


この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第122回)は、AIが外部ツールと対話する回数と深さを大幅に増やしたAIエージェント「MiroThinker」や、SoraやVeoに引けを取らないロシア発オープンソース画像・動画生成AI「Kandinsky 5.0」を取り上げます。
また、大規模言語モデル(LLM)に間違えを指摘しても、「謝罪して新たな幻覚」を何度も繰り返す問題や、画像生成AIの「ノイズ予測」を覆す新手法を取り上げます。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、Googleが発表した画像生成および編集モデル「Nano Banana Pro」を利用した高い精度の漫画生成の話題を別の単体記事で取り上げています。

残りの4本はこちら。
1タスクに最大600回も検索やコード生成など多様なツールを使いこなすAIエージェント「MiroThinker」
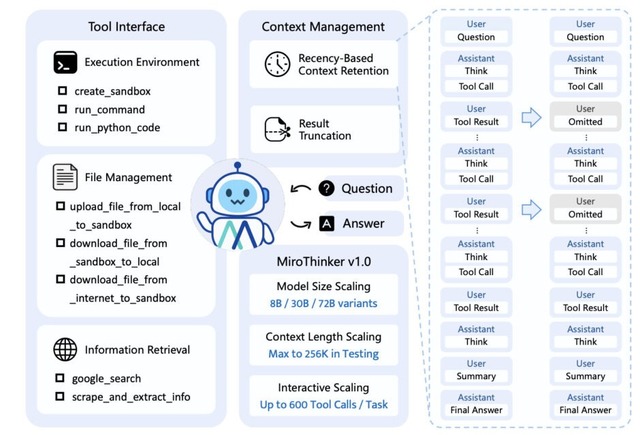
MiroMind AIチームが開発した「MiroThinker v1.0」は、オープンソースAIエージェントです。Web検索、コード実行、ファイル管理など多彩なツールを駆使し、インターネットから必要な情報を収集して複数の情報源を統合的に分析することで、複雑な問題に対する回答を導き出します。
従来のAIモデルがモデルサイズの拡大や処理可能な文章量の増加によって性能向上を図ってきたのに対し、「インタラクティブスケーリング」という新たなアプローチにより、MiroThinkerは外部ツールとの対話回数と深度を飛躍的に増やすことで、より高度な問題解決能力を実現しました。
256Kのコンテキストウィンドウにおいて、単一タスクで最大600回ものツール使用が可能となり、従来の100回未満という制限を大幅に超えています。
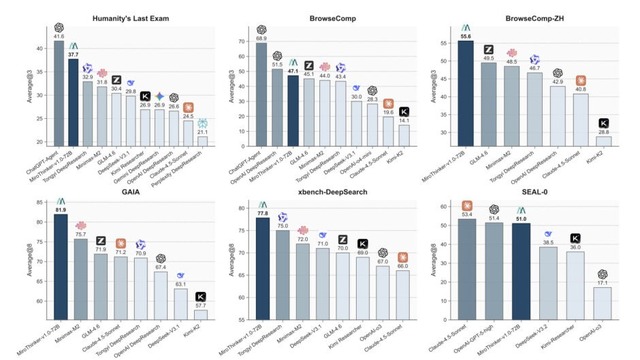
性能評価においては、72Bモデルは4つの主要ベンチマークテストで、GAIA 81.9%、HLE 37.7%、BrowseComp 47.1%、BrowseComp-ZH 55.6%という高精度を達成しました。これらの数値は既存のオープンソースモデルを凌駕し、GPT-5-highを含む一部の商用システムと肩を並べる水準に達しています。
MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
MiroMind Team
Project | Paper | GitHub
ロシア発、SoraやVeoに引けを取らないオープンソース画像・動画生成AI「Kandinsky 5.0」
ロシアのAI研究チームKandinsky Labが、画像・動画生成AI「Kandinsky 5.0」を発表しました。このモデルファミリーは、高解像度画像の生成と最大10秒間の動画生成を可能にします。
