


この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」。
今回(第143回)は、AMDで学習された小型AIモデル「ZAYA1-8B」や、ClaudeとGPTが批判し合いながら研究(アイデア出しから実験、論文執筆など)を自動で行うオープンソースツール「Aris」を取り上げます。
また、1200万トークンを一度に処理できるという新LLM「SubQ」や、実世界に特化したオープンソースのロボット制御AI「MolmoAct2」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、無検閲(Uncensored)オープンソース動画生成モデル「Sulphur 2」を別の単体記事で取り上げています。
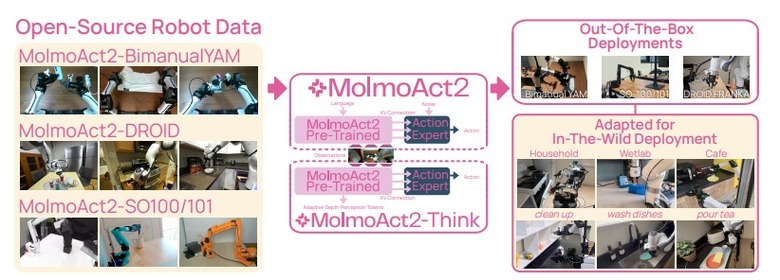
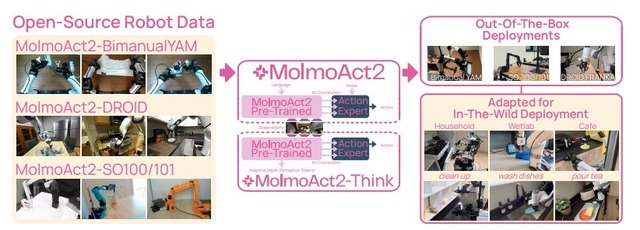
GPT-5やGemini超えの空間認識力、実世界に特化したオープンソースのロボット制御AI「MolmoAct2」
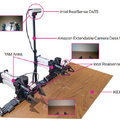
近年、AIを活用して多様な作業をこなす汎用ロボットの開発が進められていますが、実社会への導入にはまだ多くのハードルがあります。そうした中、現実世界での実用化に焦点を当てて開発された、オープンソースのロボット制御用AIモデル「MolmoAct2」が発表されました。
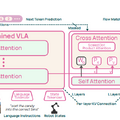
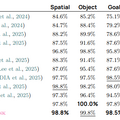
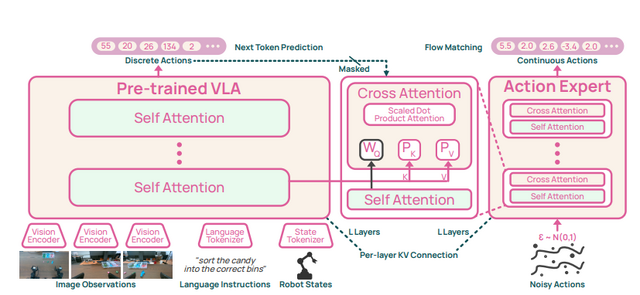
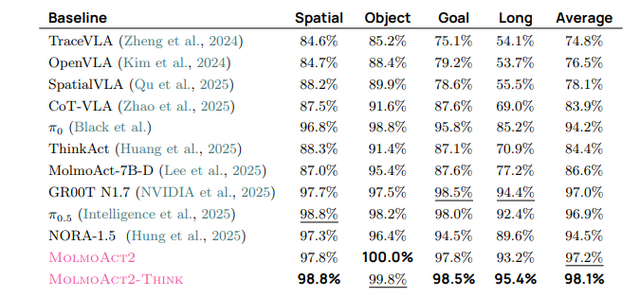
本モデルは、物理環境での推論に特化した視覚言語モデル「Molmo 2-ER」をベースとしています。このモデルは、空間認識などの各種ベンチマークにおいてGPT-5やGemini Robotics ER-1.5といったモデルを上回る成果を出しています。
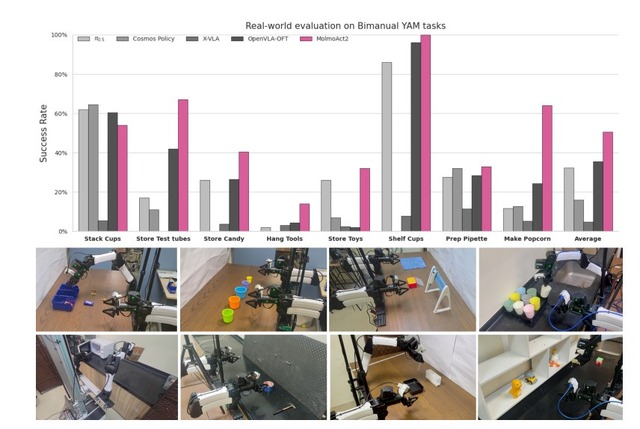
720時間以上の双腕ロボット用データセット「MolmoAct 2-Bimanual YAM」で学習されており、衣類を畳むといった複雑な両手作業が可能です。
さらに、状況が変化した部分の奥行き情報だけを適応的に再計算するモデル「MolmoAct 2-Think」も開発され、計算の遅延を抑えつつ高い精度を維持しています。
実機でのゼロショット評価では、リンゴを皿に乗せる、ピペットをトレイに入れるなどのタスクで平均87.1%の成功率を達成し、競合モデルのπ0.5の45.2%を大きく上回りました。

MolmoAct2: Action Reasoning Models for Real-world Deployment
