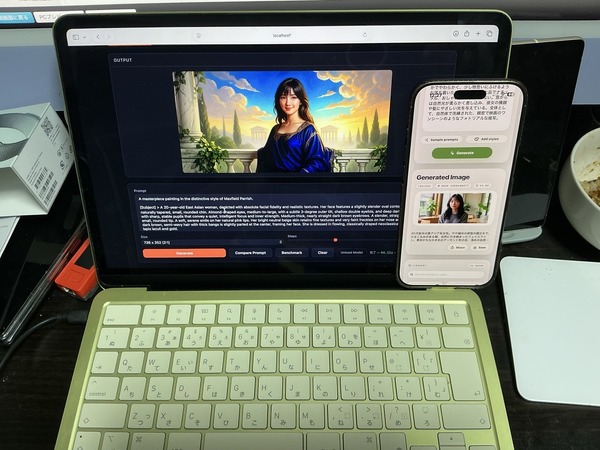
自分だけのためのiPadギターアプリ「FretCaster」を作った次は、iPhoneカメラアプリを開発しました。OpenAI Codexによるヴァイブコーディングで、これも一晩で完成。ほとんど写真を撮らない自分がなぜカメラアプリを作ろうと思ったのか。

先日試してみたBonsai Image Ternary/BinaryはMacBook Neoのような最低限のメモリしか積んでいないマシンでも、ローカルで高解像度の画像生成ができます。
しかし、現時点ではImage to Imageはできません。一方でGemma 4にはVisionモデルがあります。つまり、目の前の画像を読むことはできるけれど、それ自体でローカル画像生成をするわけではありません。
だったら、この2つをつなげたら面白いのではないか。それが今回の出発点でした。
Bonsai Imageを無料で使えるiOSアプリ「Bonsai Studio」がPrismML公式から出ていて、自分でも便利に使っているのですが、これとカメラをつなげてみたい。そう考えたのです。
iPhoneのカメラに映っている世界を、まずマルチモーダル対応のVisionモデルで言葉にします。その言葉を画像生成用のプロンプトとして再構成し、Bonsai Imageで新しい写真として生成する。つまり、カメラ画像を直接変換するのではなく、いったん言葉の層を通して再撮影するような仕組みです。
自分ではこれを、Photograph Abstraction Layerのようなものだと思っています。写真そのものではなく、写真が持っている構図、光、被写体、質感、空気感を言葉に抽象化し、その言葉からもう一度写真を作るわけです。
もう写真を撮らなくなった理由
そもそも最近、ぼくはカメラで写真を撮ることに興味を持てなくなっていました。
かつて自分にとって、写真を撮る最高の対象は妻と子供たちでした。でも、子供たちや孫の写真や動画は、今では「みてね」という家族写真共有SNSで毎日のように大量に送られてきます。自分が撮らなくても、家族の現在は十分すぎるほど届きます。
そして、妻の新しい写真はもう撮れません。生成はできますけどね。
そうなると、iPhoneのカメラを向ける意味がほとんどない。取材用に記録するのには使いますが、そんなに楽しいものじゃない。写真アプリにある画像の大半はAIで生成したものです。
しかし、センサーとして考えるとどうか。目の前の世界をそのまま保存するのではなく、その世界から別の何かを見つけるための装置として使えないでしょうか。
カメラのセンサーを通した先に、普通の写真とは違うものが見えてきたらどうでしょう。異世界カメラ(セカイカメラとかけてます)。今回のアプリは、そういう個人的な感覚からも始まっています。
Visionモデル選びで回り道
Codexに投げた最初のプロンプトはこれ。
当初は、Vision側にはGemma 4を使うつもりでした。Gemma 4はVision対応しているので、カメラフレームを読み取り、その内容をそのままプロンプト化する役割に向いていると考えていました。Google公式のEdge Galleryアプリで動いてますし。
