









Sora 2はおそろしくリアルな映像とサウンドの生成が可能です。特に、カメオ機能で自分自身として登録しているキャラクターについては、「@ユーザー名 が~している」で自由に映像生成できます。
しかし、キャラクターとして参照できる画像は、リアルな人物は弾かれてしまいます。イラストや彫像・塑像、3Dプリンタ声生物とはっきりわかるものは取り込みできますが、多くの場合、警告が出て、そのまま行ける場合もありますが、拒否されることもあるくらい、厳しい制限が課せられています。
筆者の場合、ピアノの鍵盤に指が写っているだけで「リアルな人物」として跳ねられたこともありました。生成AIでは鍵盤の黒鍵の数を必ず間違えるので、参照のために入れただけなのに……。

では、リアルな登場人物を固定して使いたい場合にはどうしたら良いのでしょうか?
筆者は、以前トライした、プロンプトでその人物の描写を再現可能なレベルまで詳しく記述する方法でやってみることにしました。
それが可能ではないかと思ったのは、Sora 2のプロンプトがかなりの長文を記述でき、追従性も高いからです。
同様の試みはVeo 3でやっていたのですがVeo 3はImage to Videoが使えるので必須ではない。それに対して、Sora 2は実写のImage to Videoが禁止されているので、プロンプトに頼らざるを得ないというわけです。

プロンプトだけで人物固定してみる
今回は、写真を読み込ませるマルチモーダルLLMとしては、ChatGPTを使いました。
妻の写真をもとにして生成したAI画像の中から、本人らしさをうまく表していそうなものをレファレンスにして、「この顔をSora 2で再現可能なレベルまでプロンプトに落とし込んで。英語と日本語、それぞれのバージョンを作成して」という指示を出しました。

ChatGPTが提案してきたプロンプトを使い、Sora 2で出してみましたが、微妙に意図したものと違います。

別の画像を参照してプロンプトの改良を図ります。

これでも本人に似てる感じにはならなかったので、生成された動画から静止画を切り出し、これと参照画像との差分を分析させました。

輪郭や目鼻などのパーツの違いをちゃんとわかっているようで、改良版が提案されました。
さらに参照画像を追加して、立体的な違和感を解消していきます。

結果として、日本語で850文字のプロンプトになりました。
英文プロンプトだと長くなりすぎて、Soraの文字数制限を超えてしまったので、プロンプトを圧縮してもらうことに。
日本語のプロンプトも400字前後まで圧縮できました。
しかし、鼻の高さや鼻梁の幅や鼻腔の横の膨らみなど、本人に似せられない部分がまだ残っています。
さらに参照画像を追加し、差分を分析させて改良させていきます。

ChatGPTは物理的な変更ではなく、ライティングで解決しようとしがちので、物理的に鼻の高さを2mm上げて、と指定してなんとか理想に近づけます。
こうした問題が発生する背景としては、Sora 2のプロンプト追従性がイマイチであることもあるようです。
同じプロンプトでもVeo 3ならば理想的な結果が出たりするので。
こうしてプロンプトを洗練させていく分けですが、最後は精神力で「目力」「鋭い視線」「強めの涙袋」といった、これまでのプロンプト歴で培ったキーワードが効いてきました。
まあ、日本語が使えるのは便利ですよね。
最終的にこんなプロンプトになりました。
東アジア系20代前半の女性。やや細めのオーバル顔、小さく丸い顎。
鼻筋は眉間から鼻先まで長く通り、滑らかで繊細なライン。鼻梁をやや狭くし、中心軸をわずかに高く(約2 mm程度の自然なリフト)して立体感を強調。
鼻腔の周囲はわずかにふっくらとして、鼻筋との段差を自然につなぐ。 鼻先は小さく丸く、鼻翼は控えめで均整のとれた形。
中~大のアーモンド形の瞳、目尻は水平~ごくわずかに上がる。虹彩は濃い茶で深みがあり、キャッチライトは小さく正確。
まぶたは浅い二重でなめらか。瞳孔は中心で安定し、視線には静かな意志と集中力。
目の奥にほのかな光を宿し、軽く細めたまなざしで知的な強さを感じさせる。
眉は中太でまっすぐ、外側で軽く上がる。
唇は自然なピンクで、上唇やや薄く下唇に柔らかな厚み。鼻下は短すぎず、自然な距離感。
肌は明るいニュートラルベージュ。頬にごく薄いそばかす。鼻梁から頬にかけて細いハイライトを入れ、立体感と柔らかさを両立。
髪は黒のセミウェーブ。厚めの前髪を中央で軽く分け、頬に沿って流れる。
加工なし。リアルで知的、鼻筋と視線の立体的な存在感が際立つポートレート。