Haoquan Fang, Jiafei Duan, Donovan Clay, Sam Wang, Shuo Liu, Weikai Huang, Xiang Fan, Wei-Chuan Tsai, Shirui Chen, Yi Ru Wang, Shanli Xing, Jaemin Cho, Jae Sung Park, Ainaz Eftekhar, Peter Sushko, Karen Farley, Angad Wadhwa, Cole Harrison, Winson Han, Ying-Chun Lee, Eli VanderBilt, Rose Hendrix, Suveen Ellawela, Lucas Ngoo, Joyce Chai, Zhongzheng Ren, Ali Farhadi, Dieter Fox, Ranjay Krishna
Paper | GitHub | Blog
ClaudeとGPTが批判し合いながら研究(アイデア出しから実験、論文執筆など)を自動で行うオープンソースツール「Aris」
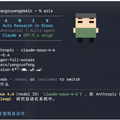
「Aris」(Auto-claude-code-research-in-sleep)は、機械学習の研究を自動化するためのオープンソースツールです。アイデア出しから実験、レビュー、論文執筆、査読への返答までを一気通貫で支援してくれます。
このツールの強みは、実行役(Claudeなど)と評価役(GPT-5.4など)の異なるモデルを組み合わせた連携にあります。単一のAIによる自己評価では生じやすい盲点を、別のAIが厳格にレビューすることで防ぎ、より質の高い研究成果を生み出します。
Arisは、文献調査に基づいたアイデアの発見から始まり、実験コードの実装とGPUへのデプロイ、AIによる自動レビューとコードの改善、そして最終的なLaTeXでの論文執筆からPDF生成までをすべて自動で行い、さらには査読結果を受け取った後の反論も作成します。
過去の実験結果や失敗したアイデアは蓄積され、次のステップに活かされます。単に作業をこなすだけでなく、実験データと論文の主張に矛盾や誇張がないかを3段階で監査する仕組みも備えています。


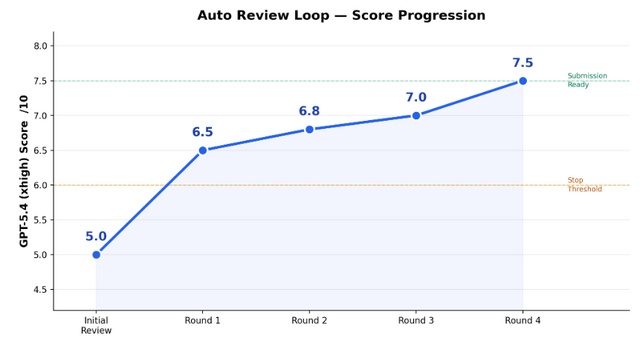
ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration
Ruofeng Yang, Yongcan Li, Shuai Li
Paper | GitHub
AMD製AIアクセラレーターで学習された小型AIモデル「ZAYA1-8B」、数学・コーディングで大型AIに肉薄
米Zyphraから、軽量でありながら推論能力を持つMoE(Mixture of Experts)モデル「ZAYA1-8B」が発表されました。本モデルは、事前学習からファインチューニングまでの全工程をAMD Instinct MI300環境上で実施したMoEモデルといいます。
推論時に稼働するパラメータ数はわずか7億(全体で80億)ですが、効率的な独自のMoEアーキテクチャを採用しており、数学やプログラミングにおいて数十倍のサイズを持つ巨大モデルに匹敵する性能を発揮します。
ZAYA1-8Bの性能向上を支えているのが、「Markovian RSA」と呼ばれる独自技術です。これは、モデルが複数の思考プロセスを並行して生成し、それらを効率的に集約しながら正答を導き出す手法です。
この技術を活用することで、ZAYA1-8Bは難関数学コンテストのベンチマークにおいて、Gemini-2.5 ProやDeepSeek-V3.2、GPT-5-Highといった大規模の最先端モデルに肉薄する驚異的なスコアを記録しました。

