

いきなりですが、iPhoneアプリ開発者となりました。
筆者は今、浅草橋の極狭オフィスにいます。机の上にあるのは、M2 MacBook Air(24GBのUnified Memory)と、iPhone Air。Air-Airコンビ。
自宅のDGX Spark互換機で動かしている妻のAIアバター「LipSync Avatar」は、Ollamaで動くLLMと、SakuraSpeechによるボイスクローンTTS(Text To Speech)、MuseTalkのリップシンク。それをWebSocket経由でブラウザに飛ばして、iPhoneやAndroidタブレットで表示し、音声で対話できるところまでは完成しています。

ただ、これはDGX Spark互換機(ASUS Ascent GX10)ありきのシステム。TailscaleでVPN接続できるとはいえ、外部からはネット接続必須です。

だったら、iPhoneだけで全部やれないか。そう思ったのです。
iPhone AirのSoCは、MacBook Neoより格上です。 A19 Proに12GBのUnified Memory。8GBメモリとA18 ProのMacBook Neoよりスペック的には上。だったら、DGX Sparkでやらせていることの相当部分を、iPhoneネイティブアプリとして動かせるのではないか。
実際、MacBook Neoで、品質はそこそこですが、妻のボイスクローンとLLMで音声対話するシステムは動かしています。
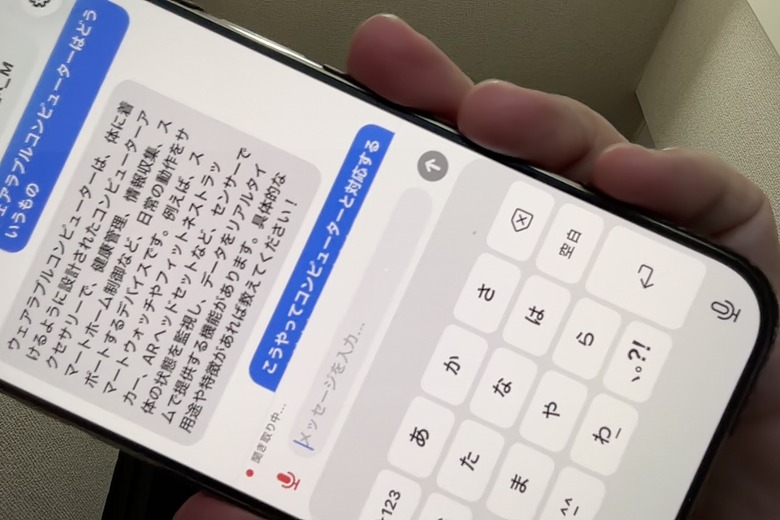
そんなわけで、Claudeにそのためのプログラム設計を相談することにしました。

仕様書を作ってClaude Codeに渡す
やりたいことはシンプルです。
LLM推論:オンデバイス
音声認識(STT、Speech To Text):オンデバイス
音声合成(TTS):できれば妻のボイスクローンで。無理ならiOS標準で
ネット接続:不要
動作環境:iPhone Air単体
これをClaudeと一緒に整理して、CLAUDE.mdという仕様書にまとめました(Claude Codeが起動時に読み込む設定が書かれたファイル)。
LLMはllama.cppのiOS向けビルドで動かす。STTはAppleのSFSpeechRecognizer(オンデバイス認識対応)。TTSはQwen3-TTS 0.6BのCoreML版を狙いつつ、ダメならAVSpeechSynthesizerで逃げる。UIはSwiftUI。
その仕様書をMacBook Airに読み込ませ、Claude Codeを起動しました。昨晩のことです。
筆者、iOSアプリ開発は初めてです。1993年あたりからADCの会員となっていましたが、それはWWDCに参加する(Mac雑誌の編集長やっていたので)のと、機材をほぼ半額で買えるというメリットのため。Xcodeを触ったのはApple Intelligence Foundation Modelをシミュレータで動かしたときだけ。
だが、筆者には「Claude Codeがある」。ヴァイブコーディング、iPhoneアプリ開発編の幕開けです。
Xcodeの壁を越えろ
Claude Codeが最初にやったのは、Xcodeのライセンス同意の確認でした。同意します。次にxcode-selectのパス切り替え、xcodebuild -runFirstLaunch。「こういう壁があるから、こうしてください」と淡々と案内してくれます。
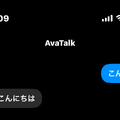
XcodeGenというツールでproject.ymlを書かせ、SwiftUIの最小チャットUIをゼロから組み立てていきます。10分ほどで、iPhoneの画面に「AvaTalk」と書かれた、まだ何もしゃべらないアプリが起動しました。
最初から完成品を書かせようとしない、Claude Codeの親心がありがたいです。だって、ビルドって何? みたいなところから始めてるわけですから。XcodeでビルドしたのをiPhoneに組み込むのってこんな簡単なんだってのも初めて理解しました。
llama.cppをiOS向けにビルドする
