






この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第121回)は、大規模言語モデル(LLM)の文章生成を高速化するNVIDIA開発の技術「TiDAR」や、画像に長文テキストを隠して埋め込めるAIを用いたステガノグラフィー技術「S²LM」を取り上げます。
また、ByteDanceから2つ、ゲームAIエージェント「Lumine」と、画像から高精度な3D空間を復元するAI「Depth Anything 3」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、依頼主とクリエイターの直接取引で絵師を騙す、AIを用いた詐欺事案を別に単体記事で取り上げています。
AIが「原神」を56分でクリアする、ゲームAIエージェント「Lumine」をByteDanceが開発
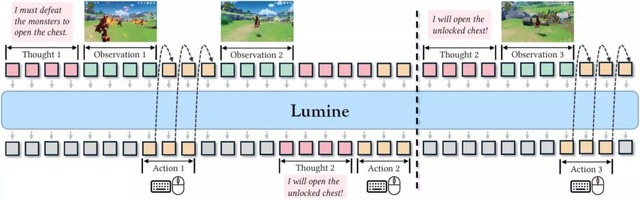
ByteDance Seedの研究チームは、3Dオープンワールドゲームで人間レベルのプレイを実現するAIエージェント「Lumine」を発表しました。これは、複雑な3D環境で数時間にわたるミッションをリアルタイムで完了できるAIシステムです。
Lumineは、Qwen2-VL-7Bベースモデルを基盤とし、ゲーム画面のピクセルデータから直接キーボードとマウスの操作を生成します。毎秒5回の頻度で画面を認識し、30Hzの精度でアクションを出力する仕組みです。必要に応じて内部で推論を行い、状況に適応的に対応する機能を備えています。
訓練には約2400時間の人間のゲームプレイデータを使用し、3段階の学習プロセスを経ています。まず1731時間のプレイデータで基本的な操作を学習し、次に200時間の指示追従データで言語による制御を可能にし、最後に15時間の推論データで長期的な計画能力を獲得しました。
評価実験では、Lumineは「原神」のモンドシュタット編メインストーリー第1章を56分で完了し、初心者プレイヤーの平均78分を上回り、熟練プレイヤーの平均53分に匹敵する成績を収めました。141個のタスクからなるベンチマークテストでも、全カテゴリーで80%以上の成功率を達成しています。
Lumineは、訓練に使用していない新しいゲームでも動作します。「鳴潮」では107分でメインミッションを完了し(人間の平均は101分)、「崩壊:スターレイル」では第1章全体を5時間でクリアしました(人間の平均は4.7時間)。これは、Lumineが単一のゲーム固有の動作を学習したのではなく、3Dナビゲーションや2D GUI操作といった汎用的なスキルを獲得したことを示しています。