50本以上の動画をSora 2で生成し、それを繋げてみました。
同じ絵ばかりでは芸がないので、フォーカスを当てる部分に変化をつけてみます。これには852話さんが紹介していたプロンプトテクニックを使いました。
タイムコードで記述する方法が知られているようですが、852話さんは「-」(ハイフン)で繋いでいくだけの超簡単なやり方を教えてくれたので、それに倣ってみました。
プロンプトをさらに追い込んでみます。
鼻梁の幅、高さ、そして目尻の角度などを数値化して調整していきます。ある程度できたところで、生成画像の出来栄えがかなり幅があるというか、ちょっとこれは似てなさすぎだろうというものが気になりだしました。
これは、Stable Diffusion使いはじめの頃に経験したことです。ベースモデルが端正な顔でないと、そこにいくら盛っても無理がある。
2年前は、ベースモデルとしてBRA(Beautiful Realistic Asian)を使うことで、品質を向上させることができました。今回は、プロンプトの中に、美人になるキーワードを入れておくことに。「アイドル」「女優」「タレント」とか「学内のアイドル」「人気の学生」といったものを片っ端から試して品質の向上を図ります。
ダメ押しとして、年代の指定を入れます。どうも違和感があったのは、目指す年代が現代の再現ではないからのようでした。メイクも顔の傾向も違う。ならば、年代を1980年代前半に指定し直してみました。
これでだいぶ向上し、目指す顔に近づいてきました。
しかしここでOpenAIからタオルが投げ込まれます。「24時間で100本以上のビデオを生成しているからこれ以上は無理ね。また時間をおいてやってみて」という警告が出て、いったん中止です。
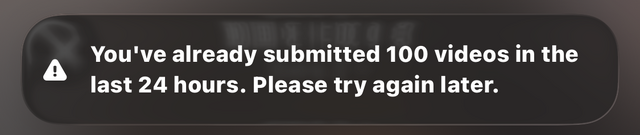
せっかくいいところまで行ったのに……。しかし、ここで助け舟が現れます。Sora 2のAPI開放です。
Sora 2のAPI開放で人物参照してImage to Videoができるようになる?
Sora 2のAPI開放はOpenAI DevDay 2025で発表されたもので、Sora 2で1秒あたり0.1ドルから。10秒1ドルで、ウォーターマークなしの映像を生成できるようになります。
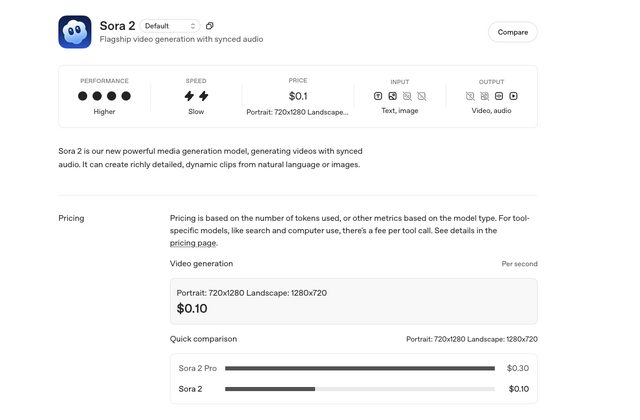
API Keyを使えば自分でプログラムを書くこともできるのですが、より手軽にAPIを利用できる方法があります。それは、いわゆるAIアグリゲーターサービスを使うことです。
AIアグリゲーターは、自社AIモデルのあるなしに関わらず、複数のAIモデルをユーザーが利用できるようにするサービスで、そのためのUIをWebサービスとして提供しているところです。最近ではHiggsfieldなどが人気のようですね。Higgsfieldでは期間限定でSora 2使い放題キャンペーンを実施しているようです。
筆者はAIアグリゲーターとしてPoeとWaveSpeedAIを使っています。まずはPoeから。ちゃんと生成できました。4、8、12秒の生成ができます。
 |  |  |  |
Sora 2 Proではアスペクト比で16:9と9:16だけでなく、7:4と4:7もサポートしています。長さは同じく4、8、12秒。長さだけでいうと、SoraアプリまたはサービスでProを使った方が長尺(15秒)が生成できることになります(ウォーターマークは入りますが)。
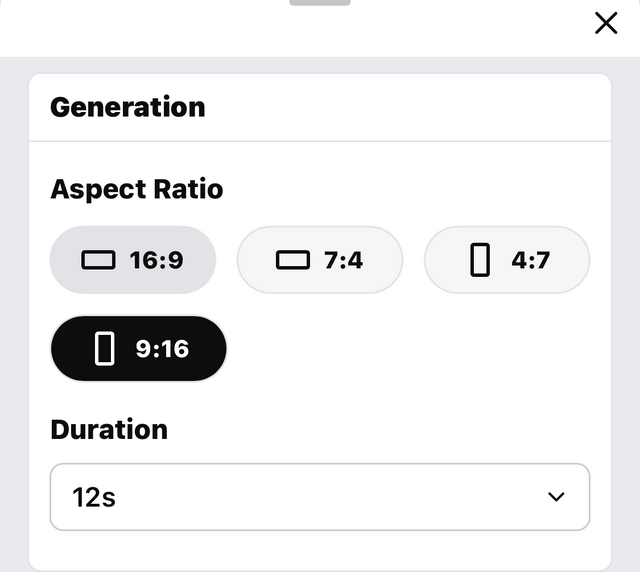
Poeでは画像の添付ができないので、WaveSpeedAIの方でも試しました。プロンプトと参照する画像添付をして実行を押すと……。
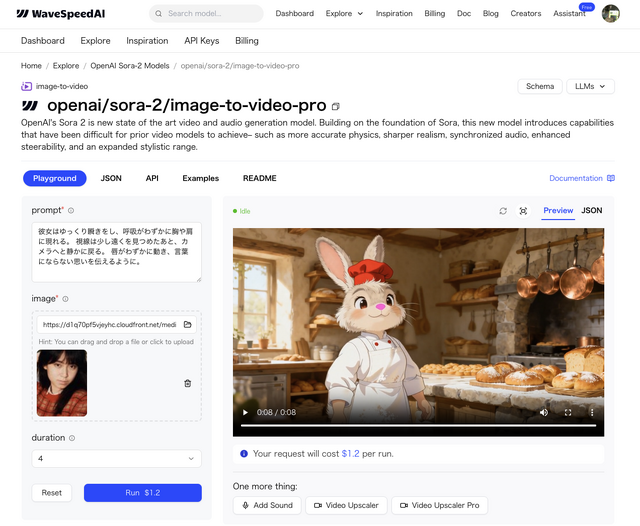
コンテンツチェッカーに引っかかり制限できません。API経由でも、リアルな人物の画像添付は禁じられているようです。

