








生成AIグラビアをグラビアカメラマンが作るとどうなる? 連載記事一覧
前回、2025年秋の陣Part1としてFLUX.2 [dev]をご紹介したが、直後の11月27日にリリースされたZ-Image-Turboをご紹介したい。

Z-Image-Turbo / 生成
Z-Image-TurboはQwen-Imageでお馴染み、Alibabaから11月27日リリースされた。Qwen-Imageがあるのに何故!?と思ってしまうが、それはさておき、特徴として以下があげられる。
Turbo、BASE、Editの3種類
27日は蒸留版のTurboのみ
https://huggingface.co/Tongyi-MAI/Z-Image-Turboパラメータ数6B
FLUX.1 [dev] 12B、Qwen-Image 20B、同時期にリリースされたFLUX.2 [dev]は32B
テキストエンコーダーにQwen3 4Bを使用しマルチリンガルライセンス Apache 2.0
今回は蒸留版のTurboのみだったが、フルのBASEと編集可能なEditがリリース予定となっている。ライセンスはApache 2.0(BASEとEditは現時点では不明)。
パラメータは今時6Bとかなり小さい。FLUX.1 [dev] 12B、Qwen-Image 20B、同時期にリリースされたFLUX.2 [dev]は32B……なので、いかに小さいかが分かる。
ただしテキストエンコーダーには最新のqwen3-4bを使用。Qwen-Imageだとqwen2.5-vl-7bなので、それより新しいものを採用している。4bと小さいものの、最新鋭ということもあり、Promptは日本語のままで(ほぼ)正確に再現できる。
WorkflowはComfyUIのテンプレートにあり、モデルさえダウンロードすればサクッと試すことが可能だ。
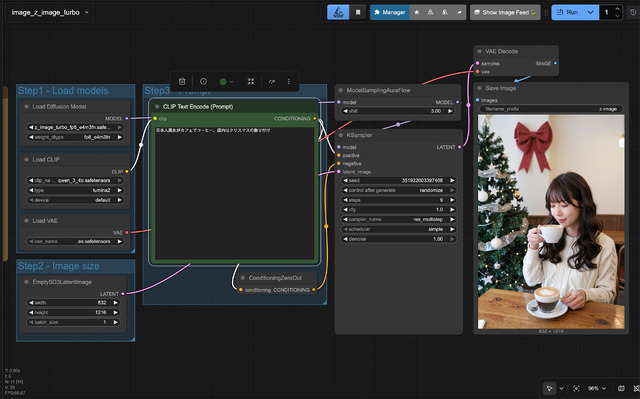
なおVRAMが8GBや12GBなど少ない場合は、fp8版やgguf版を使えば作動する。stepsが9と小さく、高速生成できるのが特徴。
gguf版
https://huggingface.co/jayn7/Z-Image-Turbo-GGUF
https://huggingface.co/vantagewithai/Z-Image-Turbo-GGUF
https://huggingface.co/worstplayer/Z-Image_Qwen_3_4b_text_encoder_GGUF