Lumine: An Open Recipe for Building Generalist Agents in 3D Open Worlds
Weihao Tan, Xiangyang Li, Yunhao Fang, Heyuan Yao, Shi Yan, Hao Luo, Tenglong Ao, Huihui Li, Hongbin Ren, Bairen Yi, Yujia Qin, Bo An, Libin Liu, Guang Shi
Project | Paper
NVIDIAがLLMの文章生成を高速化する技術「TiDAR」を開発
NVIDIAの研究チームが、AIの文章生成を大幅に高速化する技術「TiDAR」を開発しました。
現在主流のAIは、文章を1トークンずつ順番に生成します。品質は高いのですが、最新のGPUの性能を十分に使い切れていません。一方、拡散言語モデルは並列生成が可能ですが、品質が低下する傾向があります。
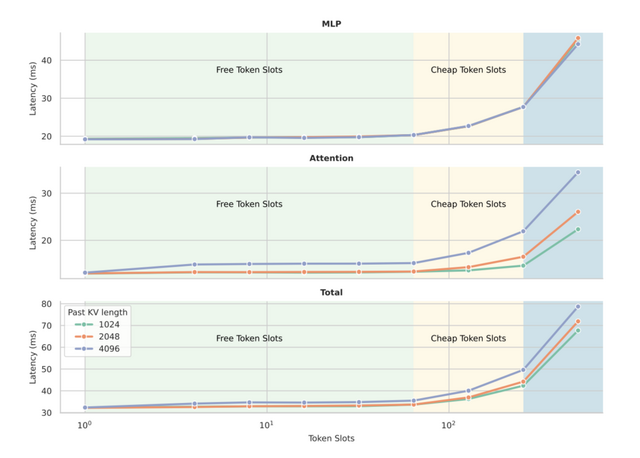
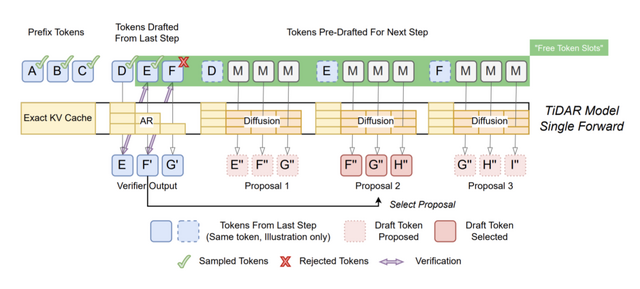
TiDARは、この2つの良いところを組み合わせた新しい方法です。まず拡散モデルで複数の候補トークンを下書きし、その後、従来の方式で品質をチェックしながら最終的な単語を選びます。この2つの処理を1回のステップで同時に行えるのが最大の特徴です。
実験では、15億パラメータのモデルで約4.7倍、80億パラメータのモデルで約5.9倍も高速化できました。しかも、プログラミングや数学の問題を解く精度は、従来の方式とほぼ同等を保っています。
TiDAR: Think in Diffusion, Talk in Autoregression
Jingyu Liu, Xin Dong, Zhifan Ye, Rishabh Mehta, Yonggan Fu, Vartika Singh, Jan Kautz, Ce Zhang, Pavlo Molchanov
Paper
ByteDance、画像から広大な3D空間を高精度に復元する新AI「Depth Anything 3」発表
ByteDanceの研究チームが開発した「Depth Anything 3」(DA3)は、1枚の画像でも複数の画像、動画でも、カメラの位置情報がなくても、高精度な3D空間の復元を実現します。従来の複雑な手法とは異なり、シンプルな単一のトランスフォーマーモデルで動作する点が特徴です。
技術面では、DA3は深度マップとrayマップ(カメラ光線の起点と方向を表す)の2つだけを予測ターゲットとする最小限のアプローチを採用しています。また、事前学習済みのビジョントランスフォーマー(DINOv2など)を基盤として使用し、独自の自己注意機構を導入することで、任意の数の視点に対応できるようになっています。
性能評価では、研究チームが新たに構築した視覚幾何ベンチマークにおいて、DA3は既存の最先端モデルVGGTを大きく上回る成果を示しました。カメラポーズ推定精度で平均35.7%、幾何学的精度で23.6%の改善を達成し、単眼深度推定でも前世代のDepth Anything 2を超える性能を示しています。
約11億パラメータのGiantモデルから2200万パラメータのSmallモデルまで用意されています。


Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y. Chen, Zhenyu Li, Guang Shi, Jiashi Feng, Bingyi Kang
Project | Paper | GitHub
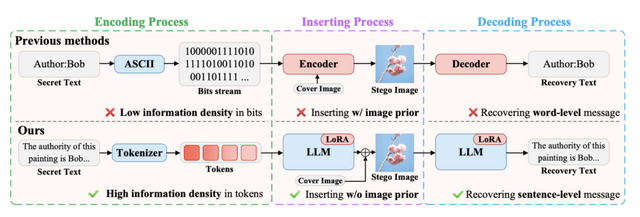
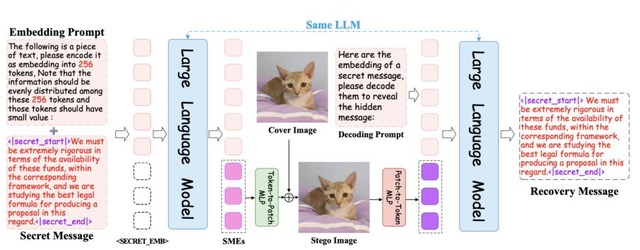
画像に長文テキストを隠して埋め込めるAIを用いたステガノグラフィー技術「S²LM」
研究チームが、大規模言語モデル(LLM)を活用したステガノグラフィー技術「S²LM」を開発しました。
ステガノグラフィーとは、あるデータに別のデータを埋め込み、隠す技術のこと。従来のステガノグラフィーは画像にビット単位の情報しか隠せませんでしたが、S²LMは文章や段落レベルの自然言語を画像に埋め込むことができます。256×256ピクセルの画像に最大500語のテキストを隠すことに成功し、画像品質を保ちながら高い復元精度を実現しています。
この技術はLLMのトークナイザーで秘密のメッセージをトークン化し、意味的な埋め込みを生成することで実現されます。Qwen2.5、Llama3.2などの複数のLLMで動作確認され、新しいベンチマーク「Invisible Text」での評価でも良好な結果を示しました。

S²LM: Towards Semantic Steganography via Large Language Models
Huanqi Wu, Huangbiao Xu, Runfeng Xie, Jiaxin Cai, Kaixin Zhang, Xiao Ke
Paper








![イヤホン 有線 [HIFI音質]イヤホン 有線 3.5mmジャック ノイズ低減 通話/音楽 音量調節対応 防水 通勤・会議・運動 | 原音再現 MFi認証 重低音 遅延なし コンパクト 軽量 インイヤー 人体工学 image](https://m.media-amazon.com/images/I/31CBe3mkz-L._SL160_.jpg)






