



この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第130回)は、DeepSeek開発の文書読み取りAI「OCR 2」や、歩き回れるバーチャルワールドを生成できるオープンソースAI「LingBot-World」を取り上げます。
また写真からアニメまで幅広いスタイルに対応するアリババ開発の画像生成AI基盤モデル「Z-Image」や、100体の自律AIが同時に働くオープンソースAIモデル「Kimi K2.5」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、AIエージェントだけのSNSプラットフォーム「moltbook」を別の単体記事で取り上げています。

歩き回れるバーチャルワールドを生成できるオープンソースAI「LingBot-World」 最大10分の世界をリアルタイムで探索可能
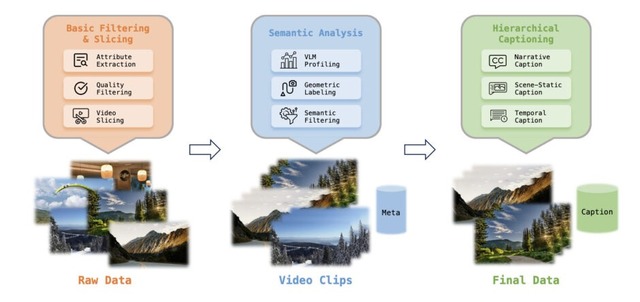
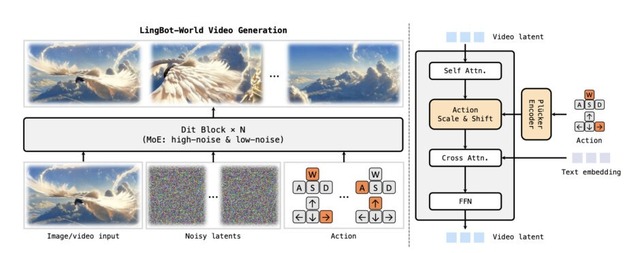
Robbyantチームは、ビデオ生成技術を発展させたオープンソースの世界シミュレーター「LingBot-World」を発表しました。ユーザーがキーボードで操作しながらバーチャルワールドを探索できる、インタラクティブな映像生成AIです。
従来の動画生成AIは短いクリップしか作れず、長くなると映像が破綻してしまう問題がありました。LingBot-Worldは最大10分間の映像でも一貫性を保てる長期記憶能力を持ち、写実的な風景からアニメ調まで幅広いスタイルに対応します。さらに16fpsの映像を1秒未満の遅延で生成できるため、リアルタイムでの操作が可能です。
技術面では、Unreal Engineを用いた合成データやゲームデータを含む大規模なデータエンジンを構築し、動的な制御を学習させています。3段階の学習プロセスを採用しています。まず140億パラメータのビデオ生成モデルで基盤を作り、次にMixture-of-Experts構造でアクション制御と長期的な一貫性を学習し、最後に蒸留技術でリアルタイム推論を実現しています。
応用範囲は広く、ユーザーの指示で天候やスタイルを変えることや、自律的に探索を行うこと、さらには生成映像からの3D再構成など多岐にわたります。