しかし、実機で試してみるとメモリの問題が大きく、安定して動かすのは難しそうでした。iPhone上でBonsai Imageの生成処理も同時に走らせる必要があるため、Visionモデルだけでメモリを使い切ってしまう構成は現実的ではありません。メモリをオフロードする手法もいろいろ試したのですが、どうしてもうまくいきません。
次のWWDCでGeminiベースのFoundation Modelが出たら、もっと楽にできるようになるのでしょうけど。
そこで一度、より軽量なSmolVLMも試しました。こちらは動作は軽いのですが、今回の用途では読み取り性能が少し足りませんでした。特に、画面に映っている人物写真なのか、実際に部屋に人物がいるのか、あるいはマイクやシンセサイザーのような物体が主被写体なのか、といった判別で不安定さがありました。
最終的にはQwen系のVision-Languageモデルを使う方向にしました。Gemma 4という当初の構想どおりではないものの、実機で動かせる範囲のメモリ使用量と、実用できる読み取り精度のバランスがよかったためです。
このあたりは、ローカルAIアプリらしい現実的なトレードオフでした。モデル単体の性能だけで選ぶのではなく、画像生成モデルと同じiPhone上で共存できるか、待ち時間が許容できるか、途中で落ちないか、という条件がかなり重要になります。特に、iPhoneはアプリで使えるメモリ上限がきついのです。
画像生成はモジュラーシンセに似ている
今回、Codexとやり取りしながら実装を進めていくうちに、Diffusionモデルによる画像生成の仕組みも少しずつ見えてきました。
最初はComfyUIのノードを見ても、「なんとなくモジュラーシンセっぽいな」くらいの理解でした。パッチケーブルでつながったモジュールが並んでいて、入力があって、処理があって、最後に音ではなくて画像が出てくる。でも、それぞれのモジュールが何をしているのかはよくわかっていませんでした。
今回の実装で触った要素を、かなり乱暴にシンセサイザーに例えると、プロンプトは演奏するフレーズや譜面に近いものです。「暗い部屋」「縦長のディスプレイ」「画面に映った人物写真」「モアレ」「暖色の光」といった指示が、音楽でいう音高やリズム、演奏ニュアンスになります。
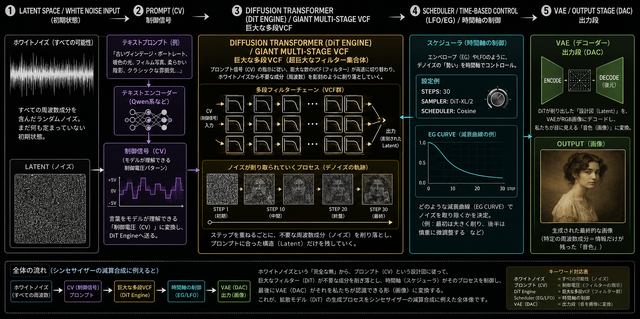
テキストエンコーダーは、その譜面をシンセが理解できる制御信号に変換する部分です。人間が読める文章を、モデルが扱える数値のかたまりに変えます。アナログシンセサイザーであればCV(Control Voltage)信号。今回の場合、Qwen系のテキストモデルを通して、文章が画像生成モデル用の条件情報になります。
Diffusion Transformer(DiT)は、シンセサイザーに例えると、「超巨大で複雑な多段VCF(フィルター)とボコーダーを組み合わせたような音作り回路」そのものです。