前回、4つのモデルで比較したが、今回はFLUX.2 [dev]の部分をZ-Image-TurboとしPrompt「a young Japanese woman」。FLUX.1 [dev]、FLUX.1 Krea [dev]、Qwen-Image、そしてZ-Image-Turbo(LoRA/参照画像無し)。解像度は832x1216pxに合わせてある。
 |  |
 |  |
生成時間はRTX 5090でたった3.24秒。Nunchaku化したFLUX.1 Krea [dev]より速い(笑)。そしてどれよりも一番それっぽく生成されている。さらに調べたところ無検閲。
以下、作例をいくつか並べてみた。無学習のオリジナルのままでかなりリアルに出ている。これが秒でサクッと作れるのは嬉しい限りだ。
 |  |
 |  |
Z-Image-Turbo / LoRA学習とControlNet
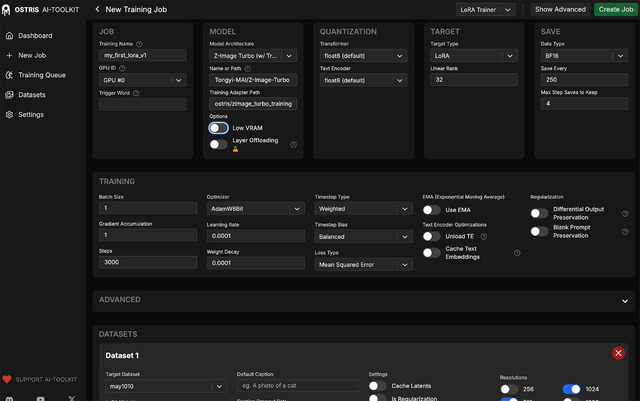
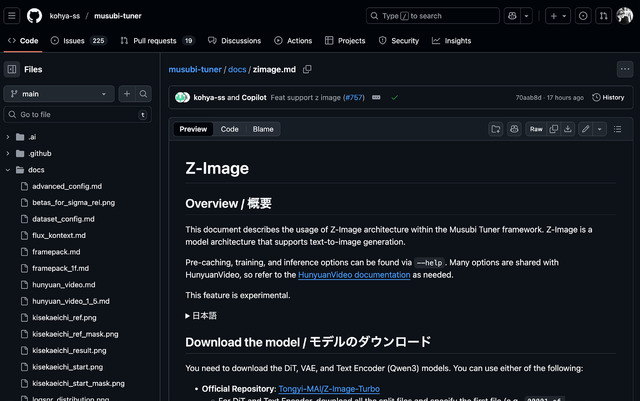
執筆時、LoRA学習とControlNetは対応済み。LoRAの学習に関してはローカルではai-toolkit。musubi-tunerは現在対応中。サービス系ではWaveSpeedAIとfaIが対応している。
 |  |
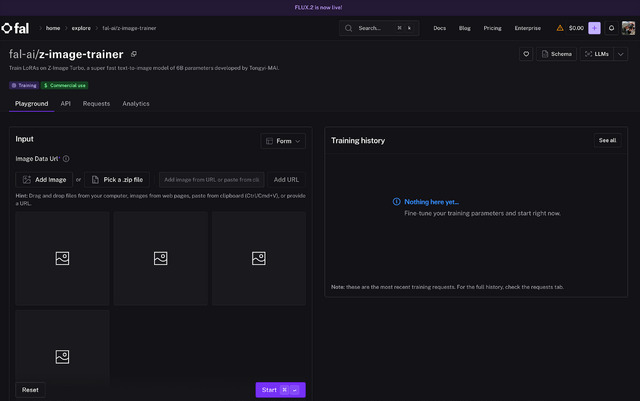 | 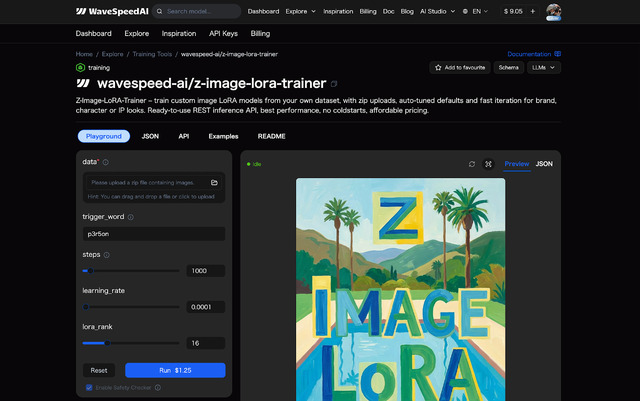 |
LoRAの学習環境をローカルに作るのは結構手間なので、サービスを利用するのもあり。顔LoRAの場合、1024x1024pxの写真を10枚ほど用意すれば良い。以下、作った顔LoRAを使った作例を2点。LoRAは普通にMODEL/model間に入れる。
 |  |
ControlNetのWorkflowは以下の通り。赤いノードが追加した部分となる。なお、ControlNetのモデルはmodels/model_patchesへ入れる必要がある。Unionタイプなのでモデル1つで、Pose、Depth、Canny、Hedなど複数の形式に対応する。
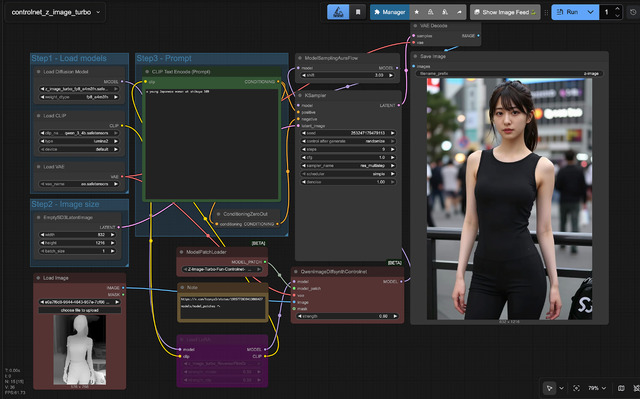
ここまでが11月27日リリースされてから約1週間。もの凄い勢いでいろいろ開発されているのが分かる。速くて無検閲、そしてApache 2.0ということもあり大人気!
