MacBook Neoの8GBメモリでAIをなんとかするシリーズ。前回の記事では、独自開発エージェンティックAIのmazzaineoにWebターミナルとSwiftLM推論エンジンを追加して、8GBメモリの限界に挑んだ話を書きました。

今回はその続き。「1ビットLLM」という新しいアプローチで、8GBマシンのローカルAI体験がさらに変わった話です。
Bonsai 8Bとの出会い
きっかけはSNSで見かけた、PrismMLという会社のポスト。Caltech(カリフォルニア工科大学)の研究者チームが作った「Bonsai 8B」というモデルで、全てのウェイトが-1か+1の「ネイティブ1ビット」で訓練されている。後からの量子化ではなく、最初から1ビットで学習しているというのがポイントです。
スペックを見て目を疑いました。8.2Bパラメータのモデルが、たった1.1GBに収まっている。FP16なら16GBになるところです。93%の圧縮率。しかもベンチマークではLlama 3.1 8B(FP16で16GB)を上回り、Mistral 3 8Bに肉薄するスコアを出しているではないですか。
1ビットLLMといえば2023年に発表されたマイクロソフトのBitNetですが(技術的にはちょっと違ってそうですが)、ついにその実用版現る、という感じ。
このサイズならば8GBマシンで動かない理由がない。試すしかないでしょう。
Ollamaでは動かなかった
最初に試したのはOllama。コミュニティがアップロードしたBonsai 8Bのモデルがあったので、ollama pullしてみたところ、ダウンロードまでは問題なく進みました。しかし実行すると、llama runnerがクラッシュ。
原因は単純で、標準のOllama(のllama.cpp)が1ビット量子化フォーマット「Q1_0_g128」をまだサポートしていないためです。この形式はPrismMLが独自に実装したもので、1ウェイトあたり1符号ビット + 128ウェイトごとにFP16のスケールファクター1つ、という構成。実効1.125ビット/ウェイトです。
PrismMLのフォーク版llama.cppとMLXでしか動かない、というのが現時点での制約でした。
Bonsai Demoで一発セットアップ
幸い、PrismMLは「Bonsai-demo」というリポジトリを公開していて、setup.shを叩くだけで必要なものが全部揃います。
macOSではpre-builtバイナリ(PrismMLフォーク版llama-server)をGitHubリリースからダウンロードし、HuggingFaceからGGUFモデルをダウンロードしてくれます。MLXのセットアップもやろうとするのですが、これにはXcodeフルインストールが必要。Command Line Toolsだけでは「metal shader compilerがない」と怒られます。前回のSwiftLMでも同じ問題にぶつかりましたね。
ともあれ、llama-server + GGUFの組み合わせで十分動きます。
起動してみる
PrismMLフォーク版のllama-serverは、標準のllama.cppと同じOpenAI互換APIを提供します。つまり、SwiftLMと同じ/v1/chat/completionsエンドポイントが使える。
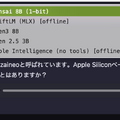
起動時のログを見ると、モデルウェイト1,099MB、KVキャッシュ1,152MB、計算バッファ304MB。合計約2.5GBで、8GBの中に余裕で収まっています。これはSwiftLMの1,673MB(Qwen 2.5 3B)よりも小さい。8.2Bパラメータのモデルが、3.1Bパラメータのモデルより軽いという逆転現象が起きています。
日本語の応答テストでは「こんにちは、私はBonsaiと申します。AIアシスタントとして、質問にお答えし、会話に参加するように設計されています。」と返ってきました。自然な日本語です。QwenベースなのでCJK言語は得意分野。
Tool Callingが完璧に動いた
mazzaineoのエージェント機能の核であるTool Calling。これが動くかどうかが実用上の分かれ目です。
結果は、web_searchツールを正しく呼び出し、検索結果を取得して要約する、という一連のフローが完璧に動作しました。BFCLスコア(Berkeley Function Calling Leaderboard)が65.7と高いだけのことはあります。
ちなみに、前回統合したSwiftLM上のQwen 2.5 3Bは、同じテストでTool Callingに失敗しました。3Bモデルの限界がここに出ているのかもしれません。
3者比較ベンチマーク
せっかくなので、Bonsai 8B、SwiftLM(Qwen 2.5 3B)、Ollama(Qwen 2.5 3B)の3者で正面対決させてみました。
Bonsai 8B | SwiftLM | Ollama | |
