


Stability AIが音楽生成AI新世代モデルを公開
Stability AIは、音楽・音声生成AIモデルの新シリーズ「Stable Audio 3.0」を発表しました。同シリーズはオープンウェイトモデルとして公開され、ライセンス済みデータのみで学習されているとしています。ユーザーは生成した出力の所有権を持ち、自由に配布・商用利用が可能です。
ライセンス済みデータ学習とオープンウェイト公開が注目点
音楽生成AIをめぐっては、学習データの権利問題が業界全体で議論されています。Stable Audio 3.0は、Universal Music GroupやWarner Music Groupとのパートナーシップのもと、完全にライセンスされたデータで学習されているとStability AIは説明しています。同社によれば、商用利用を制限しないオープンな音楽生成モデルは他に例がないとしており、開発者や企業が安心して活用できる環境を整えることを重視した設計だといえます。年間売上が100万ドルを超える組織向けにはエンタープライズライセンスも用意されており、法的補償も提供されます。
6分超の楽曲生成とデバイス上での完全作曲を実現
モデルラインナップと生成時間の大幅拡張
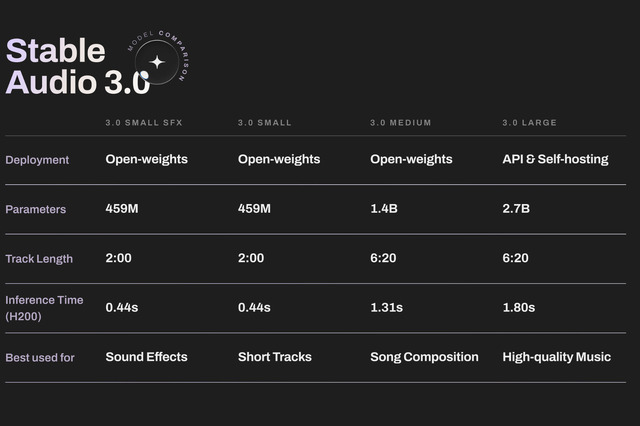
Stable Audio 3.0は、新しいセマンティック・アコースティック自動エンコーダーを採用したアーキテクチャを採用しています。モデルラインナップは以下の通りです。
・3.0 Small SFX:効果音生成に特化したオープンウェイトモデル
・3.0 Small:最大2分の楽曲生成が可能なオープンウェイトモデル(従来のStable Audio Open Smallは最大11秒、Stable Audio Openは最大47秒)
・3.0 Medium:6分超の楽曲生成が可能なオープンウェイトモデル
・3.0 Large:6分超の楽曲生成が可能なAPIモデル
生成時間は秒単位の粒度で指定できる可変長生成方式を採用しており、必要な長さの音声を柔軟に出力できます。
デバイス上でのフル楽曲作曲に初対応
Stability AIによれば、3.0 Smallはデバイス上・オフライン環境でフルの楽曲作曲が可能な初のモデルとしています。これまでオンデバイスの音声生成は短いサンプルに限られていましたが、3.0 Smallではオフライン環境でも完全な楽曲トラックの生成が可能になるとしています。
LoRAファインチューニングとオーディオインペインティングに対応
画像生成モデルで普及したLoRA(Low-Rank Adaptation)によるファインチューニングが、音声生成モデルとして初めてドキュメントとともに公開されます。3.0 Smallおよび3.0 Mediumのウェイトと合わせて提供され、ユーザーは自分のライブラリに合わせたカスタマイズが可能です。エンタープライズライセンス契約者向けには、ファインチューニングのサポートも提供されます。
また、オーディオインペインティング機能として以下の編集オプションが利用できます。
・シングルセグメント編集:楽曲の特定部分を修正
・マルチセグメント編集:複数箇所を同時に編集
・コーザル継続:既存の音声をエンドポイント以降に延長
今後の展開とアクセス方法
HuggingFace・API・パートナープラットフォームで順次提供
Stable Audio 3.0の各モデルは以下の方法で利用できます。
・オープンウェイト:3.0 Small SFX、3.0 Small、3.0 MediumをHugging Faceよりダウンロード可能
・API:3.0 LargeはStability AI APIを通じて提供
・パートナープラットフォーム:ComfyUIなどのプラットフォームでも順次対応予定
年間売上100万ドル超の組織向けエンタープライズライセンスについては、Stability AIへの直接問い合わせが必要です。また、ミュージシャン向けの新製品スイートも開発中としており、早期アクセスのウェイトリストへの登録を受け付けています。























