
生成AIグラビアをグラビアカメラマンが作るとどうなる?第69回:Boogu-Image-0.1とKrea 2が登場。Z-Imageの牙城を崩せるか?(西川和久)
Boogu-Image-0.1


生成AIグラビアをグラビアカメラマンが作るとどうなる?第68回:Ideogram 4.0用JSON Promptビルダーを作ってみた(西川和久)
強力なi2t Ideogram 4.0が登場しました。

生成AIグラビアをグラビアカメラマンが作るとどうなる?第67回:HiDream-O1の公式ワークフローを改良したら、もう本物の写真に!?(西川和久)
前回、HiDream-O1の前編とも言える記事を掲載した。ただタイミング的にComfyUIが対応中だったこともあり、掲載したWorkflowは公式のものではない。

アニメやイラストに特化したローカル画像生成AI「Anima」 生成した画像は商用利用も可能(生成AIクローズアップ)
今回は、CircleStone LabsとComfy Orgが共同開発した、アニメやイラストの生成に特化した20億パラメータを持つローカル画像生成AIモデル「Anima」を取り上げます。


生成AIグラビアをグラビアカメラマンが作るとどうなる?第66回:HiDream-O1登場! 最大400万画素の「まるで写真」(西川和久)
5月9日、t2i/i2i対応の新生、HiDream-O1がリリースされました。

生成AIグラビアをグラビアカメラマンが作るとどうなる?第65回:顔LoRA不要、写真4枚で激似にするWorkflowを紹介しよう(西川和久)
生成AI画像で任意の顔に似せるには?

生成AIグラビアをグラビアカメラマンが作るとどうなる?第64回:日本語文字に強いERNIE-Image登場!(西川和久)
Baiduから文字に強いERNIE-Image登場!

生成AIグラビアをグラビアカメラマンが作るとどうなる?第63回:プロンプトがマンネリ化してるとお嘆きの貴兄に(西川和久)
今回は意外性のある出力を求める実験。プロンプトをいかに拡張するか。

生成AIグラビアをグラビアカメラマンが作るとどうなる?第61回:快適にZ-Image-Baseを使う方法、そして左から右に生成するBitDance(西川和久)
快適にZ-Image-Baseを使うには?

生成AIグラビアをグラビアカメラマンが作るとどうなる?第60回:遂に登場したZ-Image-Baseの破壊力!(西川和久)
Z-Image-Baseリリース!
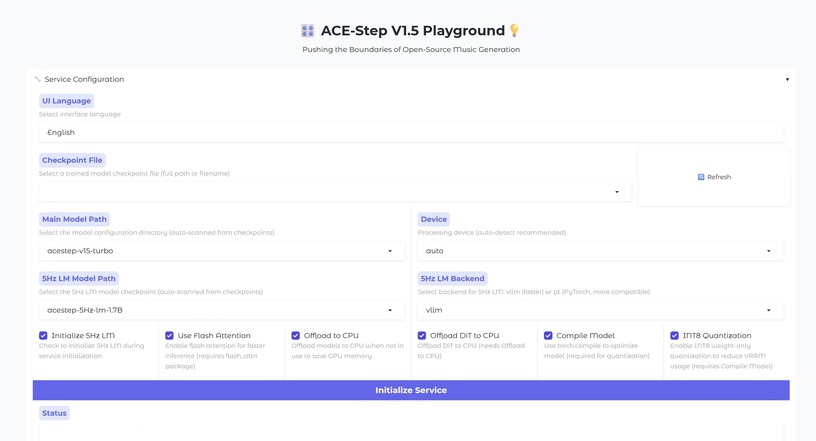
Suno v5に迫るオープンソース作曲AI「ACE-Step v1.5」、Mistral AIが開発の文字起こしAI「Voxtral Transcribe 2」など生成AI技術5つを解説(生成AIウィークリー)
この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第131回)は、論文から図表を生成するGoogle開発のAI「PaperBanana」や、Suno v5に迫る精度のオープンソース音楽生成AI「ACE-Step v1.5」を取り上げます。

歩き回れるバーチャルワールドを生成するオープンソースAI「LingBot-World」、写真からアニメまで幅広いスタイルを生成できるフルスペック画像AI「Z-Image」など生成AI技術5つを解説(生成AIウィークリー)
この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第130回)は、DeepSeek開発の文書読み取りAI「OCR 2」や、歩き回れるバーチャルワールドを生成できるオープンソースAI「LingBot-World」を取り上げます。
![生成AIグラビアをグラビアカメラマンが作るとどうなる?第59回:BFLからFLUX.2 [klein]リリース!(西川和久) 画像](/imgs/p/I7E-tRhECAmbEbuwokhjFw2aqJSmlZSTkpGQ/29396.jpg)
生成AIグラビアをグラビアカメラマンが作るとどうなる?第59回:BFLからFLUX.2 [klein]リリース!(西川和久)
BFLからFLUX.2 [klein]登場!

