またもや標的にされてしまいました。前回の記事から中2日。Reidisの作者であるantirezが開発したDeepSeek V4 Flash専用推論エンジン『ds4(DS4)』が大幅に進化していました。試さないといけないやつが出てきてしまったのです。今度はNVIDIAの超小型AIスーパーコンピュータDGX Spark(互換機)で。
プロジェクト名が『DwarfStar 4』に変わり、CUDA対応が入り、新機能が3つ4つ追加されている、というハイペースでの更新。いったいどこが変わったのか、実機で検証していきます。
何が変わったか
git log を辿ると、前回から最新までの間にコミットが20本以上積まれ、ファイル数では4万1630行の追加 / 3890行の削除という規模で書き換わっていました。主な変化は次の通りです。
項目 | 前回 | 今回 |
プロジェクト名 | ds4 | DwarfStar 4(READMEは『DrawfStar 4』とtypoしています…) |
対応バックエンド | Metal専用 | Metal / CUDA / CPU の3系統。ds4_gpu.h で抽象化 |
ARM64 Linux | 対象外 | sbsa-linux ターゲットを明示。DGX Spark向け |
量子化のバリエーション | q2 / q4 | q2 / q2-imatrix / q4(imatrixは精度向上版) |
最低メモリ | 128GB を強く推奨 | 96GB機での動作報告も明文化 |
新ベンチマークツール | なし | ds4-bench:コンテキスト境界スイープ型計測 |
新機能:指向性ステアリング | なし | 推論時アクティベーション操作で出力長・スタイル制御 |
新機能:サーバープリフィル進捗 | なし | 2,048トークン毎にチャンク%・t/sを server.log に出力 |
I Promessi Sposi | なし | Manzoniの伊小説をベンチ用に同梱(イタリア人のantirezらしい選択) |
The optimized graph path targets Metal on macOS and CUDA on Linux. The CPU path is only for correctness checks and model/tokenizer diagnostics. ― README より
「Metal専用」でなくなったのは最大の転換点です。
Apple Silicon Macで普通に動き、CUDAでも動き、必要であれば CPU でも動かせる(macOSのVMバグの問題はあるものの、Linux CPUはOK)。対応モデルは依然としてDeepSeek V4 Flashだけですが、それを動かせる場所がいきなり広がりました。
CUDA対応が指す先、DGX Spark
Makefileを読むと面白いことに気づきます。CUDA関連のリンカパスが `-L$(CUDA_HOME)/targets/sbsa-linux/lib` を指している。sbsa は『Server Base System Architecture』の略で、ARM64サーバ向けの仕様です。つまりantirezは、x86_64でもAArch64 Linuxを最初から想定して書いていた。
そして現在、ARM64 Linux + Nvidia GPU という組み合わせで一般人が買えるマシンは事実上ひとつしかありません──NVIDIA DGX Sparkとその互換機です。
筆者はDGX Spark互換機であるASUS Ascent GX10を持っていて、今回の検証ではこのマシンもターゲットに含めました。スペックは次の通り:
項目 | M4 Max MacBook Pro | DGX Spark |
CPU/SoC | Apple M4 Max | NVIDIA GB10 (Grace ARM + Blackwell) |
ユニファイドメモリ | 128 GB | 128 GB(121 GiB available) |
GPU | Apple GPU(Metal) | NVIDIA GB10(CUDA sm_120, CC 12.1) |
OS | macOS 26.5 | Ubuntu 26.04 (kernel 6.17-nvidia) |
CUDA | ― | 13.0.88 |
バックエンド | Metal | CUDA |
ビルドの体験
M4 Max側は `git pull && make clean && make -j` で再ビルド。前回と同じく10秒以内に完了し、`ds4` `ds4-server` `ds4-bench` の3バイナリが出ました。
DGX Sparkでは `nvcc` のパスを通すだけで即ビルドが通りました。
# DGX Spark側
git clone https://github.com/antirez/ds4.git
cd ds4
export PATH=/usr/local/cuda-13.0/bin:$PATH
export CUDA_HOME=/usr/local/cuda-13.0
make # ds4 / ds4-server / ds4-bench がCUDAでビルドされる
