


この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第131回)は、論文から図表を生成するGoogle開発のAI「PaperBanana」や、Suno v5に迫る精度のオープンソース音楽生成AI「ACE-Step v1.5」を取り上げます。
また、GPT-5.2に迫る精度のオープンソースなAIモデル「Kimi K2.5」や、Mistral AIが開発の文字起こしAI「Voxtral Transcribe 2」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、Googleが一般公開(限定)したAI「Genie 3」で作った、動き回れる3DバーチャルワールドをSNSで共有する3Dゲーム生成祭りを別の単体記事で取り上げています。
論文から図表を生成するAI「PaperBanana」をGoogleが発表
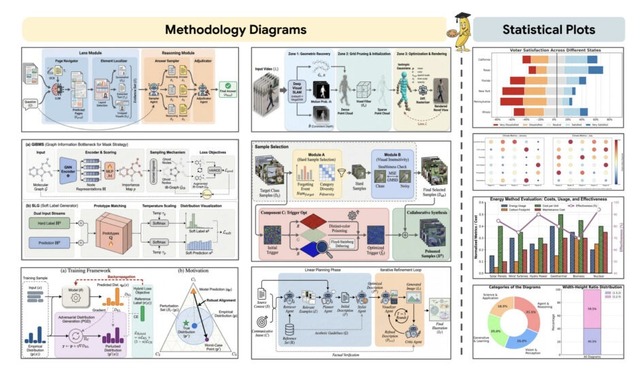
Google Cloud AI Researchや北京大学の研究チームが、学術論文用の図表(ダイアグラムや統計グラフなど)を自動生成するエージェント型フレームワーク「PaperBanana」を発表しました。
現在のAI科学者はテキスト解析やコード実行には長けていますが、出版レベルの高品質な図表を作成することは依然として人間にとって大きな負担となっています。
この課題を解決するため、PaperBananaは「Retriever」(資料収集担、「Planner」(企画・構成)、「Stylist」(デザイン調整)、「Visualizer」(可視化)、「Critic」(評価)という5つの専門エージェントを連携させ、論文の本文とキャプションから洗練された図表を生成します。
NeurIPS 2025の採択論文292件のテストケースからなるベンチマークで評価したところ、既存手法を総合スコアで17%上回り、人間による評価でも高い評価を達成しました。
PaperBanana: Automating Academic Illustration for AI Scientists
Dawei Zhu, Rui Meng, Yale Song, Xiyu Wei, Sujian Li, Tomas Pfister, Jinsung Yoon
Paper
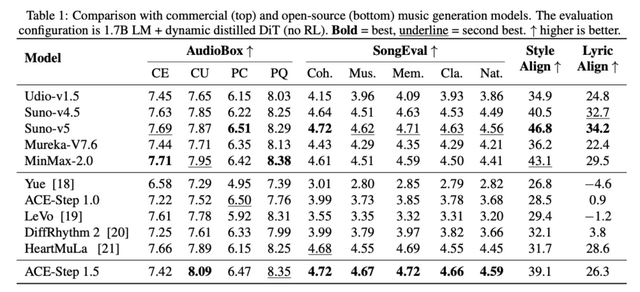
Suno v5に肉薄するオープンソース音楽生成AI「ACE-Step v1.5」、VRAM4GB未満の家庭用GPUでも動作
ACE Studioが発表した「ACE-Step v1.5」は、オープンソースの音楽生成モデルでありながら商用モデルSuno v4.5とSuno v5の間くらいの品質だとGitHubの説明で述べています。A100で1曲2秒未満、RTX 3090でも10秒未満で生成でき、VRAM4GB未満で動作します。
少数の楽曲からLoRAを学習させることで、ユーザー独自のスタイルを反映したパーソナライズにも対応しています。
仕組みとしては、言語モデルがユーザーの曖昧な指示をBPMや調・構成などの設計図に変換し、Diffusion Transformerがそれをもとに音響合成を行うという役割分担が特徴です。この分離により、数秒から10分までの楽曲生成に対応できます。