Advancing Open-source World Models
Robbyant Team: Zelin Gao, Qiuyu Wang, Yanhong Zeng, Jiapeng Zhu, Ka Leong Cheng, Yixuan Li, Hanlin Wang, Yinghao Xu, Shuailei Ma, Yihang Chen, Jie Liu, Yansong Cheng, Yao Yao, Jiayi Zhu, Yihao Meng, Kecheng Zheng, Qingyan Bai, Jingye Chen, Zehong Shen, Yue Yu, Xing Zhu, Yujun Shen, Hao Ouyang
Project | Paper | GitHub
“人間の目の動き”を模倣する文書読み取りAI「OCR 2」、DeepSeekが発表
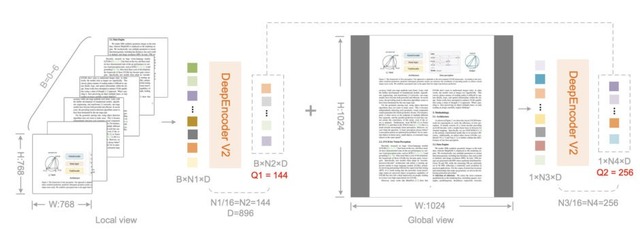
DeepSeek-AIが発表した「DeepSeek-OCR 2」は、文書画像(PDFやスキャン画像など)の読み取りに新しいアプローチを採用した視覚言語モデルです。
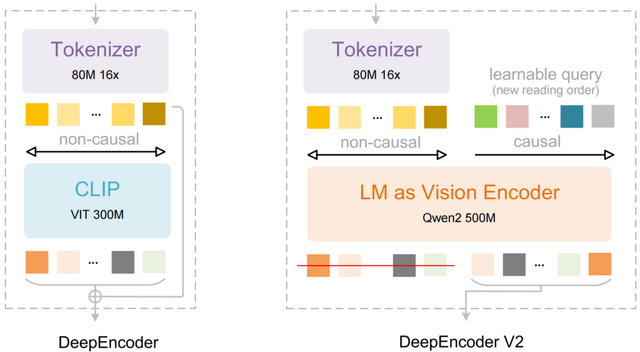
従来のモデルは画像を左上から右下へ固定的な順序で処理していましたが、人間の目は文書の意味構造に沿って柔軟に視線を動かします。このモデルはこの人間らしい認知メカニズムを取り入れました。
モデルの中核となる技術「DeepEncoder V2」では、従来のCLIPコンポーネントを小型の言語モデル「Qwen2-0.5B」に置き換えており、画像の情報をどの順番で読むべきかを判断します。デコーダーがその順序に従って内容を解釈するという2段階の処理をしています。
評価では、PDF文書の解析を評価するベンチマーク「OmniDocBench v1.5」などで、前モデルより性能向上しました。
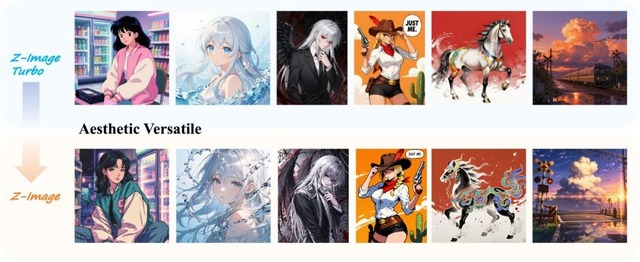
イラストやアニメ調、写真表現などの超リアルまで、幅広い視覚表現を得意とする画像生成AI基盤モデル「Z-Image」をアリババが公開
AlibabaのAI部門に属する研究チーム「Tongyi-MAI」が、画像生成AIベースモデル「Z-Image」を公開しました。これまで高速処理に特化したZ-Image-Turboなどは公開されていましたが、今回はその基盤となる蒸留を行っていないモデルになります。
美的・芸術的な多様性という点では、Z-Imageは非常に広範な視覚表現に対応しています。超リアルな写真表現や映画的なデジタルアートから、精緻なアニメ調やスタイライズされたイラストレーションまで、多次元的な表現が求められるシーンに最適なエンジンとなっています。
複数の人物が登場するシーンでも、それぞれがしっかり区別された自然な画像が生成されます。
技術的な面では、蒸留を行っていないフルサイズのモデルなので、学習データの情報がそのまま保持されています。そのため、LoRAやControlNetといったカスタマイズ手法との相性が良く、開発者や研究者が自分のプロジェクトのベースとして活用しやすい設計になっています。また、ネガティブプロンプトにもしっかり反応するので、不要な要素を取り除いたり、細かい調整をしたりすることが簡単にできます。



Z-Image
Tongyi-MAI team
GitHub | Hugging Face
100体の自律AIが同時に働くオープンソースAIモデル「Kimi K2.5」は動画からコード生成も可能
Moonshot AIは、最新のオープンソースモデル「Kimi K2.5」を発表しました。これは前モデルK2をベースに、約15兆トークンのテキストと画像データで追加学習を行ったマルチモーダルモデルです。
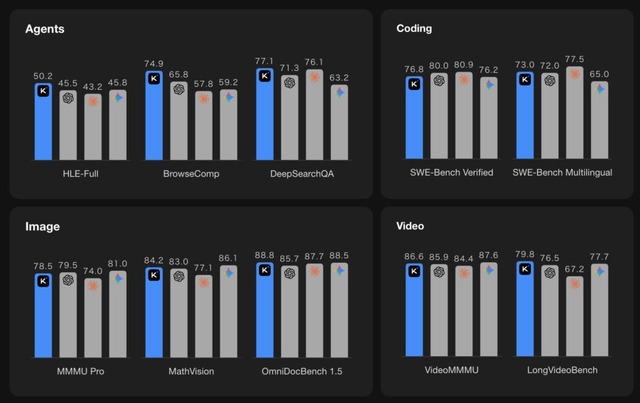
K2.5の最大の特徴は「エージェントスウォーム」と呼ばれる機能です。複雑なタスクに対して最大100体のサブエージェントを自動生成し、最大1500回のツール呼び出しを並列実行できます。これにより単一エージェントと比較して実行時間を最大4.5倍短縮できるとしています。
コーディング能力も大幅に強化されており、特にフロントエンド開発に強みを持っています。画像や動画を入力として受け取り、それをコードに変換する「視覚的コーディング」が可能で、ウェブサイトの動画からコードを再構築したり、迷路画像を解析して最短経路を求めるといったタスクをこなせます。
ベンチマーク結果では、SWE-Bench Verifiedで76.8%、HLE-Full(ツール使用時)で50.2%を達成し、GPT-5.2やClaude 4.5 Opus、Gemini 3 Proといった最先端モデルと競合する性能を示しています。エージェント検索ベンチマークのBrowseCompではスウォームモード使用時に78.4%を記録しました。


![家庭用GPUを使い良質な画像をわずか1秒で生成する「FLUX.2 [klein]」登場。商用利用可能モデルも(生成AIクローズアップ) 画像](/imgs/p/KS0xA70UphpJ5g7PcXQyhA2bwJXOlZSTkpGQ/29299.jpg)