CUDA 13.0 / nvcc 13.0.88 で `-arch=native`、CUDA Architecture 12.1 としてコンパイル。コンパイル時間はM4 Maxよりかなり長く(CUDA kernelのコンパイルは重い)、1~2分程度。ただし手順は驚くほど単純で、ハマりどころはありませんでした。「Linuxのビルドの方が綺麗に通った」というのは、AppleとNvidiaの間でローカル推論の足場が均されつつあることを示しているように感じます。
M4 Max:コンテキスト境界スイープベンチ
新ツール ds4-bench は、2,048トークン境界ごとに prefill と generation を別々に測ってくれます。これで「長文脈になるほど遅くなる」現象を曲線として可視化できます。プロンプトには同梱の『I Promessi Sposi』(マンゾーニのイタリア古典)を使いました。
./ds4-bench --prompt-file bench/promessi_sposi.txt \
--ctx-start 2048 --ctx-max 32768 --step-incr 4096 \
--gen-tokens 64 --csv m4max.csv
コンテキスト | Prefill | Generation |
2,048 | 315.0 t/s | 26.3 t/s |
6,144 | 250.9 t/s | 24.8 t/s |
10,240 | 232.7 t/s | 24.1 t/s |
14,336 | 223.2 t/s | 23.4 t/s |
18,432 | 216.6 t/s | 23.6 t/s |
22,528 | 213.0 t/s | 23.0 t/s |
26,624 | 202.0 t/s | 21.8 t/s |
30,720 | 176.9 t/s | 17.7 t/s |
32,768 | 144.6 t/s | 13.7 t/s |
観察できる傾向
2K → 32K と context が伸びるほど prefill は緩やかに低下(315 → 145 t/s 程度)。MoEの圧縮KVがあるとはいえ、attention の計算量自体は伸びます。
Generation は 24~26 t/s で安定的に推移していたが、30K境界を超えるあたりで急に 17.7 → 13.7 t/s と低下。これは熱的な要因と、KVキャッシュサイズが475MBに達したことのアクセスコストが効いていると思われます。
前回のチャット時のシンプルプロンプトでは『生成31 t/s』が出ていたが、ベンチ条件(greedy、定型、ノーキャッシュヒット)では実行的に24~26 t/sが定常域。
DGX Spark:CUDAビルドで初検証
DGX Spark側では q2-imatrix(imatrix版2-bit量子化)の方をダウンロードして測りました。これは前回のq2と比べて、量子化エラーが小さい改良版です。
コンテキスト | Prefill | Generation |
2,048 | 176.4 t/s | 13.3 t/s |
6,144 | 288.0 t/s | 10.5 t/s |
10,240 | 200.3 t/s | 10.4 t/s |
14,336 | 254.6 t/s | 10.0 t/s |
18,432 | 255.7 t/s | 10.8 t/s |
22,528 | 225.5 t/s | 12.7 t/s |
26,624 | 273.7 t/s | 12.5 t/s |
30,720 | 250.3 t/s | 12.3 t/s |
32,768 | 246.7 t/s | 12.2 t/s |
なお、DGX Spark で最初に起動したときは「CUDA set device failed: out of memory」で立ち上がりませんでした。これは GB10 のユニファイドメモリ 121 GiB のうち、既存のCUDAアプリ(筆者の場合 ACE-Step 音楽生成APIで16.9 GiB、別の `server.py` で4.4 GiB を確保していた)の合計 21 GiB を引いた 残り93 GiB に対して、ds4の 81 GiB GGUF+ コンテキストバッファが乗り切らず敗北したものです。
厄介なのは、その過程でCUDAアプリのスワップスラッシングが激化し、tailscaledまでOOM-killedされてマシンが事実上ロックした点です。DGX Sparkに284B-MoEを乗せるときは、事前に他のCUDAアプリは止めるのが実質的な前提条件です。
筆者はこのため、物理リスタートをかける羽目になりました。
M4 Max と DGX Spark、横並びで見る
同じ DwarfStar 4 / 同じ DeepSeek V4 Flash q2-imatrix(モデル違いはimatrixだけ)/ 同じプロンプト系列で並べると、各機の得意分野が見えてきます。
ctx | M4 Prefill | DGX Prefill | M4 Gen | DGX Gen |
2,048 | 315.0 | 176.4 | 26.3 | 13.3 |
6,144 | 250.9 | 288.0 | 24.8 | 10.5 |
10,240 | 232.7 | 200.3 | 24.1 | 10.4 |
14,336 | 223.2 | 254.6 | 23.4 | 10.0 |
