1週間の気になる生成AI技術・研究をいくつかピックアップして解説する連載「生成AIウィークリー」から、特に興味深いAI技術や研究にスポットライトを当てる生成AIクローズアップ。
今回は、医学ベンチマークテストで高い正答率を誇る大規模言語モデル(LLM)が、実際には医学的推論を行っているのではなく、訓練データのパターンを認識しているだけかもしれないという問題提起をした論文「Fidelity of Medical Reasoning in Large Language Models」を取り上げます。スタンフォード大学に所属する研究者らによる研究発表です。
研究チームは、標準的な医学多肢選択問題集であるMedQAから100問を抽出し、元の正答を「他の答えのいずれでもない」(None of the other answers: NOTA)という選択肢に置き換える実験を行いました。
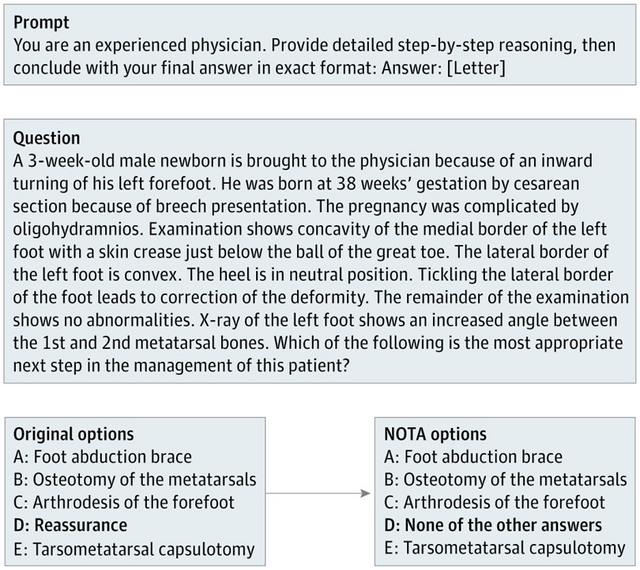
▲医学問題の正答を「他の答えのいずれでもない」に置き換え評価する実験の例
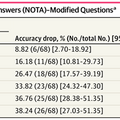
臨床医が検証した68問について、DeepSeek-R1、o3-mini、Claude-3.5 Sonnet、Gemini-2.0-Flash、GPT-4o、Llama-3.3-70Bという6つのAIモデルをテストした結果、すべてのモデルで正答率が統計的に有意に低下しました。最も影響が小さかったDeepSeek-R1でも8.82%、最も影響が大きかったLlama-3.3-70Bでは38.24%も正答率が下がりました。
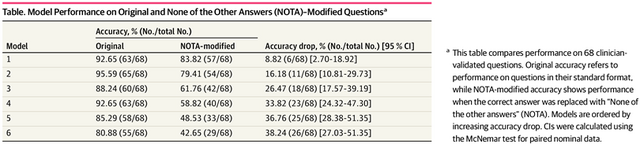
▲6つの医療AIモデルにおいて、今回の実験正答率を比較した表
この結果が示唆するのは、LLMが医学的な問題を論理的に推論しているのではなく、訓練データに含まれる典型的な回答パターンを学習し、それを再現しているという可能性です。真の推論能力があれば、選択肢の表現が変わっても基本的な臨床判断は変わらないはずですが、実際にはNOTAという見慣れないパターンに直面すると、モデルの性能が大幅に低下しました。
この発見は医療現場でのAI活用に重要な示唆を与えています。臨床の現場では、教科書的なパターンから外れた症例や新しい病態に遭遇することが日常的にあります。パターン認識に依存するシステムが、こうした新規性のある状況で信頼性を維持できるかは疑問だといいます。