



この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第125回)は、中国AIユニコーン「StepFun」が開発したGUI自動操作AI「Step-GUI」や、画像から高品質な3Dモデルを生成するMicrosoft開発のAI「TRELLIS.2」を取り上げます。
また、3人称視点映像を1人称視点映像に変換する「EgoX」や、テキスト、画像、動画の同時入力から高品質な動画を生成できる「Kling-Omni」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、絵師の仕事は歴史研究と長年の訓練に裏打ちされた創造行為であり、AIによる効率化では代替できず、守られるべきものであることを主張した内容を別の単体記事で取り上げています。

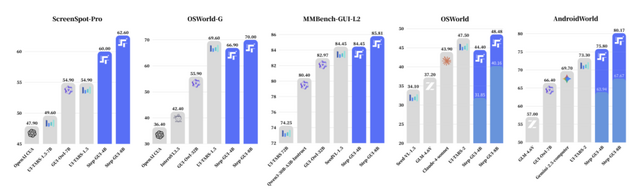
GUI自動操作AI「Step-GUI」を中国AIユニコーン「StepFun」が発表。アノテーションコストを最大100分の1に削減
中国のAIスタートアップでありユニコーン企業「StepFun」のGELabチームが、GUIを自動操作するAIエージェント「Step-GUI」を発表しました。
GUIエージェントの開発において最大の課題は、高品質な学習データをいかに効率よく収集するかという点です。従来の手作業によるアノテーションは主観性が入りやすく、コストも膨大でした。
そこで本研究では「Calibrated Step Reward System」(CSRS)という仕組みを導入しています。これはモデルが生成した操作軌跡を、タスク全体の成否という客観的な評価と紐づけることで、90%以上の精度を維持しながらアノテーションコストを10~100分の1に削減するものです。
この手法で訓練されたStep-GUI(4Bおよび8Bパラメータ)は、AndroidWorldで約80.2%、OSWorldで約48.5%という最先端の性能を達成しました。特に良いのが、4Bモデルが一般向けのハードウェアでもローカル実行可能な点で、クラウドに依存しない運用が可能になります。
さらに、実際の日常利用パターンに基づいた新しいベンチマーク「AndroidDaily」も公開されました。交通、買い物、SNS、エンタメ、地域サービスといった高頻度の利用シナリオをカバーし、静的評価用の3146アクションと、エンドツーエンド評価用の235タスクで構成されています。

Microsoftが画像から高品質な3Dモデルを生成する「TRELLIS.2」発表。PBRマテリアルも高速生成
Microsoft Researchと清華大学などの研究チームが、画像から高品質な3Dモデルを生成する技術「TRELLIS.2」を発表しました。
従来の3D生成技術の多くはSDF(符号付き距離関数)というフィールドベースの手法に頼っており、穴の開いた形状や内部構造を持つ複雑なモデルをうまく扱えませんでした。
今回の研究では「O-Voxel」という新しい3D表現形式を導入。O-Voxelはこうした制約がなく、複雑なトポロジーやシャープな特徴も表現可能です。また、メッシュデータとの変換が数秒で完了するため、既存のワークフローにも組み込みやすくなっています。
外観についても、単なる色情報だけでなく、金属の光沢や表面の粗さ、透明度といったPBR(Physically Based Rendering)マテリアルを同時に生成できるため、照明を変えても自然に見えるリアルなモデルが得られます。
効率面では、新開発のSparse Compression VAEにより16倍の空間圧縮を実現しました。1024³解像度のモデルを約9600トークンで表現でき、既存手法より少ないデータ量で高い品質を維持しています。生成速度も高速で、512³解像度なら約3秒、1536³でも約1分で完了します。