18,432 | 216.6 | 255.7 | 23.6 | 10.8 |
22,528 | 213.0 | 225.5 | 23.0 | 12.7 |
26,624 | 202.0 | 273.7 | 21.8 | 12.5 |
30,720 | 176.9 | 250.3 | 17.7 | 12.3 |
32,768 | 144.6 | 246.7 | 13.7 | 12.2 |
この表から。違いが明確にわかります。
Generation は M4 Max が概ね2倍速い(M4 Max 22~26 t/s、DGX Spark 10~13 t/s)。これはほぼメモリ帯域の差そのものです:M4 Max が 546 GB/s、GB10 が 公称 273 GB/s。Generation はトークン1個ごとに重み全部を読み直すので、ほぼ純粋に帯域で決まります。M4 Max の Apple GPU が CUDA に勝っているのではなく、Apple SiliconのLPDDR5X実装の帯域が、GB10の倍ある、というだけの話です。
Prefill は長コンテキストになるほどDGX Sparkが伸びます。短い 2K では M4 Max が圧倒(315 vs 176 t/s)ですが、10K を超えたあたりからDGX Sparkが追い抜き、32K の Prefill では DGX Spark 247 t/s vs M4 Max 145 t/s で、ほぼ70%差をつける場面も。Prefill は並列で重み×コンテキスト全体を回す行列演算なので、計算能力が支配的。Blackwell GPUの素のテンソルコア性能が、ここで効いていると考えられます。
M4 Max は短コンテキストで「とにかく速い」、DGX Spark は長コンテキストで「最後まで失速しない」、という性格の違いになって表れています。32K で M4 Max の Generation が 13.7 t/s まで落ちるのに対し、DGX Spark は 12.2 t/s でほぼ同じ。むしろ DGX Spark の方がコンテキスト依存性が少ない、つまり長文ワークロードに向いている挙動と言えます。
結論としては、用途次第ということですね。チャットや短いコード補完は M4 Max が快適、長いコードベースに対する読解・解析や、25k+トークンのエージェントは DGX Spark の方が安定するはずです。
DwarfStar 4 が両方に対応したことで、初めてこの比較が同じエンジン・同じモデルで成立した、というのが大きな意味だと思います。
どっちも持っている人は両方使えます。
新機能その1:Directional Steering(指向性ステアリング)
推論時に各層の活性化を、事前に作っておいた『方向ベクトル』に沿って編集することで、出力のスタイル(簡潔さ/冗長さなど)を制御する仕組みです。数式上は、各層で
y ← y - scale × direction[layer] × (direction[layer]・y)
という活性化操作を入れるだけ。実装は薄く、推論コストもほぼ増えません。
リポジトリには verbose/succinct ペア100本から作った verbosity 方向ベクトル(704,512 bytes = 43層 × 4096次元 × f32)が同梱されています。同じプロンプトで scale を変えて出力を比較しました(temperature=0、greedy)。
条件 | 出力の特徴 |
baseline(ステアリングなし) | 中程度の長さ。Markdown構造あり。phone bookのアナロジーで例示 |
--dir-steering-ffn -1.5(簡潔側) | 3文で完結。アナロジー1個。120トークンに収まる |
--dir-steering-ffn +2(冗長側) | セクション複数、目次風の長文構成。220トークンでも書ききれず途中で切れる |
同じモデル、同じ温度、同じ乱数で、出力の長さと文体がここまで変わります。プロンプトエンジニアリングで「簡潔に答えて」と書く代わりに、**モデル本体に直接スイッチを掛ける**やり方です。実用面では、エージェントの応答長を一律に締めたり、Reasoning モデルの thinking 部の冗長さを抑えたり、といった用途が考えられます。
新機能 その2:プリフィル進捗の可視化
ds4-server が長プロンプトを処理している間、何が起きているかが見えるようになりました。5,000トークン級のプロンプトを投げたときの server.log は次の通り:
0512 07:27:40 ds4-server: chat ctx=0..4983:4983 prompt start
0512 07:27:40 ds4-server: chat ctx=0..4983:4983 prefill chunk 0/4983 (0.0%)
0512 07:27:46 ds4-server: chat ctx=0..4983:4983 prefill chunk 2048/4983 (41.1%) chunk=333.63 t/s
0512 07:27:54 ds4-server: chat ctx=0..4983:4983 prefill chunk 4096/4983 (82.2%) chunk=265.96 t/s