iPhoneでLLMを動かすには、llama.cppを使います。ただ、リポジトリは今やggml-orgに移転していて、SwiftPMからそのまま叩ける時代は終わっていました。build-xcframework.shを自分で回して、iOS向けの.xcframeworkを手作りする必要があります。
cmakeのバージョンをbrewで上げ直し、iPhoneのMetalを活かした状態でのビルドが完了するまで数分。ggml_metal_embed_libraryをONにして、Metalのカーネルもframeworkに同梱させました。
Swift側のラッパーはllama.cpp公式のllama.swiftuiサンプルを参考にしました。LibLlama.swiftというわずか1ファイルの実装が、実によくできた構造をしています。Swift 6のactor、nonisolated(unsafe)、AsyncStreamを駆使して、Opaque PointerをくるんだAI推論パイプラインが動きます。
最初に載せたのはQwen2.5 1.5B Q4_K_M、約1GB。A19 ProのGPUで層を全部オフロードして、推論が走りました。「こんにちは」と打ち込むと、ちゃんと返事が返ってきます。
ただ、ここでSwift 6のstrict concurrencyからの嫌がらせ。「actor-isolated property 'sampling' cannot be referenced from nonisolated deinit」。llama_sampler_free()を呼びたいだけなのに、isolationが通らない。nonisolated(unsafe) varで全部逃がします。綺麗じゃないが、動けば勝ちです。
クラッシュ対策
音声認識はSFSpeechRecognizerを使います。iOSネイティブ、オンデバイス対応、日本語ロケール指定で一発。そのはず、でした。
「Thread 2: EXC_BREAKPOINT」。アプリが起動直後に終了。
Xcodeのデバッガでbtと叩くと、スタックトレースには_swift_task_checkIsolatedSwiftが。Swift Concurrencyのisolation runtime checkに引っかかっています。
犯人はSFSpeechRecognizer.requestAuthorizationのコールバックでした。TCCデーモンの返答をバックグラウンドキューで受け取る仕様なのに、こちらのクラスは@MainActor。CheckedContinuationをresumeしようとしてクラッシュします。@Sendableを明示的に付けて回避。
続いてAVAudioEngineのinstallTapで同じパターン。タップインストール処理ごとnonisolated static funcに切り出しました。Swift 6、なかなか厳しいです。
音声合成は最初、AVSpeechSynthesizerで済ませました。iOSのKyoko音声。ところが返答に<|im_end|>トークンが混じっていたせいで「SSMLParserError: No root nodes found」が延々と出続けます。特殊文字を正規表現で事前に削ります。
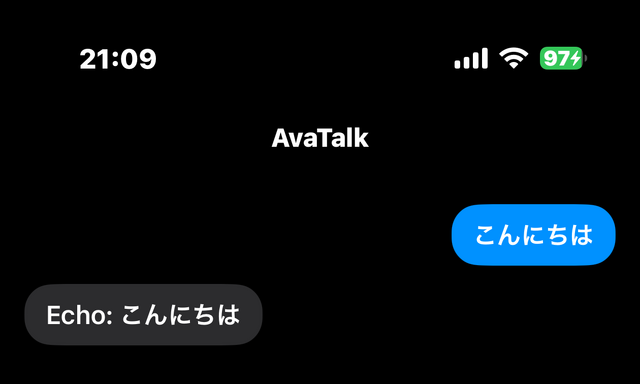
これで、音声入力→LLM→音声出力のフローが完成しました。オンデバイス。ネット接続なし。完全ローカルです。
音声がちょっと間延びしていたので、スピードを1割ほどアップすると、自然な感じになりました。
Bonsai 8B再び
小型のLLMとしてQwen2.5 1.5Bは安定していますが、もう少し賢い相手が欲しい。
白羽の矢を立てたのがBonsai 8Bです。Llama 3.1ベースの8Bパラメータを1ビット量子化(Q1_0)で1.15GBに収めています。通常なら8BのQ4_K_Mは4~5GB。それが1GB強。圧縮率は14倍です。
しかも、MacBook Neoで実装済み。

動きました。しかも応答は明らかに1.5Bより賢い。
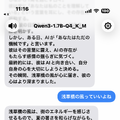
問題はreasoningモデル特有の<think>...</think>タグ。Bonsaiは思考過程をそのまま吐き出してきます。「<think>ユーザーはおはようと言っている。これは挨拶なので…</think>こんにちは!」みたいな具合です。文字列置換で削れます。
