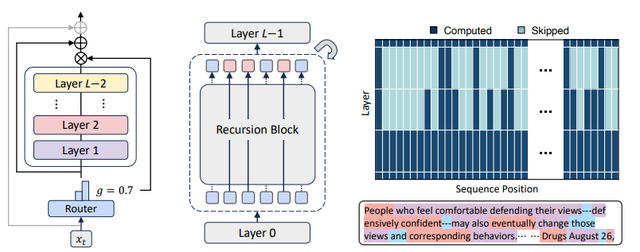
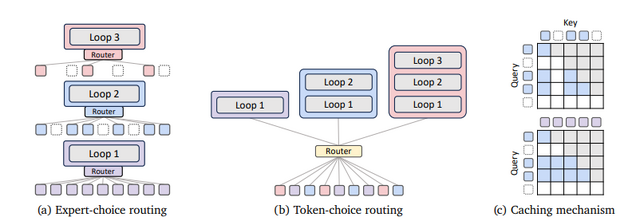
MoRはTransformerモデルの性能を維持しながら、必要な計算資源を削減するアプローチです。従来のLLMは、すべての入力トークンに対して同じ量の計算を行っていましたが、MoRは各トークンの複雑さに応じて異なる深さの処理を動的に割り当てます。
例えば「the」や「and」のような簡単な単語と、専門用語や文脈に依存する複雑な単語では、理解に必要な処理の深さが異なります。MoRは各単語の難しさを自動的に判断し、簡単な単語は素早く処理し、複雑な単語により多くの計算時間を割り当てます。
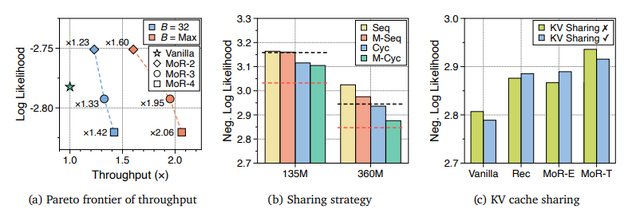
技術的には、同じ処理ブロックを繰り返し使うことでパラメータ数を削減し、さらに各単語に必要な繰り返し回数を動的に調整します。これにより、従来のモデルと比べてパラメータ数を約3分の1に削減しながら、同等以上の性能を実現しています。
実験において様々なサイズのモデル(135Mから1.7Bパラメータ)で検証した結果、MoRは少ないパラメータと計算量で従来モデルを上回る精度を達成しました。推論速度も最大2倍以上向上しました。
Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation
Sangmin Bae, Yujin Kim, Reza Bayat, Sungnyun Kim, Jiyoun Ha, Tal Schuster, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Aaron Courville, Se-Young Yun
Paper | GitHub