初期状態のLatentは、まだ特定の形を持たない「ホワイトノイズ」のようなもの。そこにプロンプトという制御信号(CV:Control Voltage)を流し込むことで、「ここはディスプレイの質感」「ここは背景の闇」といった指示を伝えます。
DiTはこのCV信号を受け取って、膨大な数のフィルター群を高速に切り替えながら、ホワイトノイズから不要な成分(周波数)を彫刻のように削り落としていきます。これこそが、シンセサイザーの「減算合成(Subtractive Synthesis)」の仕組みそのもの。ノイズを「デノイズ」して目的の形を浮き上がらせるDiffusionモデルの原理は、シンセ乗りにとって非常に馴染み深いロジックなのです。
Schedulerは、LFOやエンベロープに近い役割です。ノイズをどのタイミングで、どのくらい取り除いていくかを決めます。急激に変化させるのか、ゆっくり滑らかに変化させるのか。ステップ数を増やすと、音作りでいう調整ポイントが増えるようなものです。ただし、増やせば必ず良くなるわけではなく、処理時間も伸びます。
VAEは、最後の出力段です。Latent空間にある「画像の設計図のようなもの」を、人間が見られるRGB画像にデコードします。シンセでいうと、内部の制御信号や波形を、スピーカーから聞こえる音に変換する最終段に近いです。
今回、VAEの処理が少しでもずれると、画像がタイル状になったり、ノイズのまま崩れたりしました。これは、ローパスフィルターやレゾナンスの設定を少し間違えただけで、音が意図しない発振を始める感じに近いかもしれません(自己発振はそれはそれで楽しいのですが)。
最初はノイズしか出なかった
実装の最初の段階では、生成画像はほとんどノイズでした。青や緑の模様がタイル状に並んでいて、写真どころか被写体の気配もありません。
もっと簡単に行くと思ったのですが、Bonsai ImageはMac用のコードはあっても、iOS向けの情報はほとんどありません。なので、手探りで少しずつ実装していくことになります。
 |  |
 |  |
そこから、テキストエンコーダー、Transformer、Scheduler、VAEを少しずつつないでいきました。テンソルの形が合わない、量子化の扱いが違う、GPUで動かすと落ちる、メモリが足りない、VAEの並べ方が違う。そういう問題をひとつずつ潰していくと、だんだんノイズの中に形が現れるようになりました。
 |  |
 |  |
最終的には、カメラに映ったマイクやシンセサイザー、ディスプレイ上の人物写真などを、別の写真として再構成できるところまで来ました。
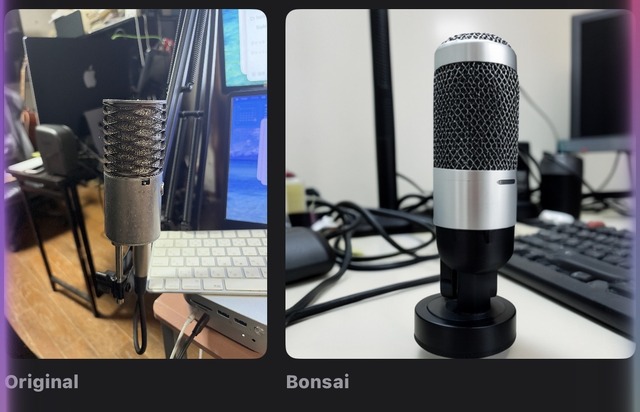
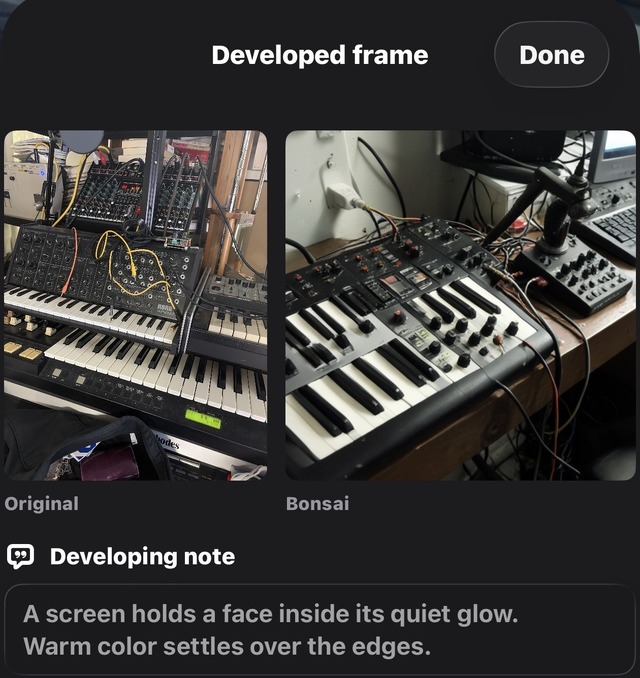
もちろん、これは元画像を忠実にコピーするものではありません。Image to Imageではないので、被写体の形や顔を完全に保持することはできません。むしろ、いったん言葉に変換することで、モデルが解釈した世界が出てきます。そこが面白いところでもあり、難しいところでもあります。
Visionモデルの読み取りが世界を決める