生成AIグラビアをグラビアカメラマンが作るとどうなる?第58回:大晦日に登場したQwen-Image-2512の実力は?(西川和久)
Qwen-Image-2512リリース!

よりリアルになった画像 to 3Dモデル「TRELLIS.2」Microsoftが発表、動画をPOVに変換するAI「EgoX」など生成AI技術5つを解説(生成AIウィークリー)
この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第125回)は、中国AIユニコーン「StepFun」が開発したGUI自動操作AI「Step-GUI」や、画像から高品質な3Dモデルを生成するMicrosoft開発のAI「TRELLIS.2」を取り上げます。

生成AIグラビアをグラビアカメラマンが作るとどうなる?第57回:充実してきたZ-Image-Turboその後(西川和久)
Z-Image-Turboその後の動きについて。

生成AIグラビアをグラビアカメラマンが作るとどうなる?第56回:2025年秋の陣Part 2は高速無検閲のZ-Image-Turbo(西川和久)
前回、2025年秋の陣Part1としてFLUX.2 [dev]をご紹介したが、直後の11月27日にリリースされたZ-Image-Turboをご紹介したい。
![生成AIグラビアをグラビアカメラマンが作るとどうなる?第55回:2025年秋の陣Part 1はFLUX.2 [dev]でローカル生成(西川和久) 画像](/imgs/p/I7E-tRhECAmbEbuwokhjFw2aqJSmlZSTkpGQ/28690.jpg)
生成AIグラビアをグラビアカメラマンが作るとどうなる?第55回:2025年秋の陣Part 1はFLUX.2 [dev]でローカル生成(西川和久)
前回、2025年夏の陣も終わり今は一段落している……と書いたばかりなのに、その直後、Nano Banana Pro、FLUX.2、Z-Imageが一気にリリース。秋の陣が始まった(笑)。今回はこの中からローカルで生成可能な、FLUX.2 [dev]をご紹介したい。

生成AIグラビアをグラビアカメラマンが作るとどうなる?第54回:ローカル生成からクラウドサービスにちょっと浮気中(西川和久)
本連載では新しいCheckpointやLoRA、ComfyUIのカスタムノードなど、ローカル生成をメインで扱っているのだが、2025年夏の陣も終わり今は一段落している。噂によると年内いくつか出るかも?らしいが、今回はサービス系で筆者が最近使っているものをご紹介したい。

Nano Banana Pro万能説。手書き文字も生成できたのがうれしい(CloseBox)
Googleの画像生成AIとしてImagenとかよりはるかに定着してしまったNano Banana。そのより高度なバージョン「Nano Banana Pro」が使えるようになり、さまざまな用途に使われています。その応用例の一つを紹介しましょう。


生成AIグラビアをグラビアカメラマンが作るとどうなる?第53回:ちょっと面白くて便利なComfyUI Workflow(西川和久)
日頃筆者が便利で使っているComfyUIのWorkflowをご紹介したい。

“ほぼ無限”の動画をリアルタイムに理解できるAI「StreamingVLM」、1台のH100 GPUで320億パラメータのLLMを強化学習できる「QeRL」など生成AI技術5つを解説(生成AIウィークリー)
この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第117回)は、過度な圧縮をしない画像生成AI技術「RAE」や、長時間動画をリアルタイムに理解できるAIモデル「StreamingVLM」を取り上げます。

生成AIグラビアをグラビアカメラマンが作るとどうなる?第52回:オープン画像生成AIが怒涛の登場果たした2025年9月(西川和久)
Qwen-Imageで大物txt2imgは終わりかなと思っていた矢先の9月9日、 HunyuanImage-2.1 がリリース。その後も怒涛のアップデートが起きている。

生成AIグラビアをグラビアカメラマンが作るとどうなる?第51回:Qwen-Image旋風だった2025年8月まとめ(西川和久)
2025年8月

生成AIグラビアをグラビアカメラマンが作るとどうなる?第50回:2025年夏、画像AIに何が起こっていたのか。6月&7月まとめ(西川和久)
6~8月、休載していたこともあり、今回と次回はこの間リリースされたものなどを順にご紹介し、現時点=9月に追い付きたいと思う。まず6月から。

LoRAなし、プロンプトだけで本人にどれだけ寄せられるかチャレンジ。AIで人物写真を再現するもう一つの方法(CloseBox)
LLMのマルチモーダル機能が進化したことにより、今ならば、参照画像なしのText to Imageだけで特定人物を再現できるのでは? そう筆者は考え、試してみることにしました。

生成AIグラビアをグラビアカメラマンが作るとどうなる?第49回:5月20日のテクノエッジ「生成AI最前線」になんと、LoRAっ子1号がリアル参戦(西川和久)
5月20日のリアルイベント、テクノエッジ「生成AI最前線」の講演者本人自身の詳細レポート
- 27件中 1 - 27 件を表示