







生成AIグラビアをグラビアカメラマンが作るとどうなる? 連載記事一覧
6~8月、休載していたこともあり、今回と次回はこの間リリースされたものなどを順にご紹介し、現時点=9月に追い付きたいと思う。まず6月から。
2025年6月
6月ではなく5月24日に発表されたGoogleの動画生成AI、Veo 3。実際使ったのが6月頭、また個人的にインパクトが大きかったのでピックアップした。
元となる画像はFLUX.1 [dev]で生成したバンドライブ的な一枚。これをVeo 3に渡すと何とサウンド付きで生成。ボーカルはシャウトで誤魔化しているものの、バックバンドの演奏はライブそのもの。この時点ではGoogleが競合を一気に抜いた感じとなった。

もう一点、どう作ったか?は不明だが、このミュージックPV、ALL生成AIだという。去年辺りまでの「指が~」とか言ってたレベルから別次元になったのがはっきり分かる作品になっている。
6月10日 KREA AIからtxt2imgのKrea 1リリース。但しサービス内での生成のみ
6月27日 ComfyUI が OmniGen2 ネイティブ対応
そして6月27日、先行してサービス/APIで公開中のFLUX.1 Kontext。オープンでも公開?と噂となっていたFLUX.1 Kontext [dev]がリリースされた。これは今流行りのNano Banana(Promptによる画像編集)の先駆け的な位置付けとなる。もちろん、その前からHiDream E1などもあったが、そこはFLUX.1のシリーズで……という意味が大きい。
 |  |
最近流行りのフィギュア化はFLUX.1 Kontext [dev](LoRA無し)でも可能。Promptは以下の通り。
Create a 1/7 scale commercialized figurine of the characters in the picture, in a realistic style, in a real environment. The figurine is placed on a computer desk. The figurine has a round transparent acrylic base, with no text on the base. The content on the computer screen is a 3D modeling process of this figurine. Next to the computer screen is a toy packaging box, designed in a style reminiscent of high-quality collectible figures, printed with original artwork. The packaging features two-dimensional flat illustrations.
これはGoogleがnano-banana用に公式に出したもの。以降txt2imgでの編集可能モデル乱戦状態になっている。
2025年7月
2025年は、FLUX.1 [dev]と戦えそうな(笑)モデルとして、HiDream-I1、OmniGen2などいくつかリリースされたものの、主に重いのが理由で流行らず。サービス系では先のKrea 1など、いろいろ出始め、「今年はもう刈入れ時でオープンは出ないのか…」と思っていたところに急報。
何と動画用のWan 2.1で画像を生成すれば結構イケる!との情報が。Wan 2.1用のLoRAも利用できる=顔LoRAも学習可能。早速試したのが以下の2枚。
 |  |
ご覧の様になかなかの出来栄え! 指はもちろん、体も崩れ難く、これはFLUX.1 [dev]超えた!?としばらく遊んでいた。
そうこうしている間の7月28日、Wan 2.2がリリースされた。動画用としてはかなりパワーアップしているのだが、筆者の興味はtxt2img(笑)。早速Workflowを変更して……と思ったところ、Wan 2.1ではモデルが1つだったのに対し、Wan 2.2ではハイノイズ/ローノイズを2つになっている。SDXL refinerの悪夢再びか?的な感じだ。
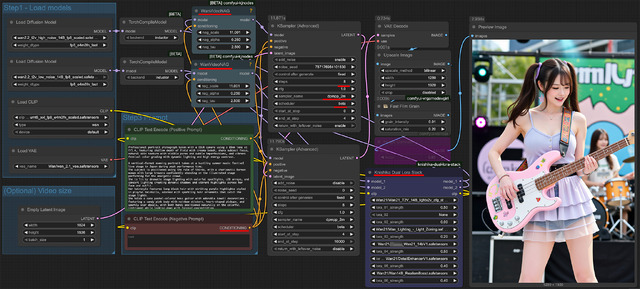
以降、コミュニティ界隈では高速化LoRAや改良版Workflowなど続々登場。現在筆者は使っているWorkflowがこれ。モデルがハイノイズ/ローノイズと2つあるので複雑化しているのが分かる。
 |  |
こうしてFLUX.1とサヨナラする準備が着々と進む中、7月31日いきなり登場したのがFLUX.1 Krea [dev] 。FLUX.1のBlack Forest LabsとKREA AIがコラボし作ったFLUX.1 [dev]の派生モデルだ。
 |  |
FLUX.1 [dev]
FLUX.1 Krea [dev]
同一設定で生成した絵柄はかなり違う。リリース資料によるとAIっぽさを避け、現実的な写真っぽさを重視とある。加えて日本人を含むアジア系の顔も改善。以前から指摘していた硬調も修正されている。実際これだけ違うと「え”」と言う感じだ(笑)。なかなかの一手と言えよう。
今回締めのグラビア
締めのグラビアは扉と共にFLUX.1 Krea [dev]を使用。上記の比較からも分かる様に、これFLUX.1 [dev]?と思えるほど違うのが特徴となる。

次回は2025年8月9月をまとめてみたい。オープンなのはもう出ないのか……と思っていたところに(いろいろな意味で)巨大なモデルが2つもリリースされ嬉しい限り。お楽しみに!



![生成AIグラビアをグラビアカメラマンが作るとどうなる?第46回:遂にオープンでFLUX.1 [dev]を超える!? HiDream-I1登場(西川和久) 画像](/imgs/p/KS0xA70UphpJ5g7PcXQyhA2bwJXOlZSTkpGQ/24799.jpg)
![生成AIグラビアをグラビアカメラマンが作るとどうなる?第45回:FLUX.1 [dev]より高性能!?Reve Image登場+α(西川和久) 画像](/imgs/p/KS0xA70UphpJ5g7PcXQyhA2bwJXOlZSTkpGQ/24237.jpg)















