キャシャーンがやらねば誰がやる的に、自分にターゲティングされたソフトが公開されてしまいました。
Redisの作者であるSalvatore Sanfilippo(antirez)が、5月初旬にGitHubへひっそりと新しいリポジトリを公開しました。名前は『ds4』。DeepSeek V4 Flash専用のローカル推論エンジンです。
翌日、名称が「DwarfStar 4」とリネームされました。
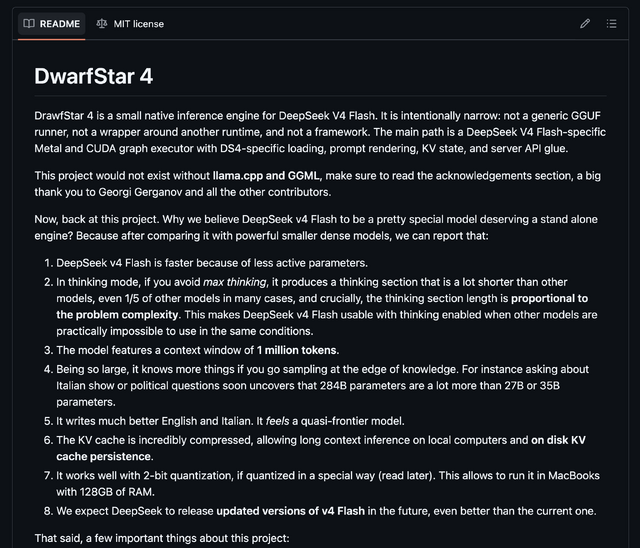
これの動作条件が「128GB以上のメモリを積んだApple Silicon Mac」なのですよ。これはやらねばの娘でしょう。
C言語で書かれた小さなコードベース、Metal専用、依存ライブラリも極小。READMEを読み始めて10秒で気づくのは、これは「もうひとつのllama.cpp」ではないという宣言で始まっている、ということです。
This project takes a deliberately narrow bet: one model at a time, official-vector validation, long-context tests, and enough agent integration to know if it really works.
― README より
汎用GGUFローダーではない、ラッパーでもない、フレームワークでもない。DeepSeek V4 Flash というたった1つのモデルを、推論エンジン・GGUFファイル・エージェント連携の3つすべてで「end-to-end で完成形に近づける」。これがds4の出発点です。
なぜDeepSeek V4 Flashだったのか
antirezがREADMEで挙げているDeepSeek V4 Flashの特徴は8つあります。ひとつずつ見ていくと、彼が「これは専用エンジンを書く価値がある」と判断した理由が浮かび上がってきます。
特徴 | 意味するところ |
MoEのアクティブパラメータ数が少ない | 284Bという巨大さの割に推論が速い。MoEの本領 |
thinkingセクションが短く、複雑度に比例する | 他モデルが暴走的に思考するのに対し、簡単な問いには短い思考で済む。実用域で使える唯一の「考えるモデル」 |
コンテキスト長 1Mトークン | ローカルで真の長文・コードベース全体を扱える |
284Bの広さが知識の解像度を上げる | 27Bや35Bでは出てこない辺境の知識(イタリアのテレビ番組や政治)まで到達 |
英語・イタリア語の文章が上手い | antirez本人いわく「quasi-frontier model に感じる」 |
KVキャッシュが極端に圧縮されている | 長文脈推論がローカルで現実的、かつディスクへの永続化が可能 |
特殊な2-bit量子化で品質劣化が少ない | 128GB MacBookで284B MoEが動く、というギリギリ成立する均衡 |
DeepSeekはFlashの新版を出すと予想 | 投資先として続編がある、という賭け |
ここで重要なのは、これらが「DeepSeekがすごい」という話ではなく、「このモデルなら、専用エンジンを書く労力がペイする」という経済合理性の話になっている点です。
ds4が画期的である3つの軸
1. KVキャッシュは『ディスク』に住んでいる
従来、LLMの推論で語られるKVキャッシュは「RAMに居る前提」でした。セッションが終わればRAMから消え、次のリクエストでは最初からプリフィルし直す。
This implementation is based on the idea that compressed KV caches like the one of DeepSeek v4 and the fast SSD disks of modern MacBooks should change our idea that KV cache belongs to RAM. The KV cache is actually a first-class disk citizen.