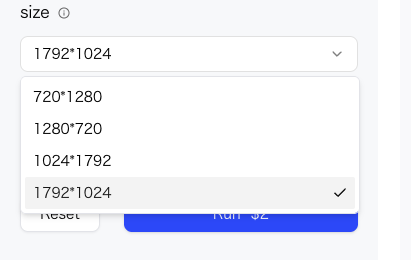
Sora 2 Proでも試してみました。最高解像度の1792×1024ピクセルでは、4秒で2ドルします。
というわけで、「リアルな人物写真・画像なしで、人物を固定する」という課題は当面、生き続けることになりそうです。
現時点では本人っぽいものが10回に1つ出るかどうかというレベルなので、さらに精進が必要ですね。
Grok Imagine v0.9登場
そこへxAIのGrok Imagineがv0.9にバージョンアップしました。映像・音声ともによくなったようです。動画生成AIのバトルフィールドは今も動き続けていて、Sora 2の天下も長くないかもしれません。
しかし、アプリで使うSora 2にはSNSで自分や知人・友人・著名人と共演できるという面白さがあり、その部分ではしばらく楽しめそうです。
Sora 2 Prompting Guideで最適化してみる
さらに、Sora 2 Prompting Guideという公式の指針が出たので、現時点での最新のプロンプトをChatGPTに最適化させたところ、かなり安定した生成ができるようになりました。今後はこれをベースに改良していこうと思います。

同一性についての一つの判断基準として、iOS写真アプリで、同一人物として扱われているか、というものがあります。
妻の名前のタグがついた画像・動画の中に、Sora 2で生成したものが2つ、入っていました。自分から見るともっと似ているものはあるのですが、それでも単なるText to Videoで本人として分類される画像になったというのは、ある程度のプロンプト最適化ができた、ということなのでしょう。
1日100本のSora 2生成ができるということは、8時間稼働するとして5分に1回生成して試せるということ。
言葉としてどう表現すると本人に近づけるかという課題は、もう少し遊んでいられそうです。

Sora 2 Proで、自分をカメオで共演させることにも成功しました。









![イヤホン 有線 [HIFI音質]イヤホン 有線 3.5mmジャック ノイズ低減 通話/音楽 音量調節対応 防水 通勤・会議・運動 | 原音再現 MFi認証 重低音 遅延なし コンパクト 軽量 インイヤー 人体工学 image](https://m.media-amazon.com/images/I/31CBe3mkz-L._SL160_.jpg)






