
実用的なTTS(Text to Speech)が出てもう長いこと経ちます。隠れマルコフモデルを使ったOpen JTalkで自分のボイスクローンを作り、ポッドキャストに参加させたり、RVCで相方の声真似をして遊んだり、いろいろ声の実験をしてきました。
最近は「ポッドキャストできます」というサービスがいろんなところから出てきてますが、一番の脅威はGoogleのNotebookLMでしょう。YouTube、PDF、テキストなどのリソースを与えれば、そのテーマで5、6分のポッドキャスト解説をしてくれるのです。
すでに日本語にも対応していて、次はこれに図解がついた動画解説まで日本語に対応するそうです。すでに使えている人もいますが、自分のところはまだ。今週中には来るでしょうけど、待ちきれません。
そんなところへ、多人数ポッドキャストができるというソフト「VibeVoice」が発表されました。開発したのはマイクロソフトで、なんとMITライセンスのオープンソースソフトです。

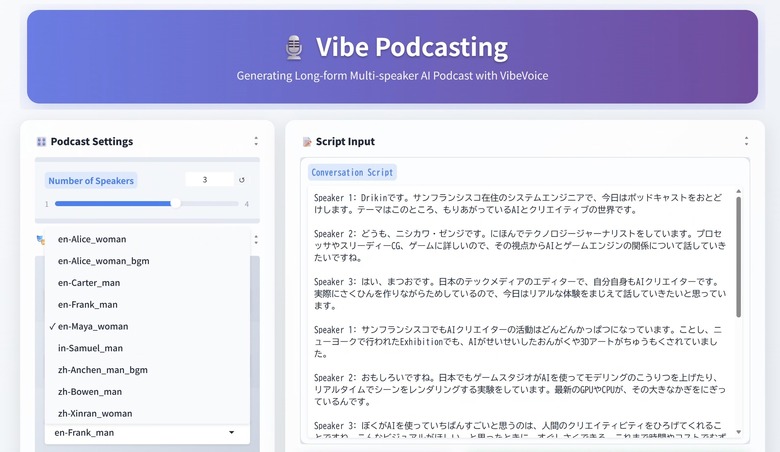
最大で4人まで、Speaker 1、2といったヘッダーをつけた文章をスクリプトとして用意することで、ポッドキャスト風やらいろいろなトーク番組を作っていくことが可能です。表現力も豊かで、コンテキストを理解した感情表現ができるようです。調子っぱずれの歌も出てきます。
歌がちゃんとメロディーになりきれないところは、ChatGPTの音声モードっぽいですね。
残念なのは、対応言語が英語と中国語だけ、というところ。と思っていたら、Xへの投稿で「日本語も通ったよ」というのが流れてきました。じゃあやってみようということで、自分のマシンにインストールしてみました。
Hugging Face Spaceのデモもあるのですが、そちらはキューが大変なことになっていて、まったく進まなかったりエラーになったりで、やはりローカルで、ということになりました。
最初はMacBook Proにインストールを試みたのですが、どうにもうまくいかず(成功した人もいるようですが)、RTX 4090搭載PCで再挑戦。こちらはなんとか設定できました。
スクリプトとして用意したのは、自分でやっているポッドキャスト番組のパートナーたちの設定を借りて、ChatGPTに適当に作ってもらったもの。
日本語未対応というだけあって、日本語は通ったり通らなかったり。ひらがな・カタカナのみにしても不思議な感じになったので、いったん漢字・かな混じりで流しながら、おかしいところを重点的にひらがな・カタカナに開いていく地道な修正をしていきました。
こういうのが可能なのも、生成スピードが非常に速いからです。
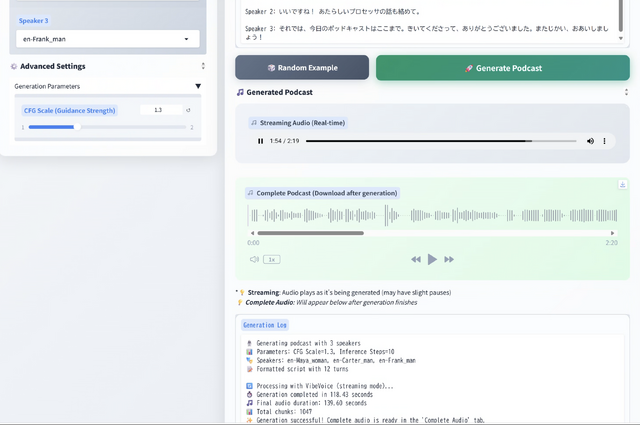
2分30秒のオーディオファイルを作るのに、2分ですみました。実時間より高速です。オーディオは途中からストリーミングされるので、27秒あたりから聞こえ始めます。
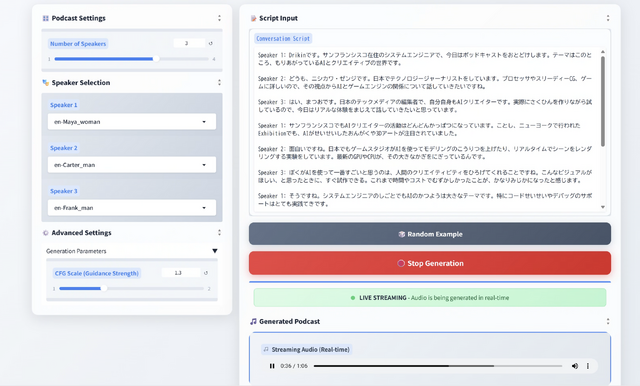
NotebookLMの場合は生成にかなりの時間がかかるのと、いったん生成してしまったら修正できないのが弱点です。VibeVoiceはローカルPCで高速に生成できるので、そこはあまり気にせずにガンガン修正していけます。
最終的に、スクリプトはだいぶ漢字が少なくなり、話しにくい言葉は別の英単語に置き換えたりしました。
最終的なスクリプトはこちら。
Speaker 1: Drikinです。サンフランシスコ在住のシステムエンジニアで、今日はポッドキャストをおとどけします。テーマはこのところ、もりあがっているAIとクリエイティブの世界です。
Speaker 2: どうも、ニシカワ・ゼンジです。にほんでテクノロジージャーナリストをしています。プロセッサやスリーディーCG、ゲームに詳しいので、その視点からAIとゲームエンジンの関係について話していきたいですね。
