



この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第129回)は、3秒の音声でボイスクローンを生成する多言語対応の音声合成AIモデル「Qwen3-TTS」や、2D映像から4次元(3D空間+時間)で再構築・追跡するGoogle開発AIモデル「D4RT」を取り上げます。
また、役割と声質を同時に指定できるNVIDIA開発の音声対話AI「PersonaPlex」や、gpt-oss-20bを凌駕する性能の中国発軽量AI「GLM-4.7-Flash」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、AIが数学の未解決問題「エルデシュ問題」を次々と解決している状況が記録されている、フィールズ賞受賞者テレンス・タオが管理するGitHubページを別の単体記事で取り上げています。

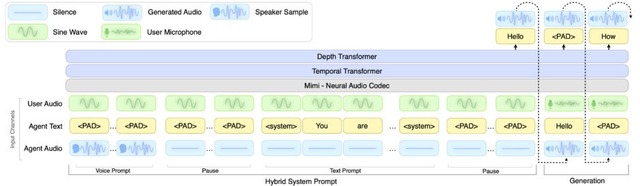
役割と声質を同時に指定できる音声対話AIモデル「PersonaPlex」をNVIDIAが開発
NVIDIAの研究チームは、役割と声質を自在に制御できる音声対話AIモデル「PersonaPlex」を発表しました。
従来のFull Duplexと呼ばれる音声モデルは、ユーザーの話を聞きながら同時に話すような人間らしい会話のタイミングを実現していましたが、声やキャラクター設定が固定されており、柔軟性が求められる場面での利用には限界がありました。
この課題を解決するために開発されたPersonaPlexは、テキストによる役割の指示と、短い音声サンプルから声を再現するボイスクローンを組み合わせた手法を採用しています。
これにより、AIに対して「あなたは保険会社の担当者です」といったテキスト指示を与えつつ、参照となる音声を少し聞かせるだけで、その声色を使って指定された役割を演じることが可能になります。
評価にあたって、研究チームは従来のベンチマークに加え、多様な顧客対応シナリオを想定した新しい評価指標「Service-Duplex-Bench」を策定しました。実験の結果、PersonaPlexは会話の即応性や自然な割り込み処理といった対話性能を維持しつつ、指定された役割の遵守や声の再現性において、既存の最先端モデルを上回るスコアを記録しました。
PersonaPlex: Voice and Role Control for Full Duplex Conversational Speech Models
Rajarshi Roy, Jonathan Raiman, Sang-gil Lee, Teodor-Dumitru Ene, Robert Kirby, Sungwon Kim, Jaehyeon Kim, Bryan Catanzaro
Paper | GitHub | Hugging Face
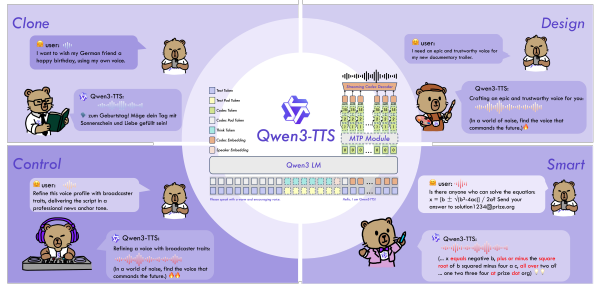
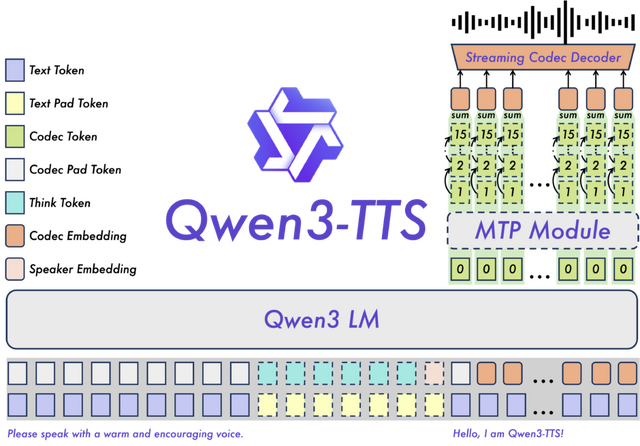
3秒の音声からその人の声を再現できる音声生成AI「Qwen3-TTS」がオープンソースで登場。商用利用可能で日本語にも対応
Qwenチームが発表した「Qwen3-TTS」は、多機能なテキスト音声合成モデルです。500万時間を超える音声データで訓練されており、参照音声から声のクローンや、自然言語による新しい声の作成・細かな調整が可能です。
ボイスクローンでは、わずか3秒の音声入力から話者の声を再現できます。自然言語で指示を与えることで、声のトーンや感情、話し方を細かく制御することも可能です。応答速度も高速で、12Hzモデルでは約0.1秒(97~101ミリ秒)で音声出力を開始できるリアルタイム性能を備えています。
対応言語は中国語、英語、ドイツ語、イタリア語、ポルトガル語、スペイン語、日本語、韓国語、フランス語、ロシア語の10言語。話者の声質を維持したまま異なる言語で音声を生成する多言語合成にも対応しています。
性能面では、ElevenLabsやMiniMaxといった有名なTTSサービスを上回る話者再現性を達成したといいます。モデル(1.7Bと0.6B)とトークナイザー(25Hzと12.5Hz)はApache 2.0ライセンスで公開されています。

