





この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第134回)は、GPT-5-miniを上回る「Qwen3.5」の軽量モデル群や、国立国会図書館が発表した家庭用PCで使える無料OCRツール「NDLOCR-Lite」を取り上げます。
また、生成速度が従来の5倍以上高速な拡散ベースのLLM「Mercury 2」や、1100万時間分の動画で学んだPC操作AIモデル「FDM-1」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、ローカルで起動できるリアルタイム文字起こしAI「Moonshine Voice」を別の単体記事で取り上げています。
アリババが「Qwen3.5」のローカル軽量モデル4つを発表。GPT-5-miniやClaude Sonnet 4.5を上回るモデルも
アリババのQwenチームが「Qwen3.5」の軽量モデルを4つ発表しました。
ラインアップは「Qwen3.5-35B-A3B」、「Qwen3.5-27B」、「Qwen3.5-122B-A10B」、そしてホスティング版の「Qwen3.5-Flash」の4つです。Flashはデフォルトで100万トークンのコンテキスト長とビルトインツールを備えています。
目玉はQwen3.5-35B-A3Bで、総パラメータ350億のうち実行時に30億だけ活性化するMoEモデルでありながら、前世代の大型モデルQwen3-235B-A22Bを多くのベンチマークで上回っています。ビジョン言語タスクでもGPT-5-miniやClaude Sonnet 4.5を上回る領域が多く、エージェント系ベンチマークでも高いスコアを記録しています。

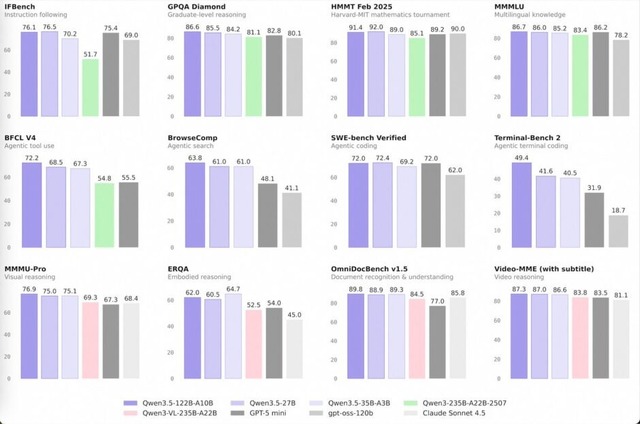
Qwen3.5-35B-A3B
Qwen team
Hugging Face
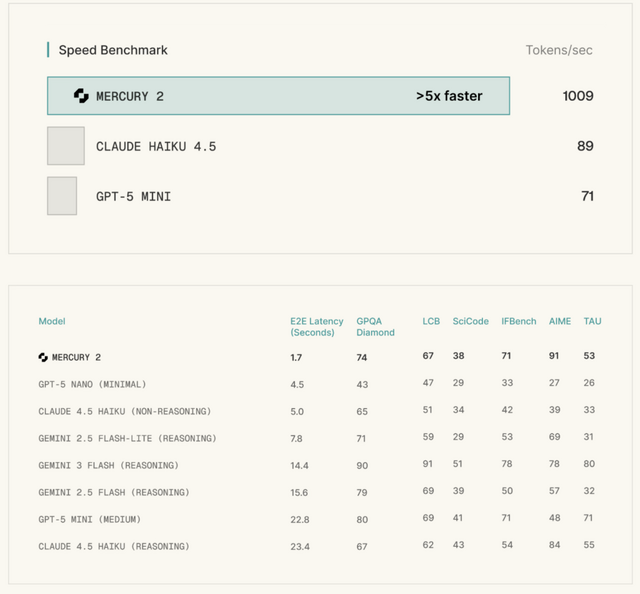
世界最速を謳う、生成速度が従来の5倍以上高速な拡散型LLM「Mercury 2」登場
Inceptionは、最速の推論性能を持つという拡散型LLM「Mercury 2」を発表しました。
従来のLLMは、左から右へ1トークンずつ順番にテキストを生成する自己回帰型のアーキテクチャを採用しています。これに対しMercury 2は、拡散(Diffusion)モデルをベースにしたアーキテクチャを採用しています。
これにより、複数のトークンを同時に生成して一気に推敲するようなアプローチが可能となり、従来比で5倍以上の高速化を実現しました。パフォーマンス面では、NVIDIA Blackwell GPU上で毎秒1,009トークンという処理速度を記録しています。
価格は入力100万トークンあたり0.25ドル、出力100万トークンあたり0.75ドルに設定されています。さらに、128Kのコンテキストウィンドウやネイティブなツール呼び出し、JSON出力といった実用的な機能も備えています。

