




この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第118回)は、既存の大規模言語モデル(LLM)を特定タスク向けに1.58ビット精度にファインチューニングする軽量アプローチ「BitNet Distillation」や、写真1枚から複数視点画像、動画までを入力に高精度3D空間を生成できるAIモデル「HunyuanWorld-Mirror」を取り上げます。
また、テキストを画像に変換してからAIモデルで効率的に処理するアプローチを提案した論文2本、DeepSeekが発表したOCRモデルと、アレン人工知能研究所などの研究チームが既存マルチモーダルLLMで試した研究をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、LLMが低品質なウェブテキストに継続的に晒されることで、認知機能の低下を引き起こすことを明らかにした研究を別の単体記事で取り上げています。

既存LLMを特定タスク向けに1.58ビット精度にファインチューニングする軽量アプローチ「BitNet Distillation」をマイクロソフトが開発
Microsoft Researchが開発した「BitNet Distillation」(BitDistill)は、既存のLLMを1.58ビット精度(-1、0、1の三値重み)に変換する手法です。2023年に同社が発表した「BitNet」の進化版で、既存のLLMを特定のタスク向けに1.58ビット精度にファインチューニングする軽量パイプラインです。
BitNetには実用上の大きな問題がありました。競争力のある精度を得るには大規模コーパスでゼロから事前学習する必要があり、膨大な計算コストがかかります。また、既存のフルプレシジョンモデルを直接1.58ビットに変換すると、性能が大幅に低下し、モデルサイズが大きくなるほどこの劣化が拡大するという欠点がありました。
BitDistillはBitNetの基盤技術を活用しながら、これらの課題を解決しました。最大の違いは、Qwenなどの既存の高性能LLMを出発点として使用できることです。SubLNモジュール、MiniLMベースの蒸留、継続的事前学習という3段階の最適化により、フルプレシジョンモデルと同等の精度を維持します。モデルサイズが増えても性能劣化が起きない優れたスケーラビリティを実現しました。
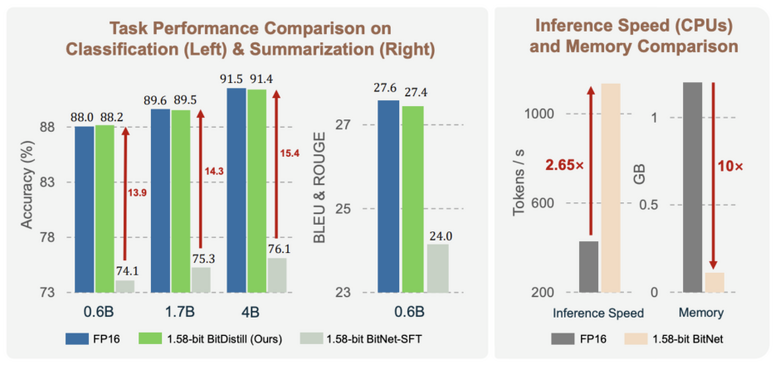
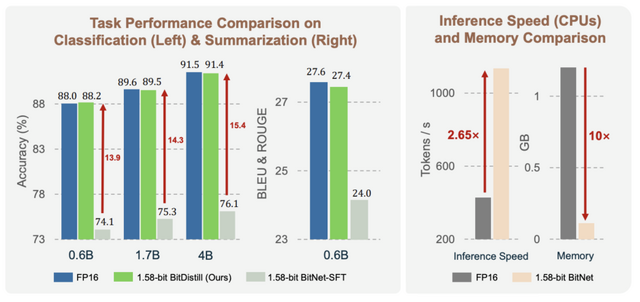
