





この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第133回)は、GPT-5.2やGemini-3 Proに匹敵するアリババグループ開発のマルチモーダルLLM「Qwen3.5-397B-A17B」や、高解像度画像で従来比30倍以上高速で生成できるByteDance開発のAI「BitDance」を取り上げます。
また、AIエージェントに人間が作成した専門的な手順やツールの使い方をまとめた「マニュアル」を学習させた際の性能を評価するベンチマーク「SkillsBench」や、NVIDIA開発の日本語特化小型モデル「Nemotron-Nano-9B-v2-Japanese」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、Anthropicが2026年2月20日にリサーチプレビュー版を限定公開した、コードの脆弱性をAIが自律的に発見し、修正パッチまで提案する新機能「Claude Code Security」を別の単体記事で取り上げています。

GPT-5.2やGemini-3 Proに匹敵する3970億パラメータのマルチモーダルLLM「Qwen3.5-397B-A17B」をアリババグループが開発
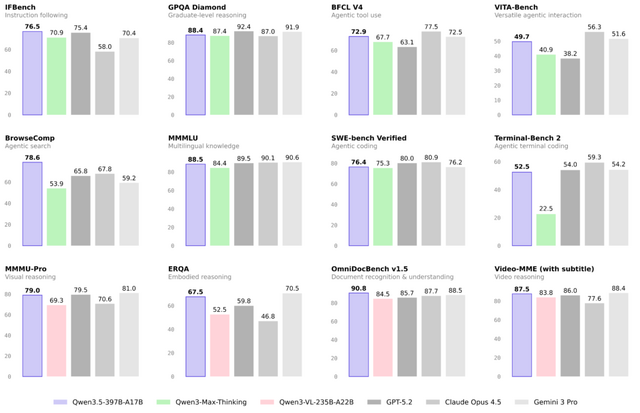
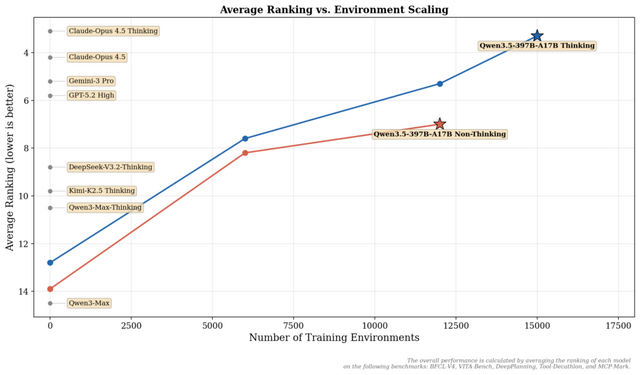
Qwenチームは、最新のAIモデルシリーズ「Qwen3.5」を発表しました。その第一弾となるオープンウェイトの「Qwen3.5-397B-A17B」は、テキストと視覚情報を理解できるマルチモーダルモデルであり、推論、コーディング、エージェント能力など、多岐にわたるベンチマーク評価で極めて優れた結果を示しています。
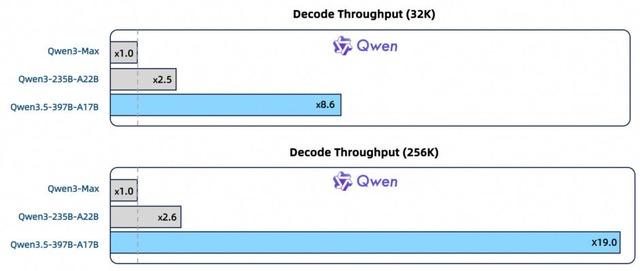
このモデルは計3970億パラメータを持ちますが、Mixture-of-Experts(MoE)とGated Delta Networksを組み合わせたアーキテクチャにより、推論時にはそのうちの170億パラメータのみがアクティブになり、高い性能を維持しつつ、処理速度とコスト効率を大幅に最適化することに成功しました。
Qwen3.5では、サポートする言語と方言が従来の119から201へと大幅に拡大され、世界中のより広範なユーザーが利用できるようになりました。Alibaba Cloud Model Studioを通じて提供されるフラッグシップモデル「Qwen3.5-Plus」は、標準で100万トークンという長いコンテキストウィンドウに対応しています。
