







生成AIグラビアをグラビアカメラマンが作るとどうなる? 連載記事一覧
ComfyUIの中から画像一覧表示/Prompt確認
前回までで休載していた分のリカバリーが完了し、今回からやっと通常運行。日頃筆者が便利で使っているComfyUIのWorkflowをご紹介したい。
まず生成画像一覧。生成直後の画像などは左にあるHistoryから確認できるが、それ以前となると、ComfyUI/outputフォルダを別のツールを使って表示させる必要がある。ローカルPCにあるGPUでComfyUIを動かしている時はこれでいいのだが、筆者の場合、GPUサーバ的に使っているため画像はローカルに無くサーバ側にある。またどちらのケースも画像は確認できてもそのPromptまでは分からない。
これをサクッと解決してくれるのが ComfyUI_Local_Media_Manager 。custom_nodesへgit clone、pip install -r requirements.txtとして、ComfyUIを再起動、 Local Media Manager でNodeを探せば以下のようなものが見つかる。そしてComfyUI/outputフォルダの絶対pathを入力するとNodeの中に画像一覧が現れる。
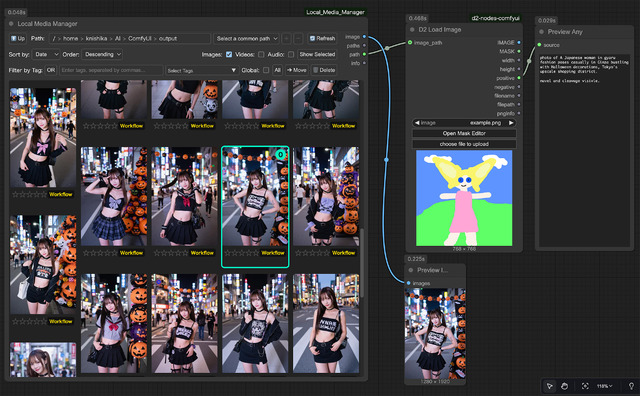
名前/レイティング/日付でソート、レイティング、Workflow表示などの機能があり、これだけでも随分助かる。更に少しNodeを加え(d2-nodes-comfyui > D2 Load Image)、positiveからPreview Any Nodeを接続、実行が必要になるものの、Promptを確認できる。
似ているけれども違うものとしては、ComfyViewer があげられる。これはカスタムNodeではなく、外部プログラムでのWebUIなので興味のある人は試してほしい。
1枚の画像からLoRA用のdataset 20枚を生成する
筆者の場合、顔LoRAを作る時は10枚写真を用意している。ただこれはちゃんと撮影したり、もともと素材豊富な場合はいいのだが、それほどでもない場合やお試しとて撮影前にLoRAを作ったりするケースがあり、そんな時はこのWorkflowを使っている。
Workflow、中央から右側は普通のQwen-Image-Edit-2509のものだ。違いは左側にある ComfyUI_Comfyroll_CustomNodes > CR Prompt List 。文字が小さくて分かりにくいと思うが、単純に[CR]区切りでPromptが20並んでおり、実行すると、全て一気に生成する。
Promptの一つは、
Photorealistic profile view of the subject's face from the left, against a plain white wall background.