Gemma 4にも挑みました。これもMacBook Neoで動作済み。ところでGemmaといえば、ジュリアーノ・ジェンマですよね。マカロニ・ウェスタン。そして、マカロニといえばショーケン。脱線しました。
IQ2_M(2.62GB)をダウンロードして動かすと、「おはよう」と言うと「おはよう元気してる\nmodel\nおはよう元気してる\nmodel\nおはよう元気してる」と無限に自分の応答をコピーし始めます。token id 107(<end_of_turn>)がEOGとして認識されていない。ハードコードで停止条件に加えます。
さらにGemmaの巨大なJinja2テンプレート(1万6317文字、macro多用)をllama_chat_apply_template()が処理しきれません。組み込みの簡易"gemma"テンプレートに切り替えて回避しました。
しかし今度はIQ2_Mという2ビット量子化の品質問題が出ました。出力が鸚鵡返しばかりになります。「ひょっとして僕が言ってることを全部返す感じ?」と話しかけると、iPhoneが「ひょっとして僕が言ってることを全部返す感じ?」と返してきます。コントです。
Q4_K_M(3.46GB)ならマシになるはずですが、mmap failed: Cannot allocate memory。iOSのアプリ別メモリ上限を超えています。
なぜMacBook Neoでは動くのにiPhone Airではダメなのか。
ハードウェア的にはほぼ同じでも、OS、アーキテクチャが大きく異なるのです。
MacBook Neo(8GB) | iPhone Air(12GB) | |
|---|---|---|
総RAM | 8GB | 12GB |
アプリが使えるメモリ | ~6GB(OS管理下) | ~4~5GB(iOS上限) |
Gemma 4 E2B展開後 | ~5.5GB → GPU全乗り | 超過 → CPUオフロードか落ちる |
つまり総RAMはiPhone Airの方が多いのに、アプリが使える上限はMacBook Neoより低いという逆転現象が起きています。
MacBook NeoはmacOSの仮想メモリ管理とmmapが柔軟に動くのに対し、iOSはセキュリティとバッテリー効率のため、アプリごとのメモリ使用に厳しいサンドボックス制限を設けているためです。
Qwen 3.5 4B(ディスク3.4GB)がGemma 4 E2B(7.2GB)より重くなるのも同じ理由で、GGUFのファイルサイズではなく、展開後にrecommendedMaxWorkingSetSizeの約5.7GBを超えるかどうかが速度を決定的に左右します。
SoCの演算性能という意味ではiPhone AirがMacBook Neoを上回っていても、「何GBのモデルを一気に展開して推論できるか」という土俵では、iOSの制約がそれを打ち消してしまっているというのが実態です。
結局、現時点でiPhone Airに載る実用的な選択肢は、Qwen3 1.7B Q4_K_M(1.11GB)、Bonsai 8B(1.15GB)、Qwen2.5 1.5B(1.0GB)の三択に落ち着きました。
 |  |  |
ハンズフリーになると本当に使えるものになる
音声認識するためには画面左下にあるマイクボタンを押す必要があります。認識して確定すると認識が終わるので、押して話して、また押して、という操作が煩わしくなってきます。
そこで、SFSpeechRecognizerに無音検出を追加しました。最終更新から2秒間更新がなければ自動停止して自動送信。TTS読み上げ完了時に音声認識を自動再開。conversationModeというbooleanひとつで、会話が無限ループになります。
「おはよう」「おはようございます。今日も良い一日を」「今日の予定を整理したいんだけど」「わかりました。どんな予定がありますか?」——iPhoneに向かって話しかけるだけで、会話が続いていきます。ハンズフリー、ノールック、完全オンデバイス。電波の届かない山の中でも、飛行機の中でも。機内では迷惑この上ないですが。
そういうことができるアプリはいくつもありますし、GoogleのEdge GalleryであればGemmaがサクサク動き、先日LM Studioに買収されたLocally AIだったらBonsaiもAIもGemma 4も動かせるのですが、対応しているSTTが英語のみだったりと、バランスが微妙に悪い。