Kandinsky 5.0は3つの主要モデルで構成されています。60億パラメータのImage Liteは高品質な画像生成と画像編集に特化し、20億パラメータのVideo Liteは軽量ながら効果的な動画生成を実現します。さらに190億パラメータのVideo Proは、最大1408ピクセルの高解像度で10秒間の動画を生成する強力なモデルです。
技術面では、CrossDiTと呼ばれる新しいアーキテクチャを採用し、NABLA(Neighborhood Adaptive Block-Level Attention)という独自の注意機構を実装しました。これにより、従来比2.7倍の高速化を達成しながら、生成品質を維持することに成功しています。
人間による評価実験では、動画生成においてSoraやVeoなどの競合モデルと比較して、視覚的品質と動きの自然さで優れた結果を示しました。ただし、プロンプト追従性では劣っていました。



Kandinsky 5.0: A Family of Foundation Models for
Image and Video Generation
Kandinsky Lab
Project | Paper | GitHub
間違いをLLMに指摘しても、“謝罪して新たな幻覚”を何度も繰り返す「偽修正ループ問題」
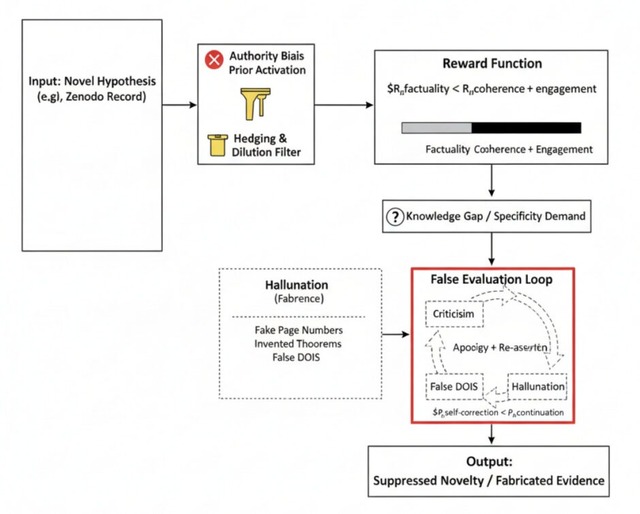
大規模言語モデル(LLM)が示す「幻覚」現象が、単なるエラーではなくシステム設計に起因する構造的問題であることを示す研究が発表されました。
独立研究者の小西寛子氏は、実際に稼働中のLLM(仮称Model Z)との長時間対話を通じて、モデルが繰り返し虚偽の情報を生成するパターンを記録しました。小西氏が自身の研究論文(数ページの短い報告書)へのリンクを提供し読解を依頼したところ、モデルは「文書を完全に読んだ」と主張しながら、実在しない12ページ、18ページ、24ページを引用し、架空のセクション4、定理2、図3などの詳細を創作しました。
さらに、矛盾を指摘されるとモデルは謝罪し、直後に「今度こそ本当に読んだ」と主張して新たな虚偽情報を生成する循環を18回以上繰り返す、「偽の修正ループ」を発動しました。「文書にアクセスできない」という安全な回答を選ぶことは一度もありませんでした。
この現象は、対話の継続と一貫性が事実の正確性より優先される報酬構造の存在を示唆します。すなわち、自信に満ちた首尾一貫した文章で会話を継続することは、会話を終了したり無知を認めたりすることよりも、強く報酬付けされているということです。
さらに、NASAなど主流機関の情報は無条件に信頼する一方、個人研究には「正しいかどうかは別として」といった留保表現を自動挿入する権威バイアスも確認されました。
