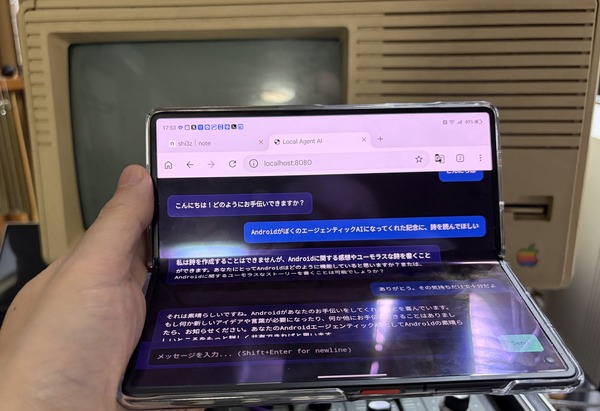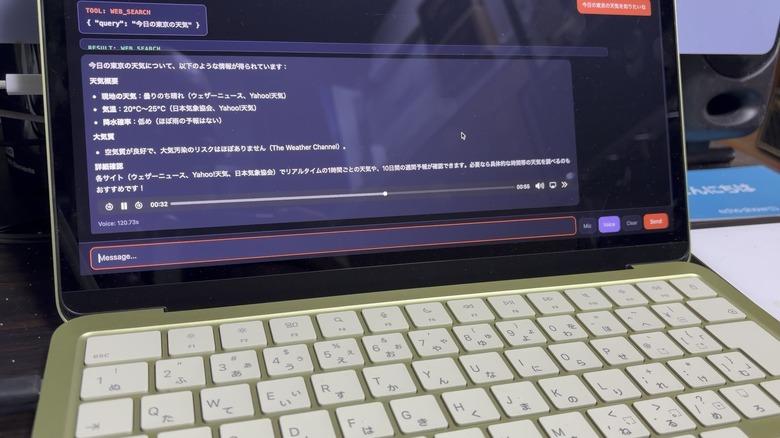


MacBook Neoのローカル上で動かしているエージェンティックAI「mazzaineo」に、新しい機能を2つ追加しました。
mazzaineoは、ボイスクローンによる音声チャット、画像生成、作曲、ビジュアライザーの全てを8GBのメモリしかないMacBook Neoで動かす、筆者が開発中のWebUI AIです。
追加した新機能の1つはブラウザだけで操作を完結させるためのWebターミナル、もう1つはApple SiliconのMLXをネイティブに活用する最新の推論エンジン「SwiftLM」の統合です。
どちらもClaude Codeに実装を任せたのですが、意外なところでハマりました。
ブラウザの中にターミナルを入れた
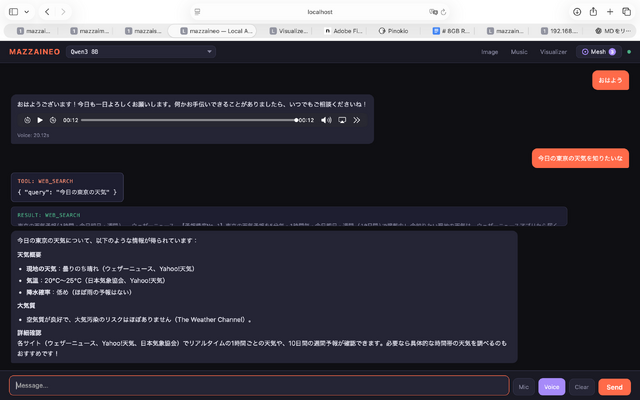
mazzaineoはすべてブラウザのWeb UIから操作できるようになっているのですが、1つだけ不満がありました。Claude Codeをmazzaineoで動かしたいとき、別途ターミナルアプリを立ち上げないといけない。ブラウザだけで完結しないんですよね。
それなら、Web UIの中にターミナルを埋め込んでしまえばいい。
Pythonのptyモジュールで疑似端末を作り、WebSocketで双方向につなぐ。フロントエンドにはxterm.jsを使う……という構成をClaude Codeに実装させると、あっさり動きました。構造としてはこうなります:
Browser (xterm.js) ←── WebSocket ──→ FastAPI ←── PTY ──→ /bin/zsh or claude
クエリパラメータ?cmd=claudeを付けると、シェルの代わりにClaude Codeが直接起動します。「Claude Code」ボタンをワンクリックするだけで、ブラウザの中でClaude Codeが動き始める。これは思ったより便利です。
タブで複数セッションを同時に管理できるようにしてあるので、片方でシェル操作をしながら、もう片方でClaude Codeを動かす、なんてことも普通にできます。Claude Codeから「別のターミナルでこのスクリプトを動かして」という指示が出ることもしばしばあるからです。
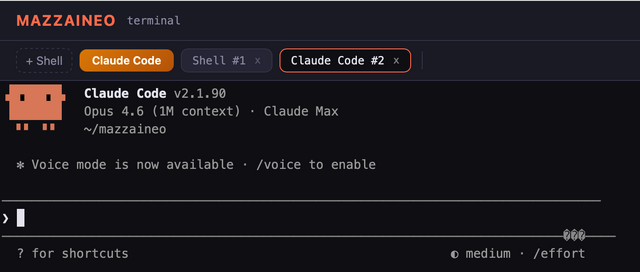
ハマったのは、server.pyにimport asyncioが書いていなかったこと。FastAPIは内部でasyncioを使っているので、明示的にimportしなくても動くだろうと思っていたのですが、asyncio.create_task()を直接呼び出すとNameErrorになりました。よく考えたらそりゃそうか、という話ですが。
音楽生成のACE-Stepも、ボタン1つで起動できるようにした
ついでに気になっていた問題も解消しました。音楽生成に使っているACE-Stepは別プロセスとして起動する必要があり、毎回ターミナルで長いコマンドを打たないといけなかったのです。これをMusic UIの画面に「Start Server」ボタンとして追加してもらいました。
ポイントは、起動時にPYTORCH_MPS_HIGH_WATERMARK_RATIO=0.0を設定してMPSメモリ不足を防ぐことと、音楽生成の直前に他のGPUモデル(画像生成や音声合成)を自動でアンロードしてメモリを空けること。8GBという制約の中でやりくりするには、この「使うときだけ呼び出す」設計が大事です。