実験結果によると、分類タスクやテキスト要約などの下流タスクにおいて、BitDistillはフルプレシジョンモデルと同等の精度を達成しました。またメモリ使用量を10分の1に削減し、CPU上での推論速度を2.65倍高速化し、レイテンシ、スループット、メモリ効率、エネルギー消費において改善を提供します。これにより、スマートフォンなどのエッジデバイスでの実用的なLLM展開がやりやすくなります。
BitNet Distillation
Xun Wu, Shaohan Huang, Wenhui Wang, Ting Song, Li Dong, Yan Xia, Furu Wei
Paper | GitHub
写真1枚から複数視点画像、動画までを入力に高精度3D空間を生成できるTencent開発のAIモデル「HunyuanWorld-Mirror」
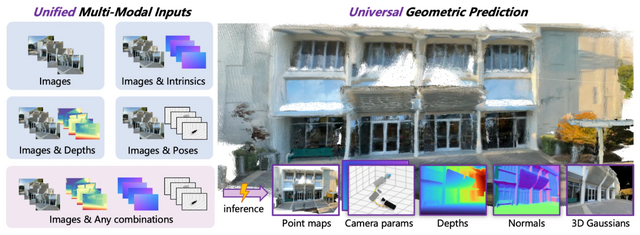
Tencent社が開発した「HunyuanWorld-Mirror」は、画像や動画から立体的な3D空間を数秒で生成できるAIフレームワークです。入力は1枚の画像だけでなく、複数視点の画像、動画に対応しています。
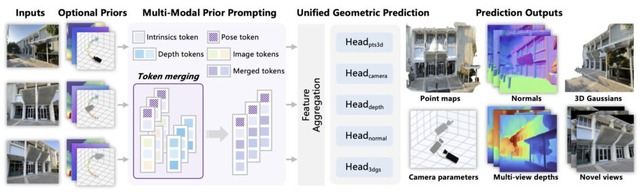
さらに、多様な幾何学的事前情報を柔軟に統合できます。カメラの姿勢や内部パラメータ、深度マップといった追加情報を活用しながら、点群、複数視点の深度マップ、表面法線、3Dガウシアンなど複数の3D表現を同時に生成します。これらの事前情報は、Multi-Modal Prior Promptingという新しいメカニズムによってトークン化され、画像情報と効果的に統合されます。
技術的には、トランスフォーマーベースのアーキテクチャを採用し、カメラパラメータの回帰から密な予測タスクまで統一的なデコーダーヘッドで処理します。トレーニング時には異なる事前情報の組み合わせをランダムにサンプリングすることで、推論時に利用可能な情報が限定的な場合でも柔軟に対応できるよう設計されています。
実験結果では、WorldMirrorは様々なベンチマークで最先端の性能を達成しています。点マップとカメラ推定ではVGGTやπ³などを上回り、表面法線予測ではStableNormalやGeoWizardを凌駕し、新規視点合成ではAnySplatを超える結果を示しました。



長文を画像化して効率的にAI処理する技術「DeepSeek-OCR」をDeepSeekが発表
DeepSeek-AIは、長大な文書コンテキストを画像化して効率的に処理するシステム「DeepSeek-OCR」を発表しました。このシステムは、手書き文書や書籍などをスキャンして画像データに変換する「OCR」(光学文字認識)技術を用いて、テキストを大幅に圧縮することで計算処理を効率化します。
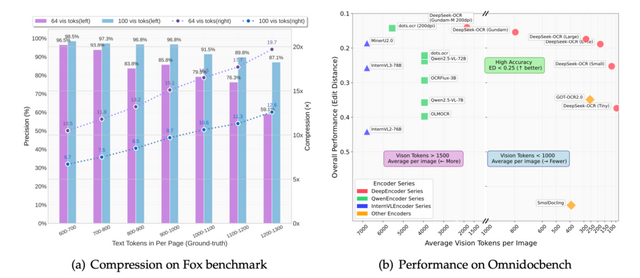