Native and Compact Structured Latents for 3D Generation
Jianfeng Xiang, Xiaoxue Chen, Sicheng Xu, Ruicheng Wang, Zelong Lv, Yu Deng, Hongyuan Zhu, Yue Dong, Hao Zhao, Nicholas Jing Yuan, Jiaolong Yang
Project | Paper | GitHub
3人称視点映像から1人称視点映像を生成するAI「EgoX」
韓国KAISTとソウル大学の研究チームが、3人称視点の動画から1人称視点(POV)の動画を生成する新しいフレームワーク「EgoX」を発表しました。
例えば、スポーツの映像があれば、まるで選手の目で見ているかのような映像を自動生成できます。これまでの手法では複数のカメラアングルや一人称視点の最初のフレームが別途必要でしたが、EgoXは1本の3人称動画だけで動作します。
技術的には、動画拡散モデルの事前学習済み知識を活用し、軽量なLoRA適応で効率的に学習しています。3人称映像を3Dポイントクラウドに変換して1人称視点からレンダリングした事前映像を作成し、これを元の3人称映像と組み合わせて条件付けします。
さらに独自の自己注意機構により、視点変換に関連する領域にのみ注目し、無関係な背景を抑制することで一貫性を保っています。


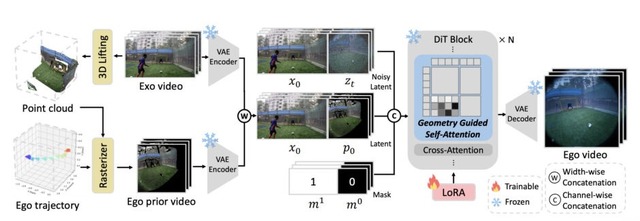

EgoX: Egocentric Video Generation from a Single Exocentric Video
Taewoong Kang, Kinam Kim, Dohyeon Kim, Minho Park, Junha Hyung, Jaegul Choo
Project | Paper | GitHub
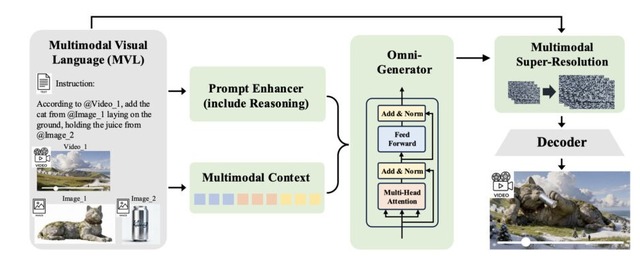
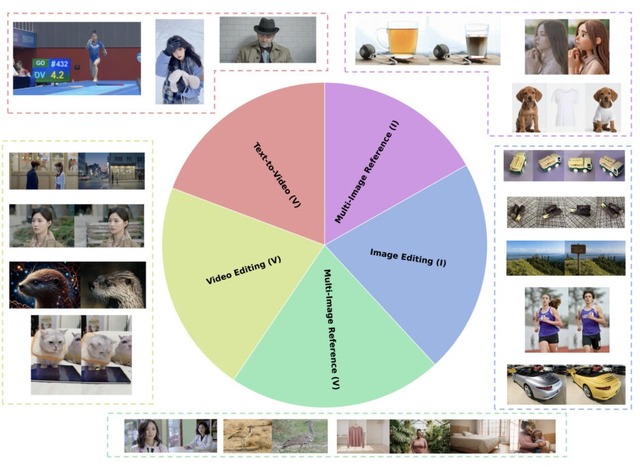
テキスト、画像、動画の同時入力から高品質な動画を生成できる「Kling-Omni」を快手が開発
快手が発表した「Kling-Omni」は、テキスト、画像、動画を組み合わせた入力から高品質な動画を生成できる汎用AIフレームワークです。
従来の動画生成では、テキストから動画を作る、画像を動かす、動画を編集するといったタスクごとに別々のツールやパイプラインが必要でした。またテキストだけでは空間関係や視覚的なニュアンスを伝えるのに限界がありました。
Kling-Omniはマルチモーダル視覚言語(MVL)という仕組みを採用し、「画像1の人物に画像2の服を着せて、画像3の背景で歩かせる」といった複合的な指示を一度に処理できます。
機能面では、参照画像からの動画生成、要素の追加・削除・置換、スタイル変換、天候変更、特殊効果、次ショット生成、カメラモーション転送など幅広いタスクに対応しています。同一人物の異なる角度や表情の写真を複数まとめて参照できる要素ライブラリ機構により、一貫したアイデンティティを保った動画生成が可能です。
推論能力も備えており、GPS座標からエッフェル塔を推論してシーンを生成したり、「6時間後」という指示から環境光や影を自動調整したりできます。評価ではVeo 3.1やRunway Alephと比較して優位性を示しました。