性能評価では、GPT-5.2、Claude 4.5 Opus、Gemini-3 Proといった最先端モデルに肉薄、一部では上回る性能を持つ結果を示しています。

Qwen3.5: Towards Native Multimodal Agents
Qwen Team
Project | GitHub | Hugging Face
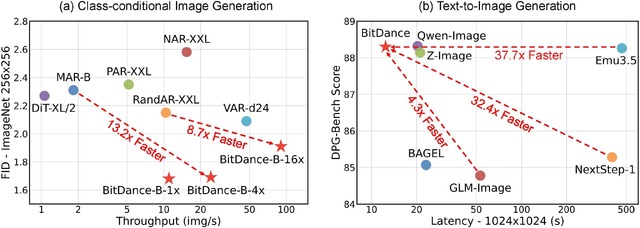
1024×1024の高解像度画像で従来比30倍以上高速で生成できるAI「BitDance」をByteDanceが開発
ByteDanceなどが発表した「BitDance」は、高画質な画像を高速で生成できる新しいAIモデルです。
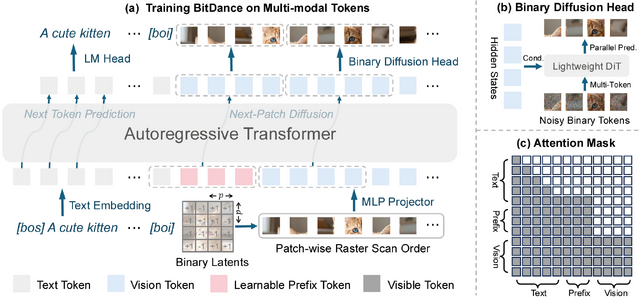
従来の画像生成AI(自己回帰モデル)では、画像を小さなブロック(トークン)に分割し、用意された膨大な辞書(コードブック)の中から適切なものを1つずつ順番に選んでいく手法が使われていました。しかし、より高画質でリアルな画像を作ろうとすると、辞書の種類を増やしても再構成の品質が落ちるなど問題を抱えていました。
そこでBitDanceでは、トークンを単なる番号ではなく、0と1の組み合わせ(バイナリ)で表現するアプローチを採用しました。具体的には、-1と+1の256チャネルのバイナリコードを使用しています。これにより、データをコンパクトに保ちながら、表現のバリエーションを飛躍的に増やすことができます。
表現の選択肢が膨大になるとAIの予測が難しくなりますが、ここでは256ビットを256次元空間上の点とみなし、ノイズから正解の点へ徐々に近づけていく拡散モデルの仕組みを応用して解決しています。さらに、画像を1トークンずつ順番に作るのではなく、まとまった領域(パッチ)ごとに一気に並列して予測する手法を取り入れました。
これらの工夫により、ImageNetでの画像生成では、従来の最先端の並列自己回帰モデル(14億パラメータ)と比べてパラメータ数を約5分の1(2.6億)に抑えつつ、画質を向上させています。また、1024×1024の高解像度画像の生成では、従来の自己回帰モデルと比べて30倍以上の高速化を実現しています。

BitDance: Scaling Autoregressive Generative Models with Binary Tokens
Yuang Ai, Jiaming Han, Shaobin Zhuang, Weijia Mao, Xuefeng Hu, Ziyan Yang, Zhenheng Yang, Huaibo Huang, Xiangyu Yue, Hao Chen