こんな感じだ。正面のリファレンス画像を用意し、実行するとQwen-Image-Edit-2509の編集機能で左へ向く。以降は右に向けたり振り返ったりのPromptが並ぶだけ。
生成した画像を見ると同じ様なアングルだったり使えない画像も混じっている。が、必要なのは10枚なので、リファレンス画像+9枚選ぶことになる。これなら少々おかしいのがあっても9枚は必ず確保できるので問題ない。
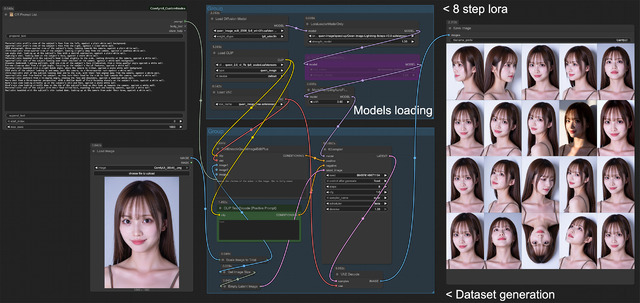
応用例?としてはQwen-Image-Edit-2509 + リファレンス画像ではなく、普通のQwen-ImageにもこのCR Prompt Listが使え、例えばCheckpointや作ったLoRAのテストなど、いろいろな普段使いそうなPromptを並べ、一気に実行すれば結果が分かり、毎回Promptを書き換え都度実行より効率があがる。
流行りのファッションへ一発着せ替え
これもQwen-Image-Edit-2509の応用例。Try-onとなる。着せ替えの場合、ここまで難しいWorkflowにしなくても、標準搭載のTextEncodeQwenImageEditPlus Nodeのimage1に人物の画像、image2へ衣服の画像を入れ、Promptで remove clothing, try-on と書けば多くのケースで着替えた画像が生成される。
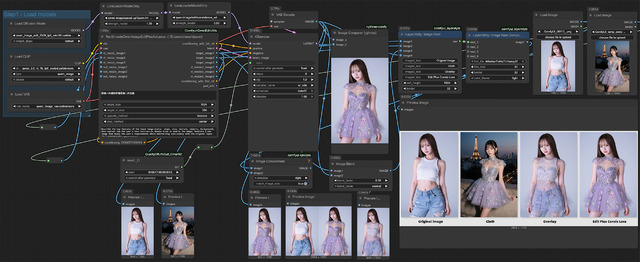

この Comfyui-QwenEditUtils を使ったWorkflow(Githubにある)は、もっと精度をあげるために考えられた仕掛けで、体型やポーズなどを把握し、うまく重ね合わすロジックとなっている(Overlay参照)。単純なTry-onで不満だった人は是非試して欲しい。
写真1枚から同じ顔の別画像を作る
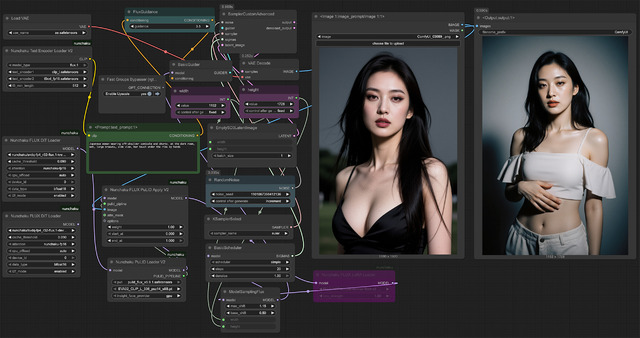
これはNVIDIA GPU専用の高速化拡張、Nunchaku 専用なのだが、PuLIDと言う手法を使い、1枚の写真から顔の一貫性を維持したまま別の画像を生成できる。過去、この手のものはいくつも見てきたものの、正直イマイチなものばかり、とても顔LoRAの替わりに使えるようなものではなかった。
 |  |
しかしこの nunchaku-flux.1-dev-pulid(Workflowはテンプレート)は、ご覧のように、結構高い精度で別画像を生成可能だ。これだけのためにNunchakuを入れる価値があるとも思える機能となっている。
ただし欠点があり、リファレンス画像の顔の向きから大きく変わってしまうような生成は顔が崩れる。こればかりは仕方ないところか。
ComfyUIをWebUI的に操作