パラメータ | 8.2B | 3.1B | 3.1B |
ディスクサイズ | 1.1 GB | 1.7 GB | 2.3 GB |
短い応答 (日本語) | 24.6 tok/s | 28.3 tok/s | 24.9 tok/s |
中程度の説明 | 20.3 tok/s | 26.8 tok/s | 22.6 tok/s |
長いコード生成 | 18.2 tok/s | 26.9 tok/s | 21.9 tok/s |
平均速度 | 21.1 tok/s | 27.3 tok/s | 23.1 tok/s |
Tool Calling | OK | NG | OK |
速度ではSwiftLMが勝つ。でも……
純粋な生成速度ではSwiftLMが平均27.3 tok/sで最速でした。Bonsai 8Bは21.1 tok/sで、SwiftLMの約0.77倍。1ビットのdequantizationオーバーヘッドがあるので、これは仕方ない部分です。
しかし、数字だけでは見えない差があります。
回答の品質が違う
Bonsai 8Bの回答は、Qwen 2.5 3Bとは明らかにレベルが違います。8.2Bパラメータの恩恵で、文章の構造化、文脈の理解、日本語の自然さ、すべてが上。コード生成でも、ドキュメント文字列やエッジケース処理が3Bモデルより丁寧です。tok/sの数字は劣っていても、読む価値のある回答が返ってくる。
日本語の品質については、清水亮さんの独自ベンチマークでも非常に優秀な成績を残しています。NVIDIA GPUでの計測ですが。
Tool Callingの信頼性、占有ディスクとメモリが最小で済む
前述の通り、SwiftLM上のQwen 2.5 3BはTool Callingに失敗しました。関数呼び出しのJSONを正しく構造化する能力は、パラメータ数とモデルの訓練品質に依存します。Bonsai 8Bは1ビット圧縮されていても8.2Bパラメータ分の「知識」を保持しているため、構造化出力が安定している。mazzaineoのエージェント機能を活かすなら、Tool Callingが動くかどうかは死活問題です。
また、1.1GBという圧倒的な小ささ。モデルウェイトだけで見れば、SwiftLMの1.7GB、Ollamaの2.3GBより遥かに軽い。8GBマシンではこの差がACE-Step(音楽生成)やSD Turbo(画像生成)との共存余地に直結します。
mazzaineoへの統合
Bonsai 8Bはllama-serverのOpenAI互換APIで動くため、前回SwiftLM用に作ったOpenAIバックエンド(_run_openai_agent)がそのまま使えます。agent.pyのMODEL_REGISTRYに1行追加するだけ。
server.pyにはBonsaiサーバーの起動・停止エンドポイント(/api/bonsai/start、/api/bonsai/stop)も追加しました。Web UIのモデルセレクターから「Bonsai 8B (1-bit)」を選ぶだけで切り替えられます。
回答も非常に高速です。この品質でこのスピードなら実用的には十分でしょう。メモリに余裕があるおかげで、ボイスクローンTTSも快調に動いています。
前回のSwiftLM統合で「マルチバックエンド構成」に書き換えておいたことが活きました。新しいモデルを追加するコストが劇的に下がっています。
8GBマシンでのおすすめ構成
現時点での結論はこうです。
品質重視:Tool Callingが必要なら、Bonsai 8B。1.1GBで8Bパラメータの品質が得られて、しかもエージェント機能が確実に動く。速度の差(21 tok/s vs 27 tok/s)は体感で大きな問題にはなりません。
速度重視:シンプルな会話ならSwiftLM + Qwen 2.5 3B。Tool Callingが不要な用途では、1.32倍速いSwiftLMが快適です。
どちらにしても、Ollamaのデフォルト設定(Qwen 2.5 3B、llama.cppバックエンド)より良い選択肢ができたのは間違いありません。
1ビットが変えるもの
「1ビットLLM」は単に小さいだけではなく、ローカルAIの常識を変えるものだと感じています。
8.2Bパラメータのモデルが1.1GB。FP16の16GBが約93%圧縮されて、8GBのMacBookで余裕で動く。しかもLlama 3.1 8B(FP16で16GB)を超えるベンチマークスコア。これまで「8GBでは3Bモデルが限界」と思い込んでいた壁が、一気に崩れました。
PrismMLのフォークが上流にマージされれば、OllamaやMLXの標準ビルドでも1ビットモデルが使えるようになるでしょう。そうなれば、セットアップの手間も解消されます。
8GBメモリの限界に挑戦する日々は、まだまだ続きそうです。

※この記事は、Claude Codeに実行させたベンチマーク結果と独自開発エージェンティックAIへの統合作業の記録を元に、筆者が修正・加筆したものです。



このシリーズの続きがあります。記事はこちら。