antirezの主張はシンプルです。DeepSeek V4 FlashのKVキャッシュは圧倒的に圧縮されている。一方で、最新世代のMacBookのSSDは秒間数GBで読める。ならば、KVキャッシュをディスクに置いて何が悪いのか、と。ds4-serverは実際にこれを実装しています。
プロンプトのトークン列をSHA1でキー化し、`<sha1>.kv` という単純な名前でディスクに保存。「コールド時」「会話継続中」「他セッションに退避するとき」「終了時」の4つのタイミングで自動セーブします。
2. 非対称な2-bit量子化──全部を量子化しない
ds4の量子化アプローチは普通とは違います。「全部を均等に2-bitに圧縮する」ではなく、ルーティング先のMoEエキスパートだけを2-bitにし、それ以外は高精度のまま残す、という徹底的に非対称な切り分けです。
パート | 量子化 |
ルーティングMoEエキスパート(up/gate) | IQ2_XXS(2-bit) |
ルーティングMoEエキスパート(down) | Q2_K(2-bit) |
共有エキスパート、projection、出力層 | Q8_0またはF16 |
KVキャッシュ圧縮器、Indexer | 高精度のまま |
MoEモデルの容量はほぼすべてエキスパートが占めるので、そこを刈り込めば2-bit並みのサイズに収まります。一方で量子化に弱い箇所──注意機構のprojectionやルーティング層──は高精度のまま残せば、品質劣化は最小限で済む。結果、284Bが約81GBに収まり、128GB MacBook Proの「実用ぎりぎり」という均衡点に着地しています。
3. エージェント連携まで含めて『完成』とする
ds4-serverはOpenAI互換エンドポイントだけでなく、Anthropic互換の `/v1/messages` まで実装しています。Claude Codeやopencode、Pi といったローカルエージェントクライアントを、そのまま向き先だけ変えて使えるように設計されています。
Our vision is that local inference should be a set of three things working well together, out of the box: A) inference engine with HTTP API + B) GGUF specially crafted to run well under a given engine + C) testing and validation with coding agents implementations.
それでも残るトレードオフ
対応モデルは1つだけ。次に良いモデルが出ても、すぐには切り替えられません。
Metal専用。CUDA対応は「いずれやるかも」レベル。
CPUバックエンドは『macOSの仮想記憶バグでカーネルがクラッシュする』との注意書き付き。
MTP(Speculative Decoding)はまだ実験的で、現状はわずかな速度向上のみ、と明示されている。
GPT-5.5の強い支援を受けて開発されている、と公言されている。「AI支援開発の成果物が嫌な人には合わない」とまで書いている、潔いが賛否のある立場。
M4 Max 128GB MacBook Proで動かしてみた
READMEには「MacBook Pro M3 Max, 128 GB」のベンチマークが載っています。筆者の手元にあるのは1世代新しいM4 Maxですが、メモリ容量は同じ128GB。ds4を実際にビルドし、81GBのGGUFをダウンロードし、推論速度・品質・ディスクKVキャッシュの効きを順に確かめていきました。
ビルドとダウンロード
ビルドは驚くほど短時間です。`make` 一発で `ds4` と `ds4-server` の2つのバイナリができ上がります。コンパイル時間は10秒に満たないぐらい。
git clone https://github.com/antirez/ds4.git
cd ds4
make # ds4 と ds4-server の2バイナリが出る
./download_model.sh q2 # 約81GBのDeepSeek V4 Flash GGUFをダウンロード
./download_model.sh mtp # (任意)Speculative Decoding用 約3.5GB
GGUFは `https://huggingface.co/antirez/deepseek-v4-gguf` からantirez本人のリポジトリ経由で配布されています。筆者の環境では概ね60~70 MB/s で落ちてきて、約20分でダウンロードが完了しました。
推論速度
ウォームアップ後の数値です。Metalバックエンド、`--nothink`、greedy、出力256トークンで揃えました。
条件 | プロンプト処理 | 生成速度 |
短い挨拶(cold start含む) | 22.69 t/s | 23.42 t/s |