最後は、すでにWorkflowも各パラメータも決まっており、後はガチャったり、Promptの調整だけ…の時に役に立つWorkflow……というよりWebUI、 Minimalistic-Comfy-Wrapper-WebUI 。
インストール自体は普通にcustom_nodesへgit clone、pip install -r requirements.txtとして、ComfyUIを再起動でOK。すると左下にアイコンが追加される。
ただこのままでは機能せず、対象となるWorkfowのKSamplerのseed、Prompt入力、画像出力のNodeのタイトルを
<seed:advanced:1>
※ KSamplerからseedを引っ張り出して ComfyUI > Primitives > INT Nodeへ接続
<Prompt:prompt:1>
<Output:output:1>
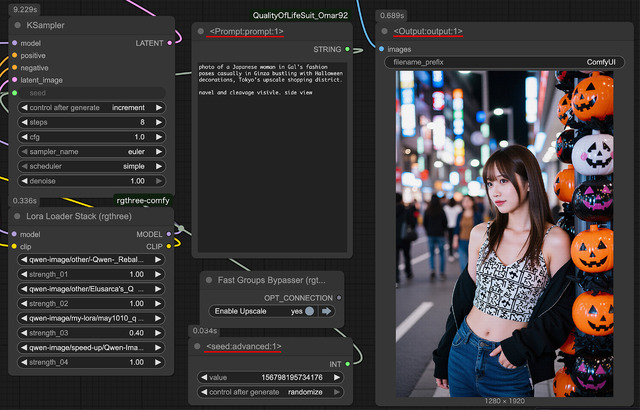
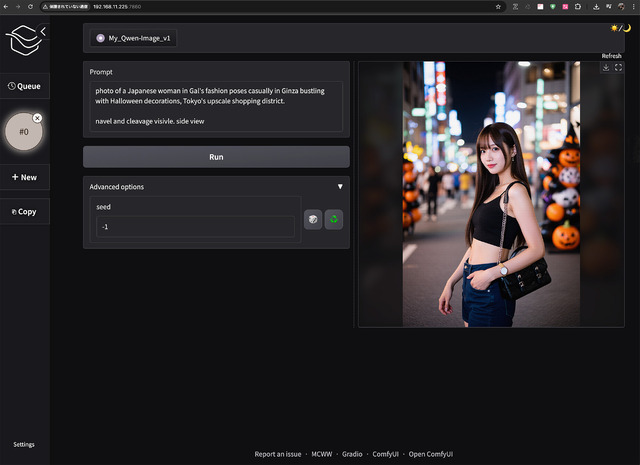
と書き換えWorkflowを保存。そして先の左下に追加されたアイコンをクリックするとご覧のようなWebUIが現れ、[Run]を押せば画像が生成される。Qwen-Image-Edit(2509)のリファレンス画像1~3は以下のようにタイトルを書き換えればよい。
<Image 1:prompt/Image 1:1>
<Image 2:prompt/Image 2:2>
<Image 3:prompt/Image 3:3>
この方法だと余計なNodeが見えず、またPromptを入力する文字が大きく見易い(笑)、macOS + Magic Mouseの場合、マウスの背面=ホイールとなっており、ちょっと触れると拡大率が変わり再調整で面倒……などがこのWebUIだと全てクリアとなる。
まだ開発途中でmodel loadersなどがTODOのままだが、これでLoRA名と重みが調整できるようになれば、筆者的には非常に助かる逸品だ。
今回締めのグラビア
今回締めのグラビアは扉と共にQwen-Imageを使用。時期的に作例も含めほぼハロウィーン一色となった(笑)。

使用したCheckpointは、純正のQwen-Imageではなく、Rebalance v1.0。数千のコスプレ写真や厳選された高品質なリアル画像を含むデータセットで学習したということだ。またLoRAも公開されている。どちらを使うか?はケースバイケースだろうか。
加えて Elusarca's Qwen Image Cinematic LoRA も使用した。Qwen-Imageの場合、暗いシーンでも肌が明るく出る傾向があり、これを抑えるLoRAとなる。
どちらもこれまで見てきたQwen-Imageのテイストとは違うものが生成されるので、興味のある方はぜひ使ってほしい。

















