

この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第115回)は、人脳の神経回路を模倣した言語モデル「Dragon Hatchling」や、リアルタイムに指示して途中で変更しながら長時間動画を生成するAI「LONGLIVE」を取り上げます。
また、言語モデルが4桁×4桁の掛け算ができない現象を解明した論文や、動画から実世界の複雑なタスクを学習するGoogle開発の世界モデルベースのAIエージェント「Dreamer 4」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、OpenAIの動画生成AI「Sora 2」を悪用する動きを別の単体記事で取り上げています。
脳の神経回路を真似てニューロンとシナプスみたいに動作する言語モデル「Dragon Hatchling」
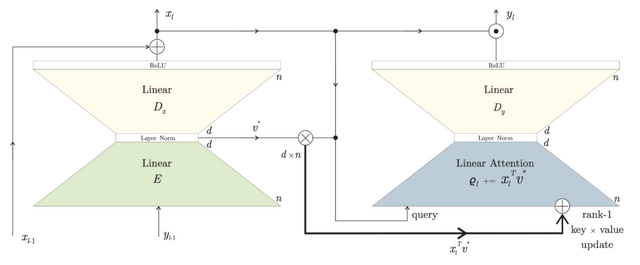
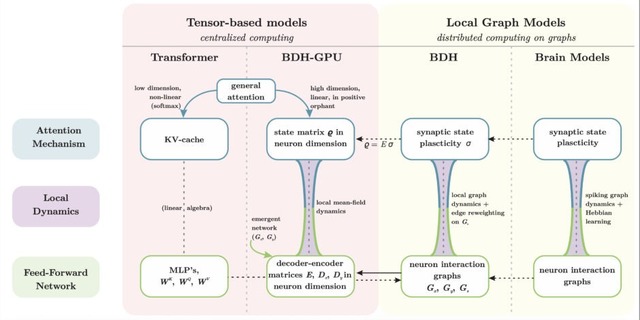
脳の神経回路を模倣した新しい言語モデル「Dragon Hatchling」(BDH)が発表されました。従来のAIモデルは数学的な行列演算で動作していましたが、BDHは脳と同じように個々のニューロンが互いに信号をやり取りする仕組みで動きます。
このモデルでは、数万から数百万個の人工ニューロンがシナプスと呼ばれる接続部分を通じて情報を交換します。よく使われる接続は自動的に強化されるという脳の学習原理(ヘッブの法則)を採用しています。
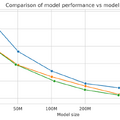
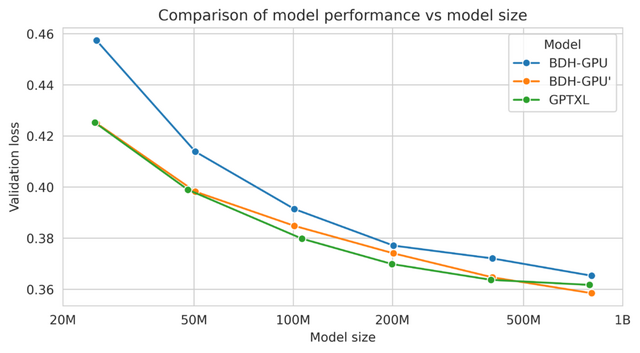
性能面では、BDHはGPT2アーキテクチャのTransformerと同等の言語処理能力を示しました。1000万から10億パラメータまでのスケールにおいて、文章生成や翻訳タスクで競合する性能を達成しました。
BDHは訓練を通じて自然に脳のような構造を獲得します。例えば、ヨーロッパ議会の議事録で訓練したモデルは、「通貨」や「国名」といった概念が文章に現れると、それに対応する特定のシナプスが活性化することが確認されました。
さらに、約5%のニューロンのみが各トークンで活性化される動作は、脳のエネルギー効率的な情報処理と酷似しています。

The Dragon Hatchling: The Missing Link between the Transformer and Models of the Brain
Adrian Kosowski, Przemysław Uznański, Jan Chorowski, Zuzanna Stamirowska, Michał Bartoszkiewicz
Project | Paper | GitHub
リアルタイムに指示し、途中で変更しながら長時間動画を生成するAI「LONGLIVE」をNVIDIAなどが開発
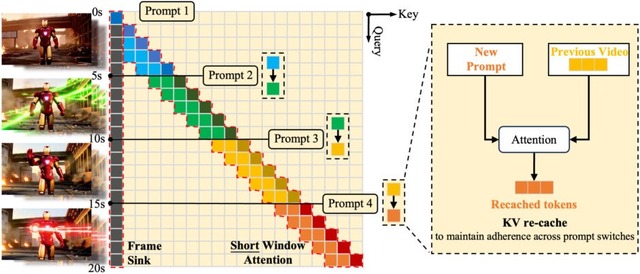
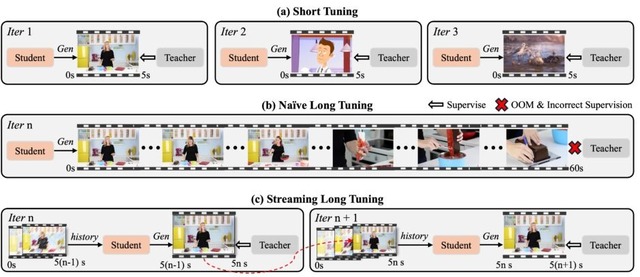
NVIDIAやMIT、香港科技大学などの研究チームが、リアルタイムでインタラクティブな長時間動画生成を可能にするAIフレームワーク「LONGLIVE」を発表しました。
従来の動画生成AIは、長時間の動画を作成する際に品質の低下や計算時間の増大という課題を抱えていました。特に、ユーザーがリアルタイムで指示を変更しながら動画を生成することは困難でした。
LONGLIVEでは、ユーザーが途中でプロンプトを変更しても、視覚的な一貫性を保ちながらスムーズに新しい指示に従うことができます。また独自の学習手法により、長時間動画でも品質を維持できるようになりました。
性能評価では、13億パラメータのモデルをわずか32GPU日でファインチューニングでき、最大240秒(4分)の動画生成が可能、推論時にはNVIDIA H100 GPU1台で毎秒20.7フレームという高速処理を実現しています。



