
1週間の気になる生成AI技術・研究をいくつかピックアップして解説する連載「生成AIウィークリー」から、特に興味深いAI技術や研究にスポットライトを当てる生成AIクローズアップ。
今回は、AIチャットボットへの入力(プロンプト)が、実は処理過程で失われていなかったことを証明した論文「Language Models are Injective and Hence Invertible」を取り上げます。スイス連邦工科大学ローザンヌ校(EPFL)やイタリアのローマ・サピエンツァ大学に所属する研究者らによる研究報告です。
ChatGPTのような言語モデルに文章を入力すると、モデルの内部で複雑な計算が行われますが、その過程で元の入力文章の情報が失われているのではないかと考えられています。しかし、この研究によって、実は入力された文章の情報が完全に保存されていることが数学的に証明されました。

▲AIチャットボットへのテキスト入力がすべて保存されている様子のイラスト(絵:おね)
言語モデルは、入力されたテキストを内部表現である数値のベクトル(数値の配列)に変換して処理します。この変換過程には複雑な計算が含まれており、これらは理論的には情報を失う可能性がある処理です。そのため、異なる入力が同じ内部表現になってしまう「衝突」が起こりうると考えられています。しかし研究チームは、標準的なTransformerアーキテクチャでは、このような衝突が実質的に起こらないことを証明しました。
この性質は「単射性」と呼ばれます。単射性とは、異なる入力が必ず異なる出力を生み出すという数学的性質です。研究では、モデルのパラメータが通常の方法で初期化され、標準的な学習方法で訓練される限り、この単射性が保たれることを示しました。
実証実験では、GPT-2やGemma-3といった実際に使用されている6つの言語モデルに対して、10万個のテキストプロンプトを使用して数十億回の衝突テストを実施しました。その結果、異なる入力が同じ内部表現を生成する衝突は一度も観測されませんでした。最も近い2つの表現の間でさえ、明確な距離が保たれていることが確認されました。
この理論的発見を実用化するため、研究チームは「SIPIT」(Sequential Inverse Prompt via Iterative updates)というアルゴリズムを開発しました。このアルゴリズムは、モデル内部の数値配列から元の入力テキストを正確に復元することを目的としています。
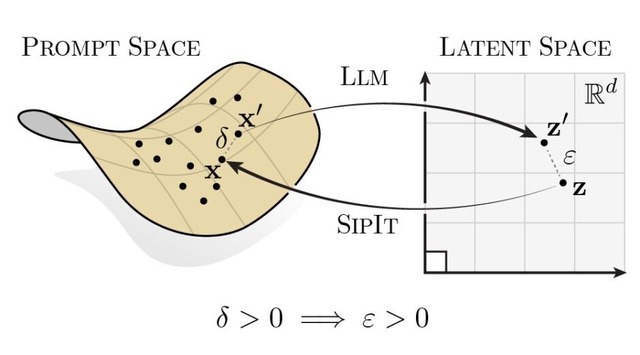
▲言語モデルによるプロンプトから潜在空間への単射写像と、SIPITによる逆変換を示す図
実験では、20トークンの長さのプロンプト100個すべてにおいて、100%の精度で元のテキストを復元することに成功しました。従来の手法では近似的な復元しかできなかったのに対し、SIPITは完全に正確な復元を実現しました。
この発見は、AIシステムの透明性と解釈可能性に大きな影響を与えます。モデルの最終層の状態が入力全体の情報を完全に含んでいることが保証されるため、モデルの動作を分析する際の確実な基盤となります。また、プライバシーの観点からも重要な意味を持ちます。モデルの内部表現は単なる抽象的なデータではなく、実質的に元のテキストそのものを含んでいることが明らかになったからです。