1週間の気になる生成AI技術・研究をいくつかピックアップして解説する連載「生成AIウィークリー」から、特に興味深いAI技術や研究にスポットライトを当てる生成AIクローズアップ。
今回は、ローカルで起動できるリアルタイム文字起こしAI「Moonshine Voice」を取り上げます。
▲Moonshine Voiceリポジトリのスクリーンショット
OpenAIの音声認識モデル「Whisper」は、リアルタイムの音声インタフェースとして組み込む場合にはいくつかの弱点を抱えています。まず、常に30秒の音声を処理する仕様のため、短い発話であっても空白部分の処理に計算リソースを浪費し、結果として応答遅延(レイテンシ)が生じやすくなります。
また、継続的な音声入力に対してもキャッシュの仕組みを持たず毎回ゼロから計算をやり直す点や、日本語などの非英語言語の精度が低下する点、さらにモバイルやIoT機器への組み込み環境がプラットフォームごとに分断されていて開発が難しい点などが、ライブ音声アプリを構築する際の大きなハードルとなっていました。
これらの課題を解決するために開発されたのが、リアルタイム音声アプリケーション向けのオープンソースAIツールキット「Moonshine Voice」です。すべての処理がデバイス上で完全にローカル実行されるため、アカウント登録やAPIキーが一切不要で、プライバシーを保護しながら機能します。Raspberry PiなどのIoTデバイスまで、環境を問わず同じ使い勝手で実装可能です。
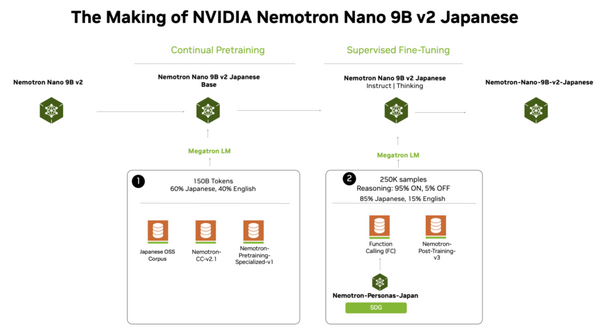
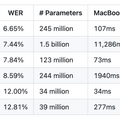
ライブストリーミングに特化したアーキテクチャを採用しており、任意の長さの音声を柔軟に受け入れます。ユーザーが話している最中から並行して文字起こしを進め、計算状態をキャッシュして無駄な処理を省くことで、応答遅延を減らしています。事実、MoonshineのMedium Streamingモデル(2億5000万パラメータ)は、Whisper Large v3(15億パラメータ)よりも圧倒的に少ないパラメータ数でありながら、それを凌駕する精度を達成しています。