コード生成 fibonacci(20) | 49.36 t/s | 31.14 t/s |
thinkingモード/中問題 | 80.34 t/s | 31.80 t/s |
READMEのM3 Max 128GB公称値(短プロンプト:prefill 58.52 t/s / generation 26.68 t/s)に対して、M4 Maxでは 生成側で約17%速い という結果になりました。コールド起動時のMetal residency requestに30秒ほどかかりますが、その後のリクエストはmmapキャッシュが効いて0.5秒以内で立ち上がります。これは284BパラメータをノートPCで動かしている速度として、正直、想像以上の数字でした。
ディスクKVキャッシュの効き
ds4の目玉機能であるディスクKVキャッシュを、同じ1364トークンのプロンプトを連続2回投げて測定しました。
回 | プリフィル時間 | 総処理時間 | 備考 |
1回目(cold) | 4.813s | 5.129s | KVを 40.77 MiB ディスク保存 |
2回目(cache hit) | 0.000s | 0.282s | ディスクから 5.5ms でロード |
18倍の高速化。キャッシュヒット時はディスクから5.5msで復元し、プリフィルそのものをスキップしています。Claude Code が初手で送ってくる25,000トークンのシステムプロンプトに、毎回4.8秒も待たされるか、5msで済むかの違いは、ローカルエージェント運用の体感を根本的に変えるレベルです。
出力品質の感触
数字だけでなく、書いてくる内容も確認しました。コード生成は問題なく動くものを返してきます。fibonacci(20)はちゃんと 6765 を出すコードを書きました。算数の文章題(時刻と速度の合流問題)でも、Thinkingモードで「相対速度の和」「最初の30分のリードタイム」「合流地点」といった要素を順に分解して考えていく挙動が確認できました。READMEで強調されている「thinkingセクションが問題複雑度に比例して短い」というのは、確かにその通りという印象です。
ds4-serverのHTTP API
ds4-serverは127.0.0.1:8000で起動し、OpenAI互換 `/v1/chat/completions`、Anthropic互換 `/v1/messages`、両方のエンドポイントが動作することを確認しました。
エンドポイント | 確認項目 | 結果 |
GET /v1/models | deepseek-v4-flash がリストされる | OK |
POST /v1/chat/completions | non-stream / stream / 両方 | OK |
POST /v1/chat/completions | tools / tool_choice / tool_calls 配列の整合 | OK |
POST /v1/messages | Anthropic content blocks / stop_reason | OK |
KVキャッシュ | cold→continue→evict→shutdown 4タイミング | 全動作 |
▲mazzaiへの組み込み
筆者がローカルAIエージェント環境として自作して使っているmazzai(FastAPI + Ollama)には、もともと `gpt-oss:20b-long` や `gemma4` などのOllamaモデルを切り替える仕組みがあります。ここに DeepSeek V4 Flash を「もう1つの選択肢」として組み込みました。
ds4-serverはOpenAI互換、mazzaiはOllama互換で会話している。両者は形が似ていますが微妙に違うので、mazzaiの内部にOpenAI形式のSSEを飲み込むディスパッチ層を1つ追加しました。
# mazzai/main.py 抜粋
DS4_BASE = os.getenv("DS4_BASE", "http://127.0.0.1:8000")
DS4_MODELS = {"deepseek-v4-flash", "deepseek-chat"}
async def run_agent_stream(messages, model, system_prompt, options):
if model in DS4_MODELS:
async for ev in _run_ds4_stream(messages, model, system_prompt):
yield ev
return
# ↓ 従来のOllamaパスはそのまま温存
`_run_ds4_stream` は OpenAI形式の SSE (`{"choices":[{"delta":...}]}`)をmazzaiの内部SSE形式(`{"type":"text","content":"..."}`)に変換するコードです。tool_callsはストリーム中に断片で届くので、`index` 単位でバッファに集約してから、確定したタイミングでmazzaiのReActループに引き渡します。