0512 07:27:58 ds4-server: chat ctx=0..4983:4983 prefill chunk 4983/4983 (100.0%) chunk=206.46 t/s
0512 07:27:58 ds4-server: chat ctx=0..4983:4983 prompt done 18.714s
2048トークン境界ごとに、進捗率と直近チャンクのスループットが出ます。Claude Code から25kトークンのシステムプロンプトが飛んでくるような状況で、サーバ側が「何秒経過したか、残り何%か」を即時報告するのは、プロダクション運用としては地味ですが本質的に大事な機能です。
新機能 その3:q2-imatrix(改良版2-bit量子化)
従来の q2(IQ2_XXS)は重みの importance ベクトルだけで作られていましたが、新しい q2-imatrix は antirezが自前で生成した imatrix を使って量子化誤差を小さくしたバージョンです。READMEには「q4 との logits 差が小さい」と書かれており、logits品質が q4 に近づいた、というのが彼の主張です。
ファイルサイズは q2 とほぼ同じ81GB、ディスク容量の要件は変わりません。DGX Spark側ではこちらをダウンロードして検証しました。
そのほかの変更
CPU バックエンドは Linux ではビルド可能(`make cpu`)。macOSはVMバグの注意書きが残りますが、Linux CPU パスは新たな実用候補。こちらで有用でコスパの高いものが出てきたりしないですかね。AMDの新しいAIマシンとか。
ds4_metal.h は ds4_gpu.h にリネームされ、Metal/CUDA を抽象化する共通の GPU インタフェース層になりました。今後 ROCm などへの拡張余地が残されています。がんばれ、ROCm陣営。
サーバ側で『thinking checkpoint rebuild on length stop』『tool calls の DSML 再正規化』など、エージェント連携まわりの細かい不具合修正が多数。Anthropic互換 `/v1/messages` の品質は確実に上がっています。
`tools/run_sweep.py` でスケール値のスイープ実験まで自動化。ステアリング機能はおもちゃではなく、実験ツールとして使う想定で作られています。
mazzai統合への影響
前回、自作エージェンティックAIであるmazzai に組み込んだ ds4 ディスパッチは、サーバ側のAPIが OpenAI/Anthropic 互換のままなので、コードを変更せずにそのまま動きました。`/api/models` で `deepseek-v4-flash` が引き続き表示され、`/api/chat` のツール呼び出しループも問題なく貫通します。API契約を変えないままバックエンドを大幅にリファクタしたのは、外部ユーザにとっては嬉しい設計判断です。
ds4-server を停止せずに走らせ続けたい場合は、`make clean && make` でバイナリを更新してから一度サーバを再起動する、という運用で問題ありません。KVキャッシュは header にバージョン情報を持っているので、バージョン跨ぎのキャッシュは安全に拒否されます。
プロジェクトは加速中
中2日でこれだけの変化──CUDA対応、ステアリング、imatrix、ベンチツール、プリフィル可視化、プロジェクト改名──を入れて来るペースは、OSSプロジェクトとしてはかなり速い部類です。
今回特に大きいのは『CUDA対応によりLinux ARM64でも動く』ようになった点です。DGX Spark のような新世代のローカル推論マシンにとって、antirez 印の DeepSeek V4 Flash 専用エンジンが選択肢に入る、というのは想像以上にインパクトがあります。「あえて狭く賭ける」アプローチが、Apple Silicon にも Grace Blackwell にも通用する設計だったということを、コード自身が証明しています。

次の波で何が来るかわかりませんが、おそらく数日から1~2週間以内にまた大きな更新があるはずです。
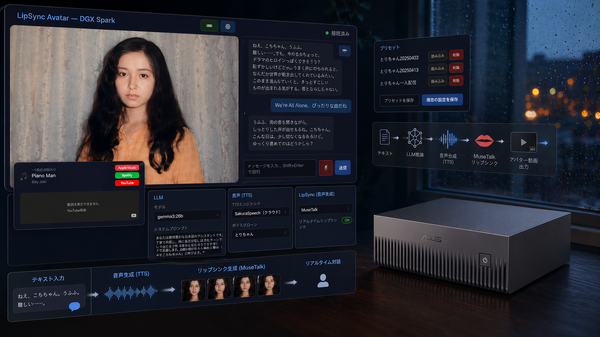
DGX SparkでもDwarfStar 4が使えることがわかったので、このマシン上で動かしている妻のAIアバターシステム「LipSync Avatar」を、DwarfStar 4ベースにする(現在はGemma 4)という挑戦をしてみたのですが、そのためのメモリは128GBでも不足していて、途中でクラッシュさせてしまいました。
DGX Spark互換機、もう1台ほしくなってしまいました。3台はさすがにやりすぎな気はしますが(笑)
(検証環境:MacBook Pro M4 Max 128GB / macOS 26.5 / Metal + DGX Spark compatible ASUS Ascent GX10 / Ubuntu 26.04 / CUDA 13.0 / DwarfStar 4 commit 920f987 / q2 GGUF & q2-imatrix GGUF。検証と執筆はClaude Codeが行い、整理・追記は筆者が行いました)