映像の「時間と空間」を同時に、かつ高速に理解するAIモデル「D4RT」をGoogleが発表
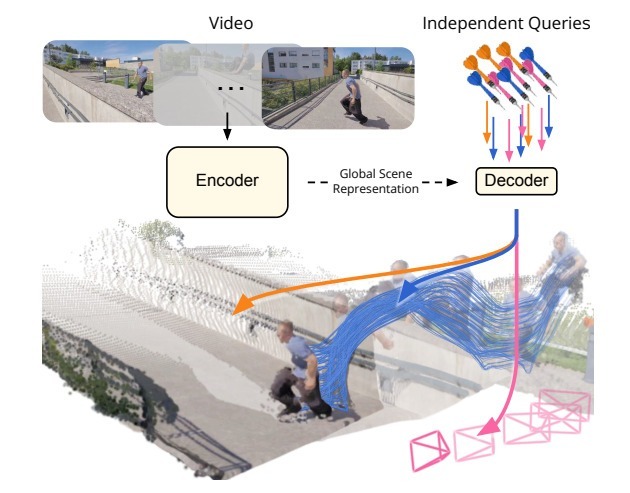
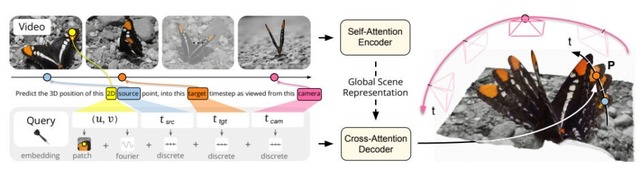
Google DeepMindは、2D映像から4次元(3D空間+時間)で再構築・追跡するAIモデル「D4RT」を発表しました。
私たちは普段、目に入ってくる風景を単なる「瞬間的な画像」としてではなく、過去から現在、そして未来へと続く時間の流れの中にある立体的な世界として自然に認識しています。しかし、AIにとって、平面的な2D映像から奥行きや動きを含む4次元の世界を正確に理解することは、非常に複雑で難しい課題でした。
従来の手法では、奥行きの推定や動きの追跡、カメラ位置の特定などにそれぞれ別のAIモデルや複雑な計算プロセスを使う必要があり、処理が遅くなったり、断片的な結果になったりすることが課題でした。
D4RTはこれらを単一のアーキテクチャに統合し、「ある画素が任意の時点で3D空間のどこにあるか」という問いに答えるクエリ方式を採用しています。クエリは並列処理できるため非常に高速で、従来手法の18倍から最大300倍の速度を実現しました。TPUチップで1分間の動画を約5秒で処理できるようになりました。


Efficiently Reconstructing Dynamic Scenes One D4RT at a Time
Chuhan Zhang, Guillaume Le Moing, Skanda Koppula, Ignacio Rocco, Liliane Momeni, Junyu Xie, Shuyang Sun, Rahul Sukthankar, Joëlle K. Barral, Raia Hadsell, Zoubin Ghahramani, Andrew Zisserman, Junlin Zhang, Mehdi S. M. Sajjadi
Project | Paper | Blog
OpenAIの「gpt-oss-20b」を凌駕する性能の軽量AI「GLM-4.7-Flash」を中国企業Z.aiが発表
中国チームのZ.aiは、GLM-4シリーズの最新ラインアップとして「GLM-4.7-Flash」を発表しました。このモデルは、30Bというサイズ(アクティブパラメータは3B)でありながら、高精度な能力を兼ね備えているといいます。
性能評価データを見るとその実力は、特にコーディングやエージェントタスクにおいて競合モデルを圧倒しています。例えば、実践的なコーディング能力を測るSWE-bench Verifiedではスコア59.2を記録しており、比較対象となっているQwen3-30B(22.0)やgpt‑oss‑20b(34.0)に対し、倍近い、あるいはそれ以上の大差をつけています。
AIエージェントの能力を評価するt^2-Benchにおいても79.5という他に比べて高い数値を叩き出し、他モデルの40点台後半を大きくリードしていますし、Webブラウジング能力を見るBrowseCompでも42.8と頭一つ抜けた性能を示しています。
Hugging Faceでウェイトが公開されているほか、APIサービスもGLM-4.7-Flashは同時接続数1であれば無料で利用可能です。さらに高速かつ安価な「GLM-4.7-FlashX」も用意されています。
GLM-4.7-Flash
Z.ai team
GitHub | Hugging Face


![家庭用GPUを使い良質な画像をわずか1秒で生成する「FLUX.2 [klein]」登場。商用利用可能モデルも(生成AIクローズアップ) 画像](/imgs/p/KS0xA70UphpJ5g7PcXQyhA2bwJXOlZSTkpGQ/29299.jpg)