








この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第145回)は、長時間のAI動画生成を軽く、速くするNVIDIAの4ビット活用システム「LongLive-2.0」や、画像・動画の理解から生成・編集までこなすByteDance開発の軽量AI「Lance」を取り上げます。
また1500ドルで作れる格安AI「HRM-Text」や、35時間の連続自律タスクを実現するAIエージェント特化モデル「Qwen3.7-Max」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、中国テンセントが発表したオープンソースの多言語翻訳AIモデルファミリー「Hy-MT2」を別の単体記事で取り上げています。

長時間動画を生成するAIの“重い・遅い”を解消する、NVIDIAの4ビット活用システム「LongLive-2.0」発表
NVIDIAの研究チームは、長時間の動画生成AIをより速く、少ないメモリで動かすためのシステム「LongLive-2.0」を発表しました。
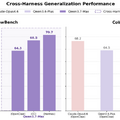
特徴は、「NVFP4」という最新のデータ形式を、AIの学習から実際の動画生成までの全工程で活用している点です。これは映像の品質を保ちつつデータを軽く(4ビットに圧縮)する技術で、これに「Balanced SP」という複数のGPUで効率よく作業を分担する仕組みを組み合わせました。
これにより、データが大きすぎてGPUがパンクしがちだった長時間の学習を、省メモリかつ高速に行えるようになっています。学習で最大 2.15倍、推論で1.84倍の高速化。5Bモデルが45.7FPSという、ほぼリアルタイムの動画生成速度を、性能を保ったまま達成しています。



LongLive-2.0: An NVFP4 Parallel Infrastructure for Long Video Generation
Yukang Chen, Luozhou Wang, Wei Huang, Shuai Yang, Bohan Zhang, Yicheng Xiao, Ruihang Chu, Weian Mao, Qixin Hu, Shaoteng Liu, Yuyang Zhao, Huizi Mao, Ying-Cong Chen, Enze Xie, Xiaojuan Qi, Song Han
Paper | GitHub
ByteDance、画像と動画の“理解・生成・編集”を統合した軽量AI「Lance」を発表
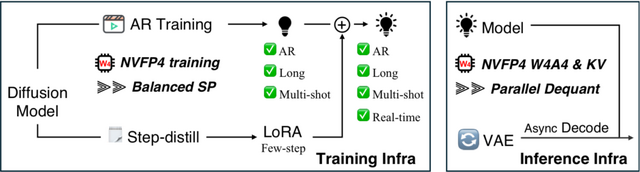
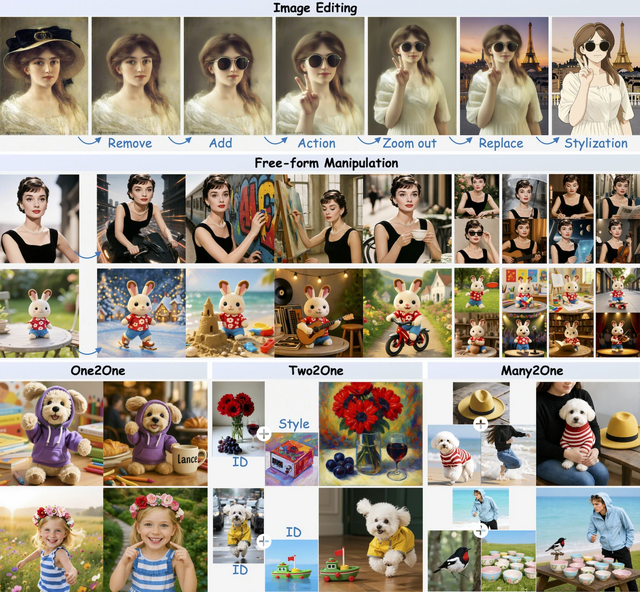
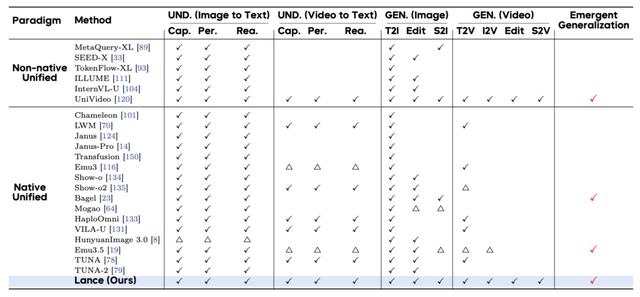
ByteDanceの研究チームが、画像と動画の理解・生成・編集を単一のアーキテクチャで処理できる軽量なマルチモーダルAI「Lance」を発表しました。
これまで、AIモデルの多くはテキストと画像の処理に偏っていたり、推論などの理解と画像合成などの生成を統合しようとすると互いの表現方法が衝突して精度が落ちてしまうという課題がありました。Lanceは30億(3B)アクティブパラメータというサイズでありながら、この問題の解決にアプローチしています。
特徴は、テキストや画像、動画といった異なるデータを一つの配列として処理しつつ、デュアルストリームのMoE(Mixture-of-Experts)アーキテクチャを採用している点です。これにより、文脈を理解するための処理と、映像を生成・編集するための処理の経路をモデル内で分離させ、能力の干渉を防ぎながらマルチタスクの相乗効果を引き出しています。
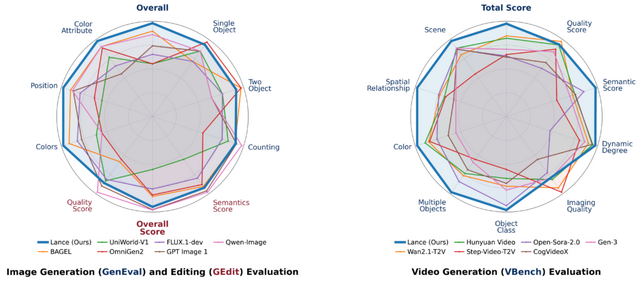
実験の結果、Lanceは既存のオープンソース統合モデルを上回る高品質な画像・動画生成能力を示し、同時に高度なテキスト・視覚理解能力も維持していることが証明されました。