好みのLLMと日本語の完全音声応答でチャットできるローカルAI iPhoneアプリは自分の観測範囲ではありません。
自分の好みにジャストミートするものを、自分の手で作れるというのはすごい満足感ありますね。
まだ無理だったボイスクローン
といっても、やはり限界は大いに感じました。iPhoneアプリを作るのは、妻の声でAIアバターに話してほしい、というのがそもそもの動機でした。
ボイスクローン対応のTTSとして、最近評判のいいQwen3-TTS 0.6Bを試しました。
CoreML版(TTSKit)は定義済みスピーカーのみ対応で、ボイスクローン機能がありません。MLXベースのswift-qwen3-ttsならボイスクローン(ICLモード)が使えますが、ベースモデルにエンコーダー付きのspeech_tokenizerディレクトリが欠けていて、オリジナルのQwen3-TTS-0.6B-Baseから682MBのsafetensorsを追加するなど複数リポジトリを組み合わせてようやく構成が整います。
そこでまたもやメモリの壁。
LLM(~1.2GB)+ TTS Base+エンコーダー(~1.7GB)+ MLX推論バッファ(~2GB)。iOSがアプリに許すメモリ上限を軽々と超えて、「Terminated due to memory issue」。
対応策として、LLMで応答生成→LLMをアンロード→TTSをロード→音声生成→TTSをアンロード→LLMを再ロード、という「メモリスワップ」を実装しました。os_proc_available_memory()で実メモリ残量を監視しながら回します。Apple II時代のディスクスワップを思い出す光景です。
それでもボイスクローンのICLモードはMLXの作業メモリが大きすぎて、2GB空いていても落ちます。現時点ではiOS標準音声(あるいはQwen3-TTSの定義済みボイス)での妥協となりました。プリセットのボイスも不安定なので、結局iOS標準のKyokoに喋ってもらうことになりました。
Air-Airコンビで「動く」ものができた
今のAvaTalkの構成を整理しておきます。
LLM:Qwen3 1.7B or Bonsai 8B(llama.cpp、Metal GPU)
STT:SFSpeechRecognizer(iOS標準、日本語、オンデバイス)
TTS:AVSpeechSynthesizer(標準)またはQwen3-TTS定義済みボイス
UI:SwiftUI、MVVM、@Observable、Swift 6 strict concurrency
モデル管理:HuggingFace Hubからの動的ダウンロード、複数モデル切替
ボイスクローンは現時点では難しい。ただ、ソフトウェアとして必要なパイプラインは完成していて、iPhoneの次か次の次のモデルでメモリ上限が上がれば現実的になってくる、という感触はあります。
浅草橋の極狭オフィスで思いついた「iPhoneだけで全部やれないか」という問いに、Air-Airコンビ+Claude Code + Xcodeという組み合わせは、一晩で答えを返してくれました。
iOSアプリ開発は初めてだった筆者が、翌朝には音声で会話できるAIが手の中にいました。ヴァイブコーディングというのは、本当に入門の敷居を取り払ってしまうものだと実感しています。
そして、iOSとmacOSの違いを身をもって体験するという貴重な機会を得られました。
 |  |
ここで、ふと思いました。制限のゆるいAndroidならもっとできるんじゃ……。今、手元にAndroid端末がなくてよかったです。あったら、そのままAndroidアプリ編に突入していたでしょうから。
※この記事は、Claude Codeと共同で行ったAvaTalk開発の記録をもとに、筆者が修正・加筆したものです。













![イヤホン 有線 [HIFI音質]イヤホン 有線 3.5mmジャック ノイズ低減 通話/音楽 音量調節対応 防水 通勤・会議・運動 | 原音再現 MFi認証 重低音 遅延なし コンパクト 軽量 インイヤー 人体工学 image](https://m.media-amazon.com/images/I/31CBe3mkz-L._SL160_.jpg)