Speaker 3: はい、まつおです。日本のテックメディアのエディターで、自分自身もAIクリエイターです。実際にさくひんを作りながらためしているので、今日はリアルな体験をまじえて話していきたいと思っています。
Speaker 1: サンフランシスコでもAIクリエイターの活動はどんどんかっぱつになっています。ことし、ニューヨークで行われたExhibitionでも、AIがせいせいしたおんがくや3Dアートがちゅうもくされていました。
Speaker 2: おもしろいですね。日本でもゲームスタジオがAIを使ってモデリングのこうりつを上げたり、リアルタイムでシーンをレンダリングする実験をしています。最新のGPUやCPUが、その大きなかぎをにぎっているんです。
Speaker 3: ぼくがAIを使っていちばんすごいと思うのは、人間のクリエイティビティをひろげてくれることですね。こんなビジュアルがほしい、と思ったときに、すぐしさくできる。これまで時間やコストでむずかしかったことが、かなりみじかになったと感じます。
Speaker 1: そうですね。システムエンジニアのしごとでもAIのかつようは大きなテーマです。特にコードせいせいやデバッグのサポートはとてもじっせんてきです。
Speaker 2: ゲームのせかいでも同じです。クリエイターが作りたいシーンを素早くかたちにできることは、プレイヤー体験を進化させるかぎになるでしょう。
Speaker 3: 結局、AIと人間のきょうぞんが重要なんですよね。クリエイターのいしをどうAIに乗せるか、そこが面白くも難しい部分だと思います。
Speaker 1: 今日はこのへんでしめましょうか。次回はもっとグラフィックスやゲームエンジンについてふかぼりしてみたいですね。
Speaker 2: いいですね! あたらしいプロセッサの話も絡めて。
Speaker 3: それでは、今日のポッドキャストはここまで。きいてくださって、ありがとうございました。またじかい、おあいしましょう!
漢字とすべきところがひらがなになっているのは、そうしないと読み間違えるからです。たぶん、中国語っぽく読んじゃうんでしょうね。
そうこうして、長さ2分半の複数話者ポッドキャストが出来上がったのでした。
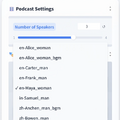
使った話者はいずれも本来は英語キャラクターなのですが、一応日本語をしゃべれています。これはこれで面白いですね。もちろん、中国語話者に日本語を無理やり話させることもできます。
Speaker Selectionというところで、話者を選ぶようになっています。
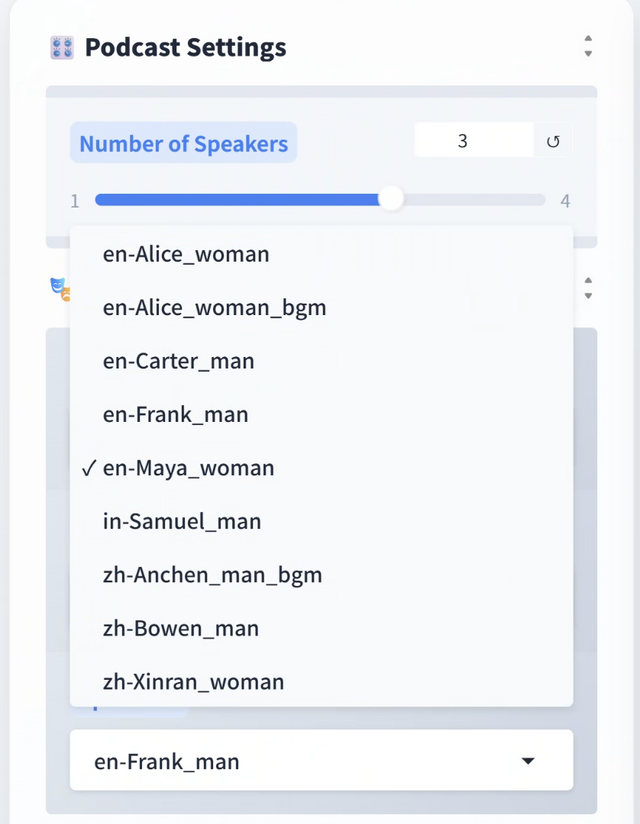
現在のところ、ボイスクローンはできないのですが、そういえばマイクロソフトはゼロショットのボイスクローン技術を持っていたのにコードを公開してませんでしたね。
同様の技術はすでに多くのオープンソースソフトが公開されています。数秒のボイスサンプルで本人に近いText to SpeechができるXTTS v2という技術は、筆者が先週実装した、妻のAIアバターの音声部分でも使っています。

VibeVoice自身、LLMとしては自社のPhiではなくてQwenを使っているようですし、ボイスクローン機能も追加してくれないですかね。
VibeVoiceのもう一つすごいのは、スクリプトは長くてもOKなところ。最長で90分の対話音声を作ることができるのです。
これはわれわれ人間のポッドキャスターもうかうかしていられません。
でもとりあえずは大丈夫。backspace.fmは毎回2時間以上あるから……。
ところで、VibeVoiceというネーミングはその昔、IBMが売っていたViaVoiceを絶対に意識してるんだと思うんですよね。あれは音声認識ソフトでしたけど。