LongLive: Real-time Interactive Long Video Generation
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, Song Han, Yukang Chen
Paper | GitHub
Google DeepMind、動画から複雑なタスクを学習する世界モデルベースのAIエージェント「Dreamer 4」発表
Google DeepMindが開発した「Dreamer 4」は、実際の環境とやり取りすることなく、録画された動画データのみから複雑なタスクを学習できる世界モデルを用いたAIエージェントです。世界モデルとは、AIエージェントに実世界を深く理解させ、将来の行動結果を予測する能力を与えるものです。
Dreamer 4では、高速かつ高精度な世界モデルを構築し、その内部でシミュレーションを行うことで、実際の環境で危険な試行錯誤をせずに行動戦略を学習できます。さらに、従来64ステップ必要だったビデオ生成処理を4ステップに削減し、単一GPU上でリアルタイム推論を実現しました。
Minecraftにおいて、Dreamer 4は2,541時間のゲームプレイ動画から学習し、環境との直接的なやり取りなしにダイヤモンド採掘に成功しました。この課題は2万回以上の操作が必要な長期的タスクです。
将来的には、インターネット上の膨大な動画から世界の物理法則やオブジェクト相互作用を学習し、実世界のタスクに応用できる可能性を示しています。

Training Agents Inside of Scalable World Models
Danijar Hafner, Wilson Yan, Timothy Lillicrap
Project | Paper
大規模言語モデルはなぜ「掛け算」が苦手なのかを米国の研究者らが解明
大規模言語モデル(LLM)は、複雑な推論や創造的な文章作成において驚異的な能力を示す一方で、4桁×4桁の掛け算のような一見単純な計算タスクではしばしば失敗します。この問題を、シカゴ大学やMITなどの研究者による共同チームが分析しました。
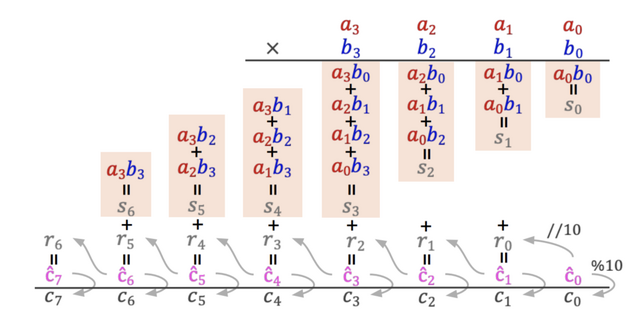
研究チームは、通常のファインチューニングで学習したモデルと、「Implicit Chain-of-Thought」(ICoT)と呼ばれる新しい手法で訓練したモデルを比較しました。ICoTは、訓練初期に計算の中間ステップを明示しながら学習し、その後徐々にそれらを削除していく段階的な訓練方式です。例えば、12×34を解く場合、最初は「12×4=48」「12×30=360」「48 + 360=408」のように部分積を明示的に示す形で学びます。
実験では、2層・4ヘッド構成の小型Transformerモデルが、ICoTで訓練した場合に4桁×4桁の掛け算で100%の精度を達成しました。対照的に、同じモデルを通常のファインチューニングだけで訓練した場合、精度は1%未満にとどまりました。
解析の結果、ICoTモデルは桁ごとの部分積や繰り上がりなど、桁をまたいだ関係を適切に表現できることがわかりました。一方で、通常のモデルは答えの最初や最後の桁は正しく出力できるものの、中間の桁では勾配が消失し、学習が停滞する傾向が見られました。
この理解を基に、計算途中を予測させる補助損失を導入する手法を提案し、ICoTを使わずとも99%の精度で掛け算を学習できることを示しました。
Why Can’t Transformers Learn Multiplication? Reverse-Engineering Reveals Long-Range Dependency Pitfalls
Xiaoyan Bai, Itamar Pres, Yuntian Deng, Chenhao Tan, Stuart Shieber, Fernanda Viégas, Martin Wattenberg, Andrew Lee
Paper