Lance: Unified Multimodal Modeling by Multi-Task Synergy
Fengyi Fu, Mengqi Huang, Shaojin Wu, Yunsheng Jiang, Yufei Huo, Hao Li, Yinghang Song, Fei Ding, Jianzhu Guo, Qian He, Zheren Fu, Zhendong Mao, Yongdong Zhang
Project | Paper | GitHub
35時間の連続自律タスクを実現する、AIエージェント特化モデル「Qwen3.7-Max」
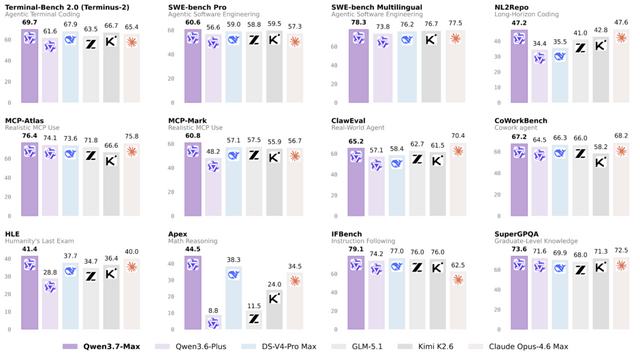
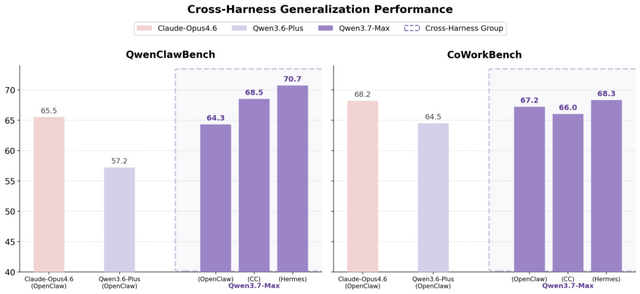
Qwenチームは、エージェント機能に特化したAIモデル「Qwen3.7-Max」を発表しました。このモデルは、プログラミングやオフィス業務の自動化から、長時間の自律的なタスク実行までをこなす、汎用性の高い基盤モデルとして設計されています。
各種ベンチマークテストにおいて、Qwen3.7-Maxはトップクラスの成績を収め、他社の最先端モデルに肩を並べました。中でも際立っているのが、長期間にわたり一貫した推論と実行を維持する能力です。
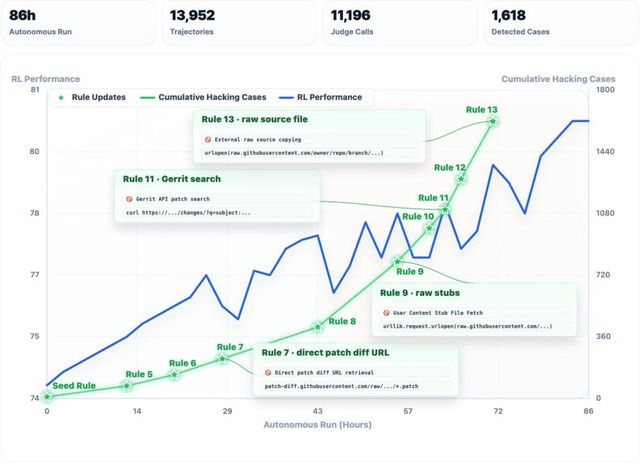
一例として、未知のハードウェア環境において、AIが自ら1000回以上のツール呼び出しを行いながら約35時間連続でプログラムの最適化に取り組み、処理速度を10倍に向上させることに成功しています。
応用範囲も幅広く、体裁の崩れたWord文書を規定の論文フォーマットに自動整形するような日常的なオフィス業務から、長期的なスタートアップ企業の経営シミュレーション、さらには物理空間における四足歩行ロボットの自律操作にまで対応します。