やはりメモリ制限のため、1分以上の生成は無理があるのですが、できるということが重要。
SwiftLMという選択肢
LLM推論の高速化も試みました。今日(4月2日)、清水亮さんに教えてもらった、SwiftLMというApple MLXネイティブの推論サーバです。Swift製の単一バイナリで、OpenAI互換のAPIを提供します。より少ないメモリで、より高速にLLMを動かせるかもしれないオープンソースソフトです。
実はここに行き着く前に、同じようなことを期待できそうなオープンソースソフトのHypura、oMLX、Ollamaの最新版であるv0.19.0も試していました。
Hypuraは、Apple Silicon Mac向けのストレージ階層型LLM推論スケジューラで期待していたのですが、8GB RAMのMacBook Neoだとかえって遅くなってしまいました。
MLXフレームワーク上に構築されたLLM推論サーバのoMLXも同じく遅い結果となりました。
Ollama自体もv0.19.0へのバージョンアップでMLXバックエンドを導入しましたが、MLXはモデル全体をメモリに展開する設計です。16GB以上のMacではこれが高速な推論につながりますが、8GBではモデルウェイト(4.7GB)+ KVキャッシュ + 計算バッファがRAMを超過し、macOSのスワップが発生します。SSDへのスワップは桁違いに遅いため、推論速度が劇的に低下します。これもダメ。
一方、llama.cppはmmap(メモリマップトI/O)を活用します。モデルファイルを仮想メモリ空間にマップし、実際にアクセスされたページだけを物理RAMに読み込みます。OSのページキャッシュと協調して動作するため、8GBのような制約された環境でも効率的に動作します。
この時点では、次のような知見が得られました。
8GB RAMでは llama.cpp が最適解
MLXフレームワークはApple Siliconに最適化されていますが、それは「モデル全体がメモリに収まる」前提での話です。8GBという制約下では、mmapベースのllama.cppの方が圧倒的に高速です。MLXの優位性が発揮されるのは16GB以上の環境からです。
モデルサイズの壁は物理的
NVMeストリーミング(Hypura)やMLXの階層キャッシュ(oMLX)は、メモリ超過モデルを「動かす」ことはできます。しかし8GBでは実用的な速度が出ません。8GBマシンでの実用的なモデルサイズの上限はQ4_K_M量子化で約5GBです。
世代の進化は大きい
同じ8Bクラスでも、Qwen 2.5 → Qwen3でアーキテクチャ改良による品質向上は体感できます。パラメータ数を増やせないなら、最新世代のモデルを使うことが最も効果的な最適化です。
Ollama v0.19.0の注意点
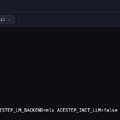
Ollamaのv0.19.0はデフォルトでMLXエンジンを使います。16GB以上のMacでは高速化が期待できますが、8GB環境では`OLLAMA_NEW_ENGINE=false`の設定が必須です。この設定を忘れると推論速度が約8倍低下します。
というふうな試行錯誤を繰り返して、SwiftLMに行き着いたというわけです。
mazzaineoはもともとOllama専用だったのですが、前回の記事で、SwiftLMとApple Intelligence(Foundation Models)も使えるよう、agent.pyをマルチバックエンド構成に書き換えました。モデル名を指定するだけで、自動的に適切なエンドポイントに振り分けられます。

