









生成AIグラビアをグラビアカメラマンが作るとどうなる? 連載記事一覧
Z-Image-Turboその後
11月27日にAlibabaからリリースされたZ-Image-Turbo、BASEやEditはまだであるが、結構いろいろ出てきたのでご紹介したい。
その前にBASEとEditは、どうやら1本にまとまるらしく、公式から情報が出ている。これに関しては、Qwen-ImageとQwen-Image-Edit (2509)、どちらも同レベルの生成ができるのに何故2つに分けているのか不思議だった筆者にとっては「だよね」的な内容となる。
Turboはsteps 9、CFG 1で高速生成が特徴の一つだが、非蒸留モデルになると、一般的にstepsは20~30、CFGは1より大きくなるため、結果、Turboより最低でも4倍の時間がかかる事が予想される(CFGが1より大きくなるとNegative Promptも使えるためサンプリングに倍かかる)。
そうなった場合、RTX 5090で1024x1536px 約5秒のところが20秒と遅くなってしまうので、8 steps LoRAやNunchakuの対応を望みたいところ。
リリース時期は近々から変わっておらず、もしかすると本原稿公開直後……とか、あるあるかも知れない(笑)。
いろいろ出てきたAI美女LoRAとTrainedなCheckpoint
リアル系のAI美女LoRAはさらに増え続けている。まず前回ご紹介したReversal Film Gravure for z_image_turboが早くもV2となって登場。以下、V2とV1の比較だが、V2の方がよりいい感じになっている。
 |  |
次は、SDXLやFLUX.1、Qwen-Image版もあったAWPortraitがZ-Image-Turboに対応した。比較を見る限り大きな違いはないが、肌や眼の感じが向上している。
 |  |
Z-Image-Turbo (LoRAなし)
Z-Image-Turbo + AWPortrait-Z (strength: 0.8)
次はTrainedモデル。タイプ的にMergeとTrainedがあり、前者は学習せずいろいろなモデルを調合して新しいモデルを作るパターン、後者は学習(FT)する。LoRAと違って結構手間と時間がかかるため、一般的になかなか出てこないのだが、たった2週間で出てきたのには驚きに値する。
もう一つは一応生成も可能であるが、LoRAなどの学習用として使う蒸留解除タイプのZ-Image-De-Turbo。これはai-toolkitを作ったostrisからリリースされた。
実際LoRAを作ると分かるが、蒸留タイプのZ-Image-Turboのままだとほとんど効果がないのに対し、この蒸留解除タイプを使うと明らかに効果がある。作例は他と同じPromptだが、steps 20、cfg 3.5になっている。
 |  |
 |  |
Z-Image-Turbo
Zimage Turbo by Stable Yogi
※ 前回同様の”a young japanese woman”。設定も全て同じ
以上が12月中旬までに出てきた主なLoRAとCheckpointとなる。Civitaiを眺めていると毎日物凄い量のLoRAが登録されているが、真面目なリアル系(笑)は他と比べると少な目で今後に期待したい。
高精細化VAEと高性能アップスケーラそして…
Z-Image-Turbo専用では無いが、VAEにae.safetensorsを使っているものに有効なVAE。4Kの画像から学習したそうで、これに入れ替えるだけで絶大な効果がある。以下、それぞれ並べているが、通常のaeとUltraFlux-v1とでは圧倒的な違いが出ている。使わない手はないだろう。
 |  |
VAEにae.safetensors使用
VAEにUltraFlux-v1使用
次は汎用だが、動画用のUpscaler、SEEDVR2を画像に応用したカスタムNodeとWorkflow。デフォルトだと長辺を4000pxまでアップスケールする。
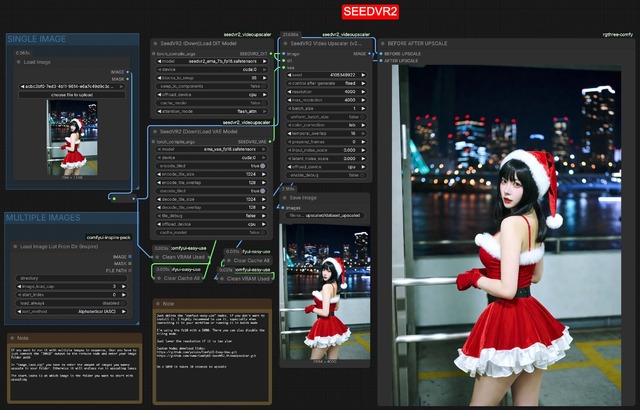

これまでいろいろなUpscalerを使ってきたが、このSEEDVR2を使ったものは
色が変わらない
変なものが生えたり、違うものになったりしない
そこそこ処理も速い
この3つが良い点となる。とにかくこれまで個人的に満足できるのもがなかったので、SEEDVR2を使ったUpscalerの登場には嬉しい限り。
Workflowはここ。その他必要なカスタムNodeは以下となる。
https://github.com/yolain/ComfyUI-Easy-Use.git
https://github.com/numz/ComfyUI-SeedVR2_VideoUpscaler.git
https://github.com/ltdrdata/ComfyUI-Inspire-Pack
※ Load Image List From Dir (Inspire) Nodeを使わなければ不要
そしてControlNetのZ-Image-Turbo-Fun-Controlnet-Unionが2.0になり、より自然に、特にLoRAとの併用でもあまり影響が出ないようになった。これはComfyUIのUpdateが必要となる。
 |  |
なおWorkflowに関しては前回触れているのでそちらをご覧いただきたい。

最後、少し面白いのが、Z-Image-Turbo Prompt拡張専用LLM、qwen3-4b-Z-Image-Engineer。これをLM Studioなどで読み込み、適当にPromptを入れると、Z-Image-Turboに最適化されたPromptが生成される。qwen3-4bなので日本語でも問題無い。
加えてHereticと言う技術で(ほぼ)無検閲化しているのも嬉しいポイントだ。小さいモデルなのでCPUでもある程度は動くと思うので興味のある人はぜひ試して欲しい。
今回締めのグラビア
今回、扉はCyberRealistic Z-Image Turbo、グラビア(スナップ?)はZ-Image-Turbo + 謎のLoRA(笑)。Z-Image-Turboだと長辺1920pxをダイレクトに作れるが、VAEにUltraFlux-v1、1MPで生成、SEEDVR2で一旦4Kにして長辺1920pxへ縮小している。なかなかいい感じだと思うが如何だろうか!?

年内はこの原稿で終わり(Z-Image Basse/Editが出れば緊急掲載するかも知れないが)。去年のこの時期、2025年はもうオープンなモデルは出ないのではないかと思っていたが、予想に反して夏の陣、秋の陣と連打のリリース。追いかけるのが大変なほどだった。来年はどうなるのか? これだけハイペースで発表が続くと、もう誰にも予想できない(笑)。


![生成AIグラビアをグラビアカメラマンが作るとどうなる?第55回:2025年秋の陣Part 1はFLUX.2 [dev]でローカル生成(西川和久) 画像](/imgs/p/KS0xA70UphpJ5g7PcXQyhA2bwJXOlZSTkpGQ/28690.jpg)