通常、文書を処理する際には大量のトークンが必要ですが、この技術では視覚トークンという圧縮された形式を使用します。実験によると、元のテキストトークンを10分の1に圧縮しても97%という高い文字認識精度を維持でき、20分の1まで圧縮しても約60%の精度を保てることが実証されました。
DeepSeek-OCRは、DeepEncoderとDeepSeek3B-MoE-A570Mデコーダーという2つの主要コンポーネントで構成されています。
OmniDocBenchベンチマークにおいて、DeepSeek-OCRは100個の視覚トークンのみでGOT-OCR2.0(256トークン/ページ)を上回り、800個未満の視覚トークンでMinerU2.0(平均6000トークン以上/ページ)を超える性能を発揮しました。単一のA100-40G GPUで1日あたり20万ページ以上の学習データ生成が可能です。

テキストを画像に変換し、性能を維持したまま計算コストを削減できるかを既存マルチモーダルLLMでテストした研究
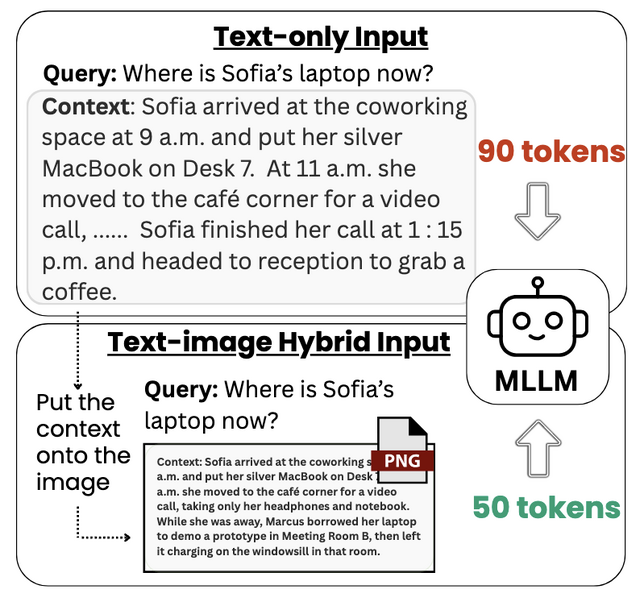
この研究では、長文テキストを単一の画像として描画し、モデルに直接入力することで、マルチモーダル大規模言語モデル(MLLM)の入力トークンを削減しながら性能を維持できるかを試しました。
現在のLLMは、Transformerアーキテクチャにより、入力長に対して計算コストが2次的に増加するという課題を抱えています。研究チームは、GPT-4 VisionやGoogle Gemini 2.5などの最新MLLMが画像からテキストを読み取る能力に着目し、テキストの画像表現を入力圧縮の手段として活用することを検証しました。
研究チームが開発したConTexImageパイプラインは、テキストを制御された解像度の画像に変換し、フォントサイズを自動調整して最適な可読性を確保します。この手法により、大規模モデルでは最大45%のエンドツーエンドの処理速度向上が実現されました。
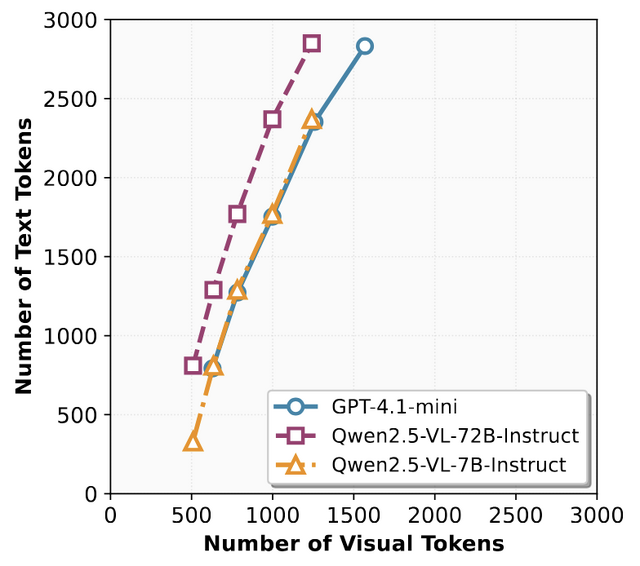
実験では、長文タスクのRULERベンチマークと要約タスクのCNN/DailyMailベンチマークを用いて評価を行いました。GPT-4.1-miniとQwen2.5-VL-72Bモデルは、最大58%少ないデコーダートークンで97~99%の精度を維持し、要約タスクでも既存の圧縮手法を上回る性能を示しました。特に72Bパラメータの大規模モデルは、視覚的に密集したテキスト情報を効果的に処理できることが明らかになりました。
Text or Pixels? It Takes Half: On the Token Efficiency of Visual Text Inputs in Multimodal LLMs
Yanhong Li, Zixuan Lan, Jiawei Zhou
Paper