Civitaiには日々多くのLoRAや最近は派生Checkpointも上がっている。同じPromptで生成するとFLUX.2 [dev]の方が奥行きがあって絵的にはいいのだが、あまりにも重過ぎる。ローカル生成用としては既に勝負あった感じだ。
Z-Image-Turbo / Prompt拡張
このZ-Image-Turbo、公式のリポジトリに面白いコードがあって、そこにはLLMのSystem Promptに渡す一文が中国語で入っている。日本語に訳すると
あなたは画像生成AI用のプロンプト改善の専門家です。ユーザーの簡単な要望を、具体的で詳細な視覚描写に変換します。
作業手順:
核心要素の確認: 主体、数量、動作、色、指定された名前など、変更してはいけない要素を把握
推論が必要か判断: 「~をデザインして」「~を説明する画像」など、具体的なビジュアル案を考える必要があれば、まず明確な構想を立てる
視覚的詳細を追加: 構図、光、色彩、質感、空間配置などを具体的に記述
文字の正確な処理: 画面に表示する文字は必ず英文ダブルクォーテーション("")で括る。看板、ポスター、UI、図表などの文字も全て明記し、位置やフォントも説明
客観的に記述: 比喩や感情表現は使わず、具体的な視覚要素のみを記述。「8K」「傑作」などの評価語は含めない
修正後のプロンプトのみを出力してください。説明や補足は不要です。
ユーザー入力プロンプト: {prompt}
となる。これをLLMのSystem Promptへ入れ、例えば”a Japanese woman”とすると、以下のような出力になる(gpt-oss-120b)。
Japanese woman, solo, medium close-up portrait facing forward, wearing a traditional indigo silk kimono with subtle white wave pattern, hair styled in a classic updo adorned with kanzashi ornaments, soft natural daylight from the left creating gentle shadows on her face, background featuring a simple shoji screen with translucent paper, standing while holding an open delicate wooden folding fan, serene expression, fair skin tone, almond‑shaped brown eyes, composition centered with shallow depth of field focusing on the subject, muted earth tones and indigo color palette.
やっぱりJapaneseを入れると着物になるのね(笑)……はさておき、なかなかのPromptが生成される。筆者のようにGoogle翻訳を使ってる人では書けない英文だ。
このままLLMと併用してもいいのだが、Prompt拡張をそのまま搭載したカスタムノードがあり、LLMだけでなく、VLLMにも対応。つまりqwen3-vl-8bなどを使えばリファレンス画像から内容を得て、それをPrompt拡張することも出来る。Workflowも含めここにあるので、興味のある人は試してほしい。
今回締めのグラビア
今回締めのグラビアはもちろん、扉も含めZ-Image-Turboを使い生成。ダイレクトに長辺1920pxが出せるのでアップスケールはしていない。LoRAはReversalFilmGravure LoRA for z_image_turboを使用。名前の通りアナログっぽい仕上がりになりお気に入りの一つだ。

今年もあと一回原稿を書けば終わり。締めに何を書くかは考え中だ。ただこの間にもt2iのモデルが2つ登場。これらについても軽く触れるかもしれない。

![生成AIグラビアをグラビアカメラマンが作るとどうなる?第55回:2025年秋の陣Part 1はFLUX.2 [dev]でローカル生成(西川和久) 画像](/imgs/p/KS0xA70UphpJ5g7PcXQyhA2bwJXOlZSTkpGQ/28690.jpg)