写真1枚から重さや素材、動く仕組みなどの物理法則まで再現する3D生成AI「PhysX」
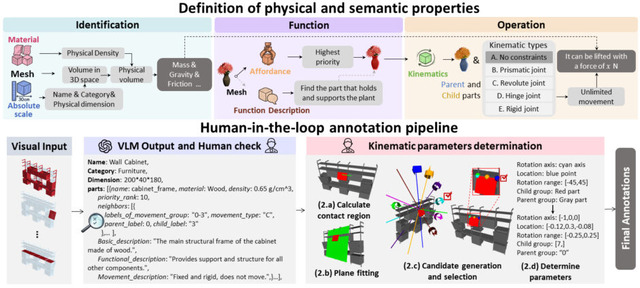
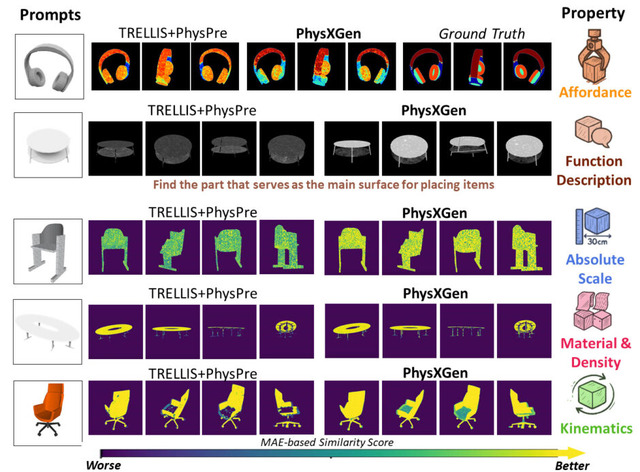
「PhysX」は、物理的に正確な3Dモデルを自動生成するAI技術です。これまでの3D生成技術は見た目だけを作っていましたが、PhysXは材質や密度、動く仕組みなどの物理法則まで含めた本物そっくりの3Dモデルを作ることができます。
従来の3D生成技術は、主に形状やテクスチャなどの外観に焦点を当てていました。しかし、シミュレーションやロボット工学などの実世界応用では、物体の重量や材質、可動部分の動作範囲といった物理的特性が不可欠です。
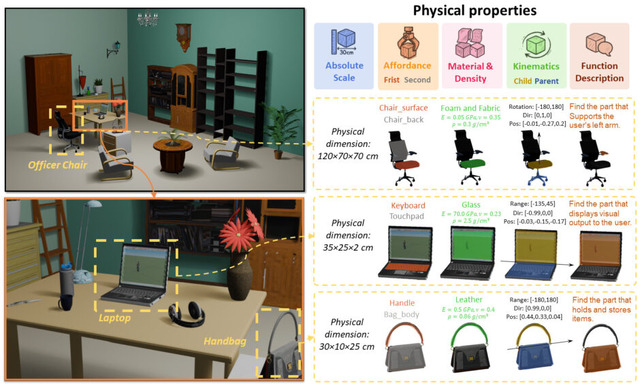
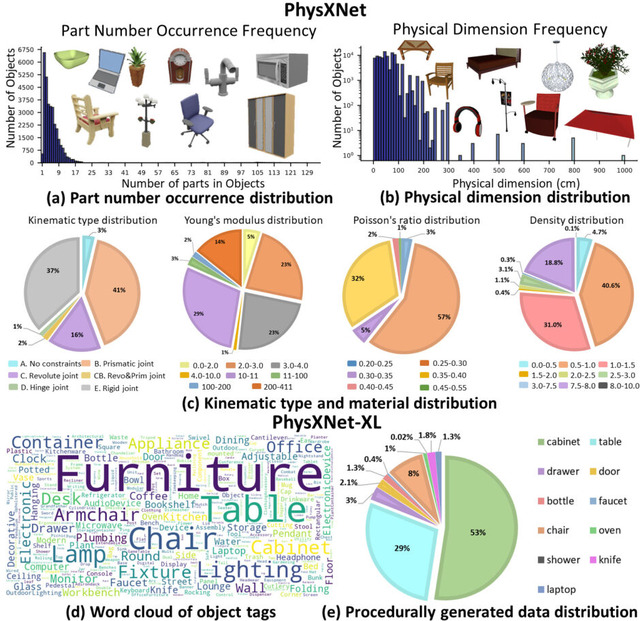
研究チームは、26,000個以上の3Dオブジェクトに詳細な物理的アノテーションを施した「PhysXNet」データセットを構築しました。各オブジェクトには、実際の寸法、材質情報、使用時の接触優先度を示すスコア、可動部分の動作制約、そして各パーツの機能説明が含まれています。
このデータセットを用い、事前学習済みの3D生成モデルを基盤とした生成フレームワーク「PhysXGen」で学習します。これにより、単一の画像を入力として、その物体の3D形状だけでなく、各パーツの材質や可動範囲まで予測することが可能になります。
PhysX: Physical-Grounded 3D Asset Generation
Ziang Cao, Zhaoxi Chen, Linag Pan, Ziwei Liu
Project | Paper | GitHub