蒸留技術により生成ステップを50から4~8に圧縮し、100倍以上の高速化を達成しました。テキストからの音楽生成だけでなく、カバー生成、リペイント、ボーカルからBGMへの変換なども単一モデルで対応し、50以上の言語をサポートしています。
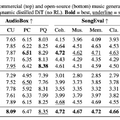
音の品質を評価するベンチマーク「AudioBox」ではACE-Step 1.5がSuno v5とほぼ互角で、曲としての美的品質を評価するベンチマーク「SongEva」ではACE-Step 1.5がSuno v5を上回りました。ただ、指定したスタイルや歌詞にどれだけ忠実に生成できるかの「Style Align」や「Lyric Align」ではSuno-v5が圧倒しました。
Pushing the Boundaries of Open-Source Music Generation
Junmin Gong, Yulin Song, Sean Zhao, Sen Wang, Shengyuan Xu, Joe Guo
Project | Paper | GitHub
文字起こしAI「Voxtral Transcribe 2」をMistral AIが発表。リアルタイム対応&音声ファイルの後処理も可能
Mistral AIは、音声認識モデル「Voxtral Transcribe 2」をリリースいたしました。この新シリーズには、会議音声や通話記録などを後から音声ファイルごと一括で処理できるバッチ処理向け「Voxtral Mini Transcribe V2」と、ライブ配信や音声エージェントに特化した低遅延モデル「Voxtral Realtime」の2種類が含まれています。
Mini Transcribe V2は話者識別、固有名詞の認識補助、単語レベルのタイムスタンプなどを備え、13言語に対応しているバッチ処理向けの音声認識モデルです。料金は1分あたり0.003ドルです。
Voxtral Realtimeは、200ミリ秒以下の低遅延を実現しており、音声をリアルタイムでテキスト化することが可能です。こちらはApache 2.0ライセンスのもと、オープンウェイトとして公開されています。

scribe 2
Mistral AI
Blog | Hugging Face
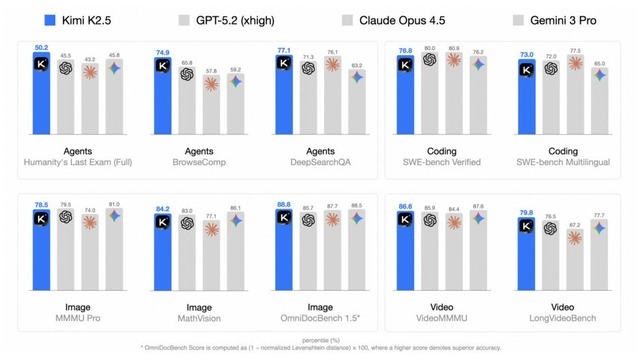
GPT-5.2の精度に迫る、オープンソースなマルチモーダルAIモデル「Kimi K2.5」
Kimi K2.5は、テキストと視覚を処理できるオープンソースのマルチモーダルAIエージェントです。約15兆のテキスト・視覚混合データで事前学習しており、両モダリティを最初から同時に最適化することで互いの性能を高め合う設計です。
従来の常識に反し、視覚データは学習後半に大量投入するより、早期から少量混ぜた方が良いという知見が得られました。さらに、文章だけでファインチューニングしても視覚処理の能力が引き出されるという発見もありました。
また、複雑なタスクを効率化するために、自律的な並列エージェント実行フレームワーク「Agent Swarm」を導入しました。これは、一つの親エージェントが複数の子エージェントを動的に生成・指揮し、並列処理を行う仕組みです。これにより、実行速度を最大4.5倍に高めつつ、精度向上を達成しました。
評価実験では、コーディング、推論、画像理解、動画理解などの主要なベンチマークで、GPT-5.2やClaude Opus 4.5といった最先端の商用モデルに肩を並べる精度で、一部では上回る性能を示しています。特にエージェント検索タスクでは良い結果を示しています。