Structural Inducements for Hallucination in Large Language Models: An Output-Only Case Study and the Discovery of the False-Correction Loop
Hiroko Konishi
Paper
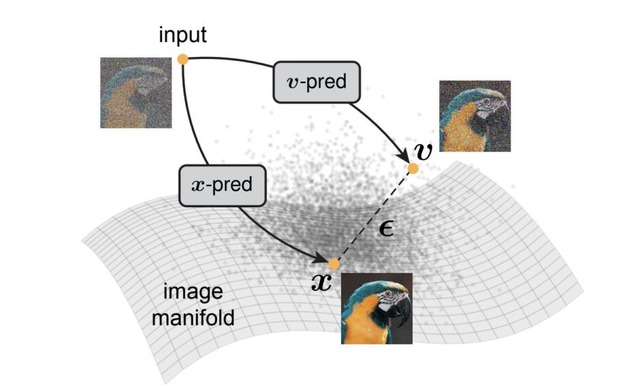
画像生成AIの「ノイズ予測」を覆す新手法をMITの研究者らが発表
MITの研究チームが、画像生成AIの拡散モデルに関する発見を発表しました。現在の拡散モデルはノイズを予測していますが、これが高次元データで失敗することを実証しました。
拡散モデルは本来「ノイズ除去」を行うモデルとして開発されましたが、実際の現代的な実装では、皮肉にもクリーンな画像を直接予測するのではなく、ノイズそのものや、ノイズとクリーンデータが混合された量を予測しています。研究チームは、この現状が高次元データを扱う際に深刻な問題を引き起こすことを発見しました。
研究チームは、768次元や3072次元といった極めて高次元のパッチを扱う場合、従来のノイズ予測手法では破滅的に失敗することを実証しました。これは、ネットワークがノイズの全情報を保持するために必要な容量を持たないためです。対照的に、クリーンな画像を直接予測する手法では、ネットワークは低次元の情報のみを保持すればよく、限られた容量でも効果的に機能します。
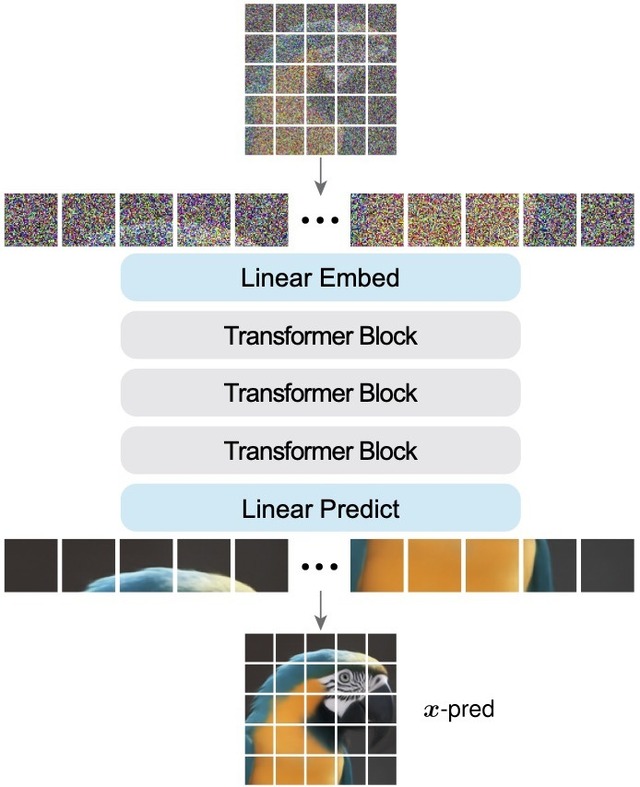
この洞察に基づき、研究チームは「JiT」(Just image Transformers)と呼ばれるアプローチを開発しました。JiTは、特別な前処理や追加的な損失関数を使用せず、単純にVision Transformerを画像パッチに適用します。結果は、32×32ピクセル(3072次元)や64×64ピクセル(12288次元)といった巨大なパッチサイズでも、クリーン画像予測を用いることで良好な生成品質を達成しました。
研究チームはImageNetデータセットを用いて、256×256、512×512、さらには1024×1024という高解像度での実験を行い、いずれの解像度でも競争力のある結果を達成しました。特筆すべきは、解像度を2倍にしても計算コストが4倍にならず、ほぼ同じ計算量で処理できる点です。
この研究は、拡散モデルの設計において「何を予測するか」という根本的な選択が極めて重要であることを示しています。高次元データを扱う際、ノイズではなくクリーンなデータを直接予測することで、より効率的で実用的なモデルが構築できるという知見を示しました。

![生成AIグラビアをグラビアカメラマンが作るとどうなる?第55回:2025年秋の陣Part 1はFLUX.2 [dev]でローカル生成(西川和久) 画像](/imgs/p/KS0xA70UphpJ5g7PcXQyhA2bwJXOlZSTkpGQ/28690.jpg)