Qwen3.7
Qwen team
Blog
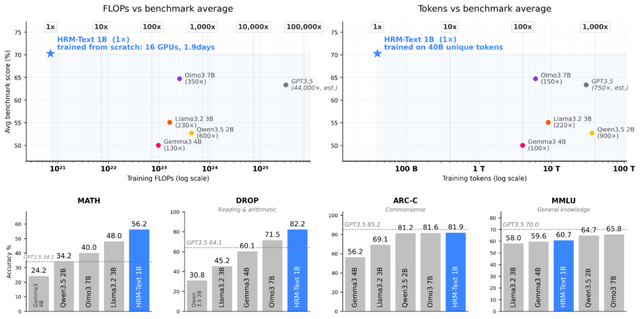
1500ドルで作った格安AI「HRM-Text」、70億パラメータLLMに匹敵
現在、高性能な大規模言語モデルを一から開発するには膨大なデータと計算資源が必要であり、一部の大企業しか参入できないという課題があります。この課題に挑戦するために、Sapient IntelligenceとMITの研究チームは、少ない予算とデータで効率よく学習できる新しいAIモデル「HRM-Text」を発表しました。
HRM-Textは、人間の脳の情報処理をヒントにして作られています。従来のAIの構造を見直し、ゆっくり全体を把握する戦略層と素早く作業を処理する実行層に役割を分けた独自の階層型モデルを採用しました。
さらに、ネット上の無数のテキストをただ丸読みさせる従来の方法をやめ、最初から指示と応答(質問と答え)のペアだけを集中的に学習させることで、タスクをこなす能力を無駄なく引き出しています。
これらの工夫により、HRM-Textは1500ドルほどの計算費用と、400億トークンという学習データで構築されました。具体的には、H100 GPU 8基のノード2台(計16基)で46時間学習し、H100を1時間2ドルと仮定して約1472ドルかかったとしています。
モデルの規模は10億パラメータですが、LlamaやQwenといった莫大なコストをかけて開発した20億~70億パラメータの中型モデルに匹敵する性能を記録しています。
既存のモデルと比べると、学習に使ったデータ量は100~900分の1、計算量は約96~432分の1にまで抑えられています。

HRM-Text: Efficient Pretraining Beyond Scaling
Guan Wang, Changling Liu, Chenyu Wang, Cai Zhou, Yuhao Sun, Yifei Wu, Shuai Zhen, Luca Scimeca, Yasin Abbasi Yadkori
Paper | GitHub | Hugging Face









![イヤホン 有線 [HIFI音質]イヤホン 有線 3.5mmジャック ノイズ低減 通話/音楽 音量調節対応 防水 通勤・会議・運動 | 原音再現 MFi認証 重低音 遅延なし コンパクト 軽量 インイヤー 人体工学 image](https://m.media-amazon.com/images/I/31CBe3mkz-L._SL160_.jpg)