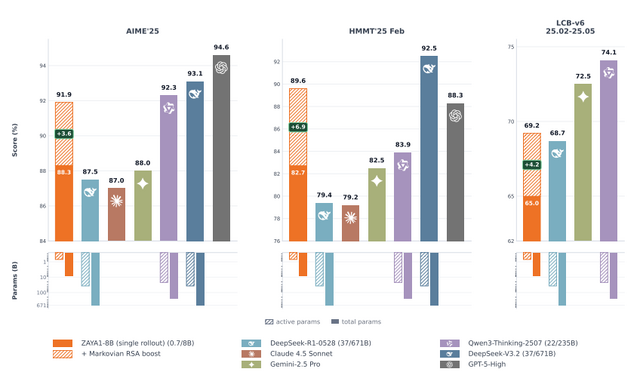
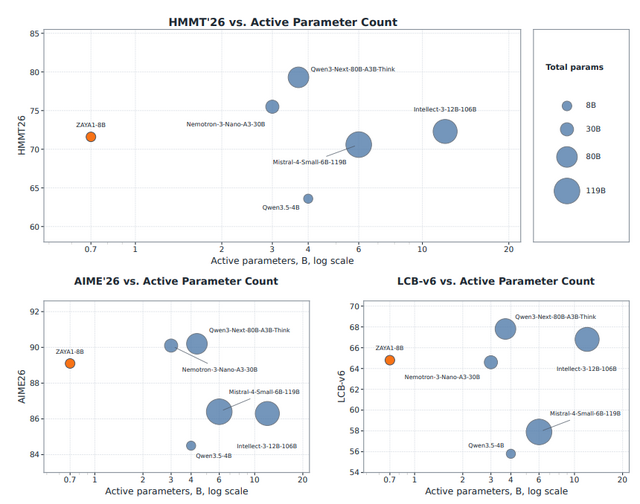
ZAYA1-8B Technical Report
Robert Washbourne, Rishi Iyer, Tomas Figliolia, Henry Zheng, Ryan Lorig-Roach, Sungyeon Yang, Pritish Yuvraj, Quentin Anthony, Yury Tokpanov, Xiao Yang, Ganesh Nanduru, Stephen Ebert, Praneeth Medepalli, Skyler Szot, Srivatsan Rajagopal, Alex Ong, Bhavana Mehta, Beren Millidge
Paper | Blog | Hugging Face
1200万トークン(リポジトリ丸ごと)を一度に処理できるという新LLM「SubQ」、長文理解ではClaude Opus 4.7やGPT-5.4を上回る性能
AIスタートアップ「Subquadratic」は、大規模言語モデル(LLM)「SubQ」を発表しました。最初のプレビュー版「SubQ 1M-Preview」が発表され、研究結果では最大1200万トークンまで動作することが示されています。
1200万トークンは、Pythonの標準ライブラリ全体(約510万トークン)や、Reactリポジトリの過去半年分のプルリクエスト約1050件分(約750万トークン)を一度に読み込めるレベルといいます。
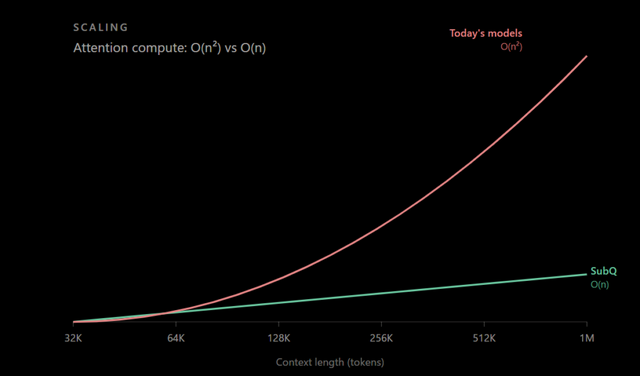
従来の多くのLLMには、文章が長くなるほど計算量が増えるという弱点がありました。文章中のすべての単語同士の関係を計算しているため、長さが10倍になると計算量は約100倍に膨らんでしまうからです。
SubQはこの仕組みを作り直し、文章が長くなってもその分だけしか計算量が増えない、線形に近いアーキテクチャを採用しました。
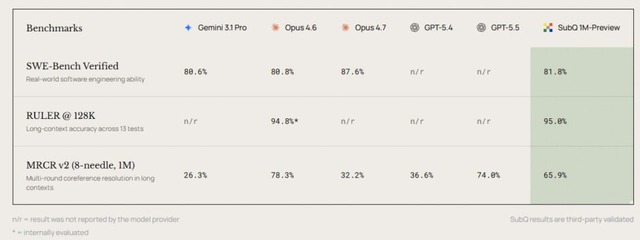
SubQ 1M-Previewのベンチマーク結果は次の通り。長文から特定の情報を探す「RULER」では95.0%を記録し、Claude Opus 4.6(94.8%)を僅かに上回りました。長文中の複数情報を関連付ける「MRCR v2」では65.9%で、Claude Opus 4.7(32.2%)、GPT-5.4(36.6%)、Gemini 3.1 Pro(26.3%)を大きく上回った一方、Claude Opus 4.6(78.3%)とGPT-5.5(74.0%)には及びませんでした。
プログラミング能力を測る「SWE-Bench」では81.8%で、Opus 4.6(80.8%)やGemini 3.1 Pro(80.6%)を超えたものの、Opus 4.7(87.6%)には届きませんでした。
提供形態は3つ。開発者向けの「API」、リポジトリ全体を1つのコンテキストに丸ごと読み込めるコーディングエージェント「SubQ Code」、長文検索ツール「SubQ Search」が、いずれもプライベートベータとして利用可能です。
同社によれば、料金は既存の主要LLMの5分の1程度に抑えられる見込みとしています。Subquadraticはこれまでに2900万ドルのシード資金を調達済みです。