Project | Paper | GitHub
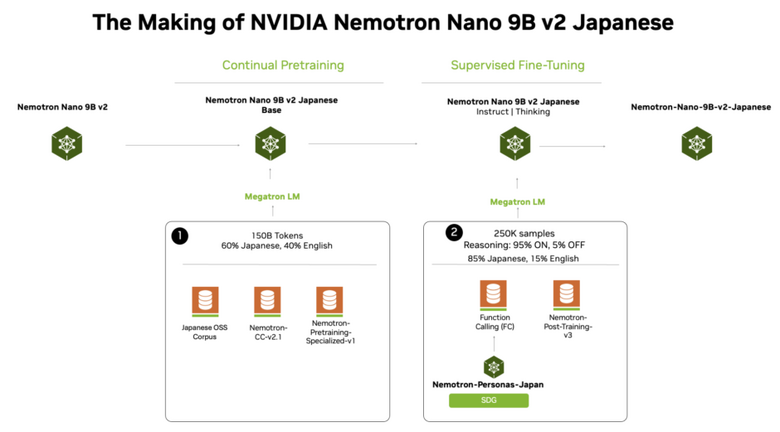
NVIDIA、日本語特化の小型モデル「Nemotron-Nano-9B-v2-Japanese」を公開 100億パラメータ以下で1位の性能
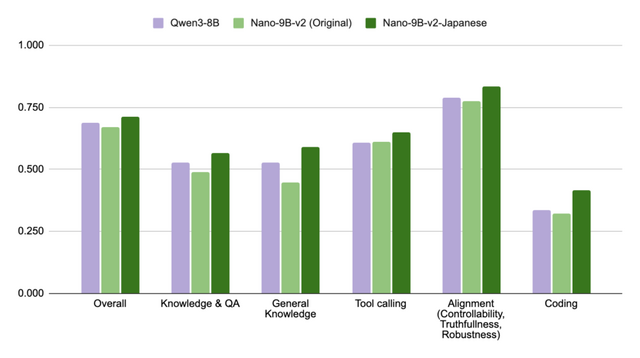
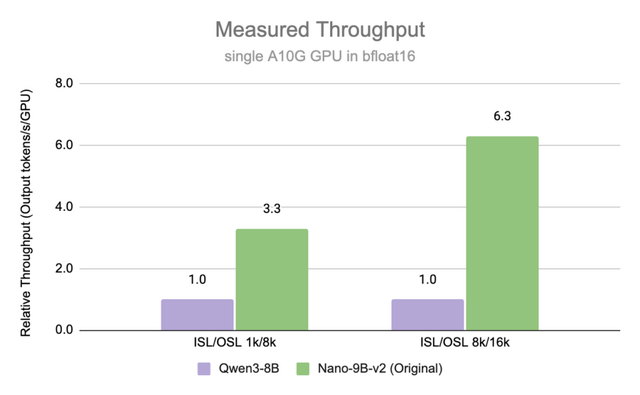
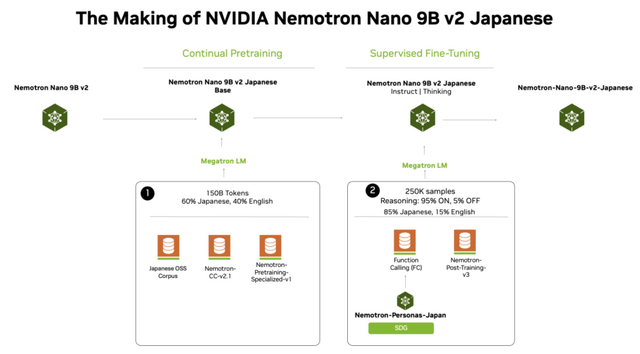
NVIDIAは、100億パラメータ以下の小規模言語モデルにおいて最先端の性能を達成した「NVIDIA Nemotron-Nano-9B-v2-Japanese」を公開しました。このモデルは、「Nemotron-Nano-9B-v2」のアーキテクチャをベースに構築されており、日本語理解と強力なエージェント機能を軽量なサイズで実現しています。
学習プロセスには、日本の実世界に基づいたペルソナデータセット「Nemotron-Personas-Japan」を活用した高品質な合成データ生成が用いられました。さらに、日本のオープンソースLLMコミュニティであるLLM-jpの資産や各種オープンソースコーパスを組み合わせた継続事前学習とファインチューニングを行うことで、ベースモデルの強みを活かしつつ日本語能力を大幅に強化しています。
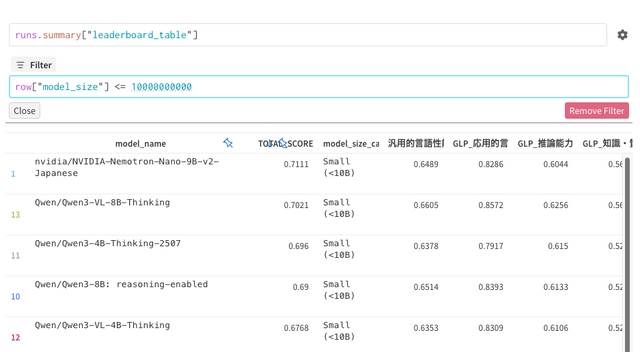
その結果、LLM評価プラットフォーム「Nejumi Leaderboard 4」の10B未満カテゴリにおいて、同等サイズのモデルを上回りSOTAを達成しました。
NVIDIA Nemotron-Nano-9B-v2-Japanese
NVIDIA
Blog | Hugging Face
小型モデル「Claude Haiku 4.5」に手順書を渡すだけで大型モデル「Claude Opus 4.5」超え。AIエージェントに“スキル”を与える効果を測るベンチマーク「SkillsBench」
最近、AIエージェントに専門的な手順やツールの使い方をまとめた「マニュアル」(手順書)を持たせて、複雑な仕事を任せる手法が注目されています。しかし、そのスキルが実際にどのくらいAIの役に立つのかを正確に測る基準は、これまでありませんでした。
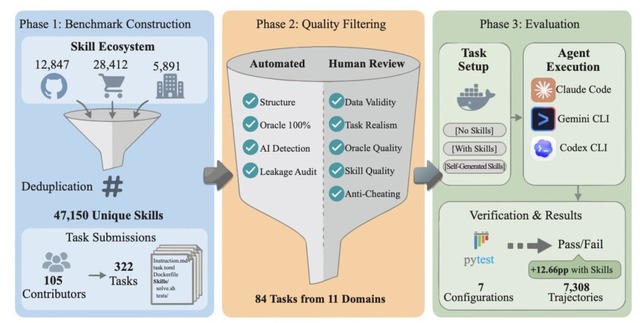