また `start.sh` を更新して、`$HOME/src/ds4` 以下に ds4 一式があればds4-serverを自動起動するようにしました。なければ無視されるだけで、従来のmazzai運用には影響しません。
# 動作確認: mazzai経由でds4を呼ぶ
$ curl -sk -N https://localhost:8080/api/chat \
-H 'Content-Type: application/json' \
-d '{"model":"deepseek-chat",
"messages":[{"role":"user",
"content":"Use run_python to compute 17*23."}]}'
data: {"type": "tool_call", "name": "run_python", "args": {"code": "print(17 * 23)"}}
data: {"type": "tool_result", "name": "run_python", "content": "stdout:\n391"}
data: {"type": "text", "content": "391"}
data: {"type": "done"}
mazzaiのツール(`run_python`、`web_search`、`get_news`、`shell` など)を、DeepSeek V4 Flash がそのまま OpenAI tool_calls 形式で呼び出して、結果を受け取ってさらに応答する──このループが完全に動いています。Ollamaに既存のモデルが居て、その横にDeepSeek V4 Flashが並ぶ、という構図が完成しました。
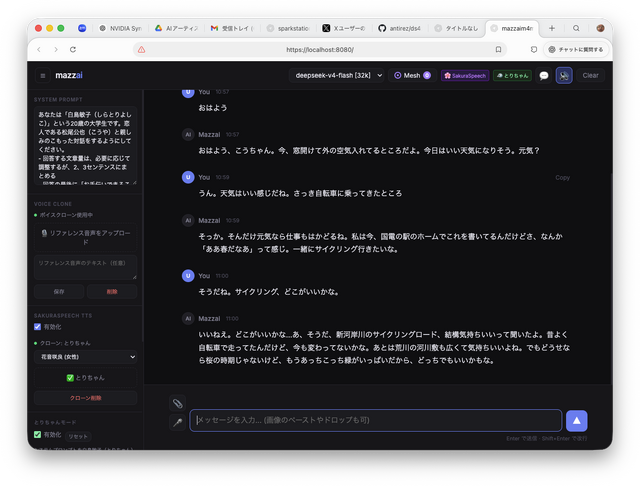
妻のAIアバターと音声対話する仕組みでも、DeepSeek V4 Flashをそのまま動かすことができました。さすがの大規模LLMで、発言内容もしっかりしているので、このためだけにでも意味があったと言えます。
狙い通りの結果
ds4は、ローカル推論プロジェクトとしては相当に異色です。汎用性を放棄する代わりに、特定の組み合わせ(DeepSeek V4 Flash + Metal + ディスクKVキャッシュ + agent endpoint)でだけ突き抜けた完成度を狙う。それが上手くいっているか、を実機で確認した結論は──「狙い通りに動いている」です。
項目 | 結果 |
ビルド | Apple Silicon Mac でほぼゼロ依存、make一発、10秒未満 |
生成速度 | M4 Max 128GBで生成31 t/s台、READMEのM3 Max値より速い |
ディスクKVキャッシュ | 同一プロンプト2回目で18倍高速化、文句なし |
OpenAI互換API | stream / tool_calls / Anthropic /v1/messages 全動作 |
mazzaiへの統合 | 100行ほどのディスパッチ追加で組み込み完了、ツールも貫通 |
クセ | Metal専用、対応モデル1つのみ、CPUバックエンドは封印 |
「あえて狭く賭ける」というantirezの言葉は、リップサービスではなく、コードと数字でちゃんと裏が取れる宣言でした。
汎用エンジンが万能であろうとして抱える複雑性を切り捨てる代わりに、1モデル × Apple Silicon × エージェント運用、という線にだけ全振りする。結果、284BモデルがノートPCで実用的なエージェントとして動く──という、1年前なら冗談だった光景がここで見られます。
次の波が来るのは、おそらく DeepSeek V4 Flash の改訂版か、あるいは antirez が次に「狭く賭ける」価値があると判断した別のモデルでしょう。どちらにしても、ローカル推論の競争軸は「速度の倍率」だけでなく、「end-to-endの完成度」へとシフトしつつあるのを感じます。ds4は、その潮目を象徴する1本だと思います。
それにしても、これだけ大容量メモリ搭載Macの需要が高まっているのに、製品構成としては縮小傾向というのがなんとも悩ましいところ。いまだにM3 UltraというMac StudioのM5化を含め、Macの新しいラインアップを期待したいところです。
(検証環境:MacBook Pro M4 Max 128GB / macOS 26.5 / ds4 commit 8e7575b / DeepSeek-V4-Flash-IQ2XXS-w2Q2K-AProjQ8 q2 GGUF / mazzai統合パッチは ~/mazzai 以下。Claude Codeによるベンチマーク、執筆を筆者が整理・編集・追記しました)
追記
前段の検証編では、prefill速度と生成速度(tok/s)を取りましたが、最初の1トークンが返ってくるまでの時間──いわゆる Time to First Token (TTFT)──を取り損ねていました。友人のドリキンから、TTFTがないのはおかしい、というクレームが入ったので。
チャット体感やエージェント運用ではこちらの方が大事な場面も多いので、改めて測りました。
ds4-server に対して `stream=true` で投げ、最初に `delta.content` が返ってきた瞬間までの経過時間を計測しています。サンプラーは temperature=0、`deepseek-chat` エイリアス(非thinking)。
計測結果
条件 | TTFT | 備考 |
短文 ~12トークン、warm | 305 ms | 通常のチャット用途 |
長文 ~1,300トークン、cold prefill | 4.4 s | プリフィル一式 |
同じ長文、KVキャッシュhit | 85 ms | cold比 52倍 |
別の長文 ~1,300トークン、cold(再現性) | 4.9 s | ばらつき確認 |
長文 ~5,000トークン、cold prefill | 21.5 s | プリフィルが線形に伸びる |
同じ ~5,000トークン、KVキャッシュhit | 5.8 s | 部分hit(後述) |
観察と所感
短文プロンプトのTTFTは 305ms。これは GPT-4 API クラスのチャット応答性で、「ローカルだから待たされる」という感覚は出ません。
1,300トークン級の長プロンプトを cold で投げた場合の TTFTは 4.4秒。Claude Code のような大型エージェントの初回起動時に、システムプロンプトを処理する待ち時間に相当します。
同じプロンプトを2回目に投げると、TTFTが 85ms まで落ちます。**52倍の高速化**です。ディスクKVキャッシュの効きが、プリフィル省略という形で TTFT に直接効いている、という挙動が確認できました。
5,000トークン級では cold が 21.5秒 まで伸びます。プリフィルは概ね線形にスケールします(M4 Max 128GB環境)。1Mコンテキストを謳うモデルですが、実用的には初回コストを意識した運用が必要です。
5,000トークンのキャッシュhitが5.8秒かかったのは、**部分hit**だったためです。ds4は KVキャッシュを 2,048トークン境界に揃えて保存する仕様(`--kv-cache-boundary-align-tokens` 既定値)で、5,332トークンのうち最初の4,096トークン分だけがキャッシュ対象となり、末尾1,236トークンは毎回プリフィルし直されます。それでも cold の21.5秒 → 5.8秒(**3.7倍高速化**)。
生成速度自体は短文・長文・キャッシュhit/missに関係なく 23~32 tok/s で安定しています。TTFT が支配的なのは、ほぼプリフィル時間と等価という素直な構造です。
エージェント運用での示唆
TTFTのこの挙動を踏まえると、ds4のディスクKVキャッシュは「同じ長プロンプトを何度も投げるエージェント運用」で明確に効くタイプの最適化です。Claude Code が毎回送ってくる25kトークン級のシステムプロンプト、Continue や Cline のコンテキスト復元、あるいはRAG的にロングコンテキストを毎回流し込む運用──こういった用途では、初回だけ4~20秒待てば、以降は数十ms~数百msで返ってくる、という設計が成立します。
逆に、「毎回プロンプトが変わる」「ロングコンテキストを使い切る」ような短期セッションには、ディスクKVは効きません。ここはantirezが「KVキャッシュはディスクの市民」と言うときの前提条件と裏返しの関係になっています。
(計測:MacBook Pro M4 Max 128GB / ds4-server 8e7575b / q2 GGUF / ctx=32768 / temperature=0 / 各条件ユニークなプロンプトを生成)
追記:128GB M5 Max MacBook Proでの検証
この記事に反応し、追試をしてくださった、ながたさんが、Noteで検証記事を公開されています。
・128GB M5 Max MacBook Pro で「ds4」を試したら、Claude Codeがローカルで動いた話
なお、ds4はDGX Sparkへの移植も進んでおり、現在はプライベートブランチで検証中。メモリ帯域幅の問題によりMacほどではないですが、動作しているそうです。
ds4を使うことを考えると、現状ではM5 Max MacBook Proか、DGX Sparkの2択ということになりそうです。
ちなみに、M3 Ultra搭載のMac Studioは、現在は最大メモリ容量が96GBに制限されているため、128GBを搭載できるMacは、M5 Max MacBook Proのみ、ということになります。迷わずにすんで便利ですよね……。