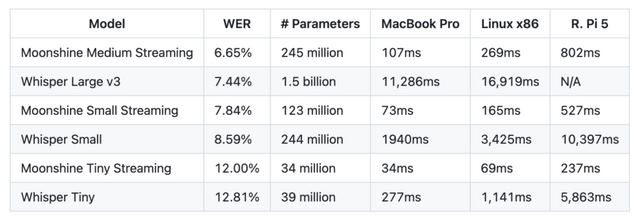
▲Moonshine VoiceとWhisperの各モデルにおける単語エラー率(WER)、パラメータ数、各種デバイスでの処理遅延を比較した表
また、単なる文字起こしにとどまらず、音声アプリ開発にすぐ使える実用的な機能も最初から組み込まれています。誰が話しているかを特定する話者識別機能や、「電気をつけて」といった自然な言葉からコマンドを実行させる認識機能です。
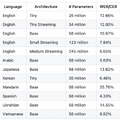
言語サポートについても、英語だけでなく日本語、スペイン語、中国語、韓国語、ベトナム語、ウクライナ語、アラビア語に対応しています。多言語を1つのモデルに詰め込むWhisperとは異なり、Moonshine Voiceは言語ごとに特化した専用モデル(最小モデルは2600万パラメータ。日本語は5800万パラメータ)を用意することで、計算資源の限られたデバイスでも高い精度を維持できるアプローチをとっています。
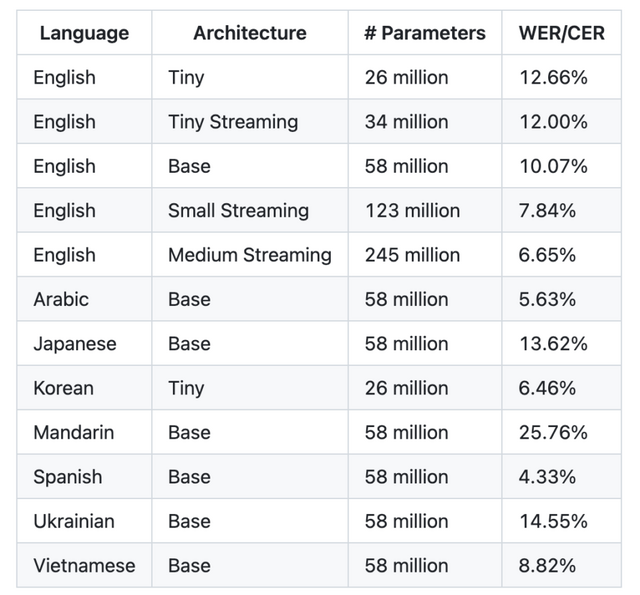
▲Moonshine Voiceが提供する各言語・アーキテクチャ別モデルのパラメータ数と単語/文字エラー率の一覧表
ライセンスの取り扱いには注意が必要で、ソースコード本体と英語モデルは商用利用可能なMITライセンスですが、日本語を含むその他の言語モデルは非商用利用に限られる「Moonshine Community License」での提供となっています。
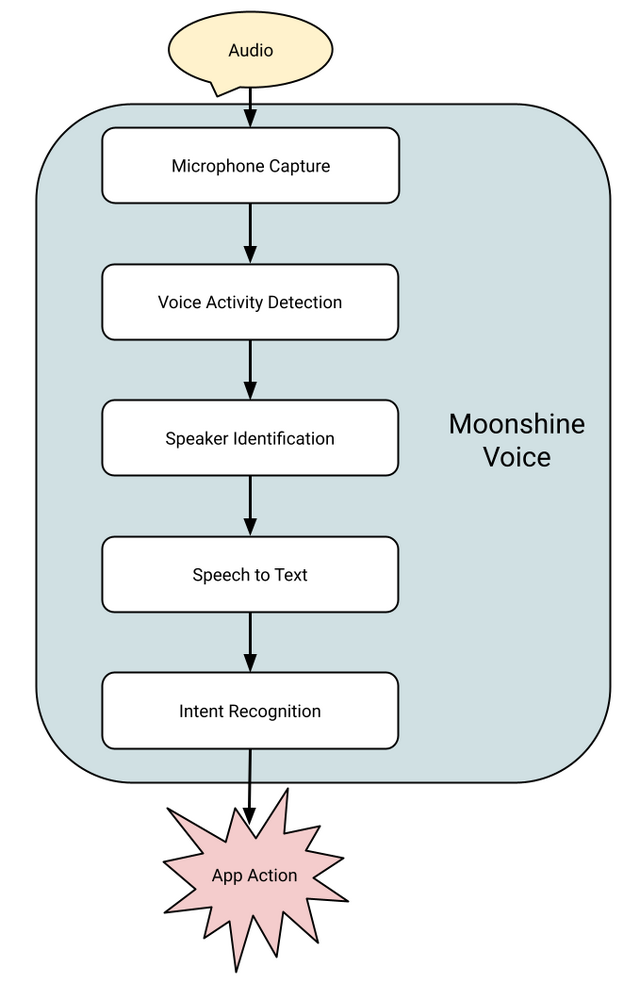
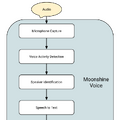
▲Moonshine Voiceのアーキテクチャ図