1100万時間分の動画で学んだPC操作AIモデル「FDM-1」登場。CADやWeb探索、車両操作などに応用
Standard Intelligenceは、動画データから次に取るべき行動を直接予測できる、PC操作のためのAIモデル「FDM-1」を発表しました。
このモデルは30FPSの動画から直接学習・推論を行い、CADモデリングやウェブサイトの探索、現実世界での車の運転といった複雑なタスクを自律的にこなすことができます。
このモデルを支えているのは、独自に開発された2つの技術です。1つ目は、約2時間の動画をわずか100万トークンに圧縮できるビデオエンコーダです。2つ目が、動画内のマウスやキー操作を自動で推論してラベル付けする逆ダイナミクスモデル(IDM)です。
これまでAIエージェントの訓練には、人手による高コストなデータ作成が必要不可欠でしたが、IDMの導入により、1100万時間分もの膨大な動画データをそのまま学習に活用できるようになりました。
FDM-1
Neel Redkar, Yudhister Kumar, Devansh Pandey, Galen Mead
Blog
国立国会図書館、GPU不要かつ家庭用PCで動作するAI基盤のOCRツール「NDLOCR-Lite」を無償公開
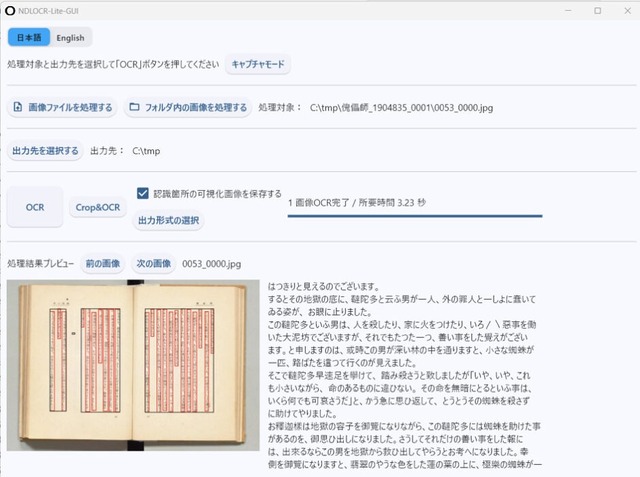
国立国会図書館(NDL)ラボは、一般的な家庭用のパソコン環境で手軽に利用できる軽量版OCRソフトウェア「NDLOCR-Lite」を公式GitHubにて公開しました。
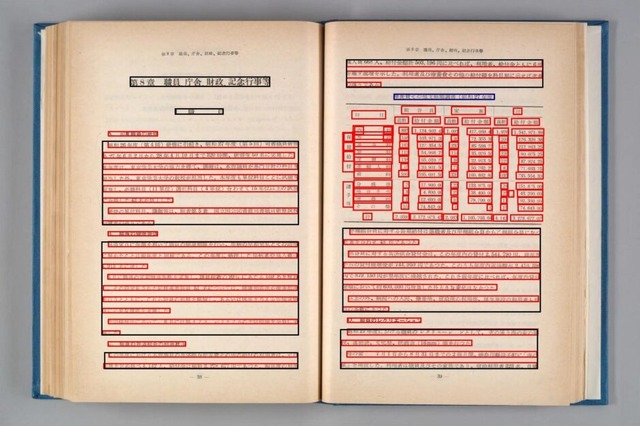
これまで提供されていたNDLOCRの利用には、高度な画像処理を行うGPUが必須でしたが、今回リリースされたLite版はGPU不要で動作するのが特徴です。Windows 11、macOS Sequoia、Linux(Ubuntu 22.04)に対応しており、デスクトップアプリケーションが用意されているため、マウス操作のみで図書や雑誌の画像から文字起こし(テキスト化)が可能です。
機能面では、画像1枚ずつの処理やフォルダ内の複数画像の一括処理ができるほか、画像内の特定範囲だけを指定する「Crop&OCRモード」や、PC画面上の任意の範囲を直接読み取る「キャプチャモード」などの機能を備えています。また、従来は不得意としていた英文や手書き文字にも実験的に対応しました。
NDLOCR-Liteは、レイアウト認識にDEIMv2、文字列認識にPARSeqというディープラーニングモデルを使用しています。
本ソフトウェアはCC BY 4.0ライセンスのもと無償で公開されています。