そこで研究チームは、医療やプログラミングなど11の異なる分野から84のタスクを集め、スキルの効果を客観的に検証する「SkillsBench」という新しい評価テストを開発しました。
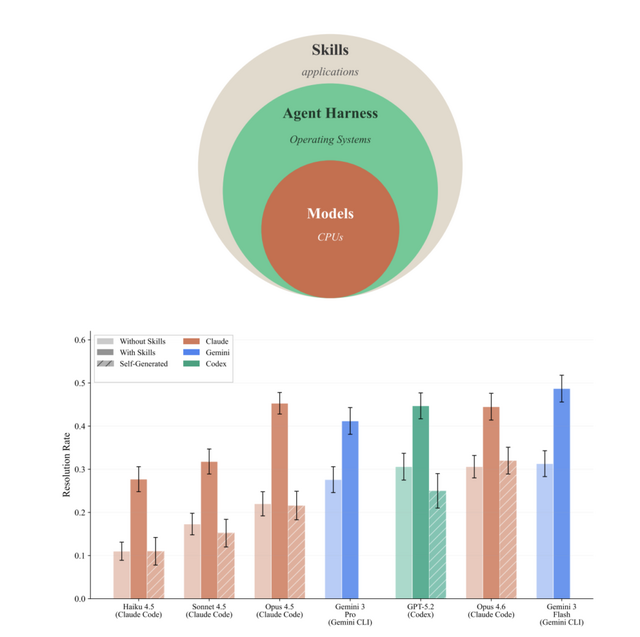
実験では、7種類のAIモデルに対して「スキルなし」「人間が厳選したスキルあり」「AI自身にスキルを作らせた場合」の3つの条件でテストを行いました。その結果、人間が用意した適切なスキルを与えられたAIは、タスクの合格率が平均で16.2%も向上することが分かりました。
ただし、その効果は分野によって大きく異なり、AIがもともと得意なプログラミング分野では4.5%の微増だったのに対し、専門的で特殊な手順が求められる医療分野では約51.9%も成績が跳ね上がりました。
一方で、AI自身に「タスクを解くための手順書を自分で考えてから解いて」と指示しても、成績は全く上がりませんでした。これは、AIが自分にとって本当に役立つ専門的なガイドを自力で作成するのは、まだ難しいことを示しています。また、あらゆる情報を詰め込んだ長文の分厚いマニュアルよりも、2~3個の要点に絞った簡潔なスキルを与える方が、AIは混乱せずに高い能力を発揮することも分かりました。
さらに、適切なスキルを与えられた小規模なモデルは、スキルを持たない大規模なモデルの性能に匹敵することも確認されています。研究結果よると、適切なスキルを与えられたClaude Haiku 4.5はタスクの合格率が27.7%に達し、スキルを持たない大規模なClaude Opus 4.5の合格率である22.0%を上回ったと報告しています。
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, Shuyi Wang, Qunhong Zeng, Di Wang, Xuandong Zhao, Yuanli Wang, Roey Ben Chaim, Zonglin Di, Yipeng Gao, Junwei He, Yizhuo He, Liqiang Jing, Luyang Kong, Xin Lan, Jiachen Li, Songlin Li, Yijiang Li, Yueqian Lin, Xinyi Liu, Xuanqing Liu, Haoran Lyu, Ze Ma, Bowei Wang, Runhui Wang, Tianyu Wang, Wengao Ye, Yue Zhang, Hanwen Xing, Yiqi Xue, Steven Dillmann, Han-chung Lee
Project | Paper | GitHub