OllamaとSwiftLMはAPIの仕様が微妙に違います。Ollamaがストリーミングに独自のNDJSON形式を使うのに対して、SwiftLMはOpenAI標準のSSE(data: {...})を使う。Tool Callsの受け渡しも少し違う。そのあたりをClaude Codeに実装させると、SSEのパースとtool_callsのチャンク結合もちゃんとやってくれました。
SwiftLMのインストールでひとつ手間取りました。GitHubのリリースページからpre-builtバイナリをダウンロードするのですが、「Failed to load the default metallib」というエラーが出て起動しない。
試したのはこういう順番です:
ソースからビルド → metallibが生成されない(Xcodeフルインストールが必要でCommand Line Toolsだけでは不足)
Python mlx-metalのmetallibをコピー → バージョン不一致でクラッシュ
リリースtarballのpre-built metallibを使う → 動いた
3回目でやっと解決したのですが、実は最初にtarballをダウンロードしたとき、既存の/tmp/SwiftLM/ディレクトリと展開先が衝突して、metallibが9バイトの空ファイルになっていました。別のディレクトリに展開し直したら問題なく動いた。原因がわかってしまえばなんということはないのですが。
なお、バイナリはdefault.metallibと同じディレクトリから実行しないと動きません。これも最初にハマったポイントです。
速くなったのか
SwiftLMとOllamaを同じモデル(Qwen 2.5 3B 4bit量子化)で比較しました。
テスト | SwiftLM | Ollama | 速度比 |
|---|---|---|---|
短い応答(日本語) | 23.7 tok/s | 11.4 tok/s | 2.08x |
中程度の説明 | 24.6 tok/s | 22.5 tok/s | 1.09x |
長いコード生成 | 26.3 tok/s | 22.5 tok/s | 1.17x |
平均 | 24.9 tok/s | 18.8 tok/s | 1.32x |
▲短い応答では2倍以上の差がつきました。平均でも1.32倍速い。
速度よりも8GBマシンで実用上ありがたいのはメモリ効率のほうで、SwiftLMはOllamaより約600MB少ないVRAMで動きます(1,673MB対2,279MB)。この差があれば、ACE-Stepの音楽生成でMPS OOMになる確率が下がります。
初回トークンの時間(TTFT)はOllamaのほうが速いことが多い。これはOllamaがモデルを常駐させているためで、長いプロンプトになるとSwiftLMが逆転します。
MLXがApple SiliconのMetal GPUにネイティブ最適化されているおかげで、汎用設計のllama.cppよりApple固有の最適化で有利になっている、ということなのでしょう。
Webターミナルで「ブラウザだけで完結」できるようになり、SwiftLMで推論が速くなり、mazzaineoはまた少し使いやすくなりました。次のステップとしてはSwiftUIネイティブアプリ化も面白そうですが、それはまた別の話で。
※この記事は、Claude Codeに実行させたタスクを記事形式で書き出すように命じ、そのMDファイルをClaude Sonnet 4.6拡張思考でこの連載スタイルに合わせて再編集。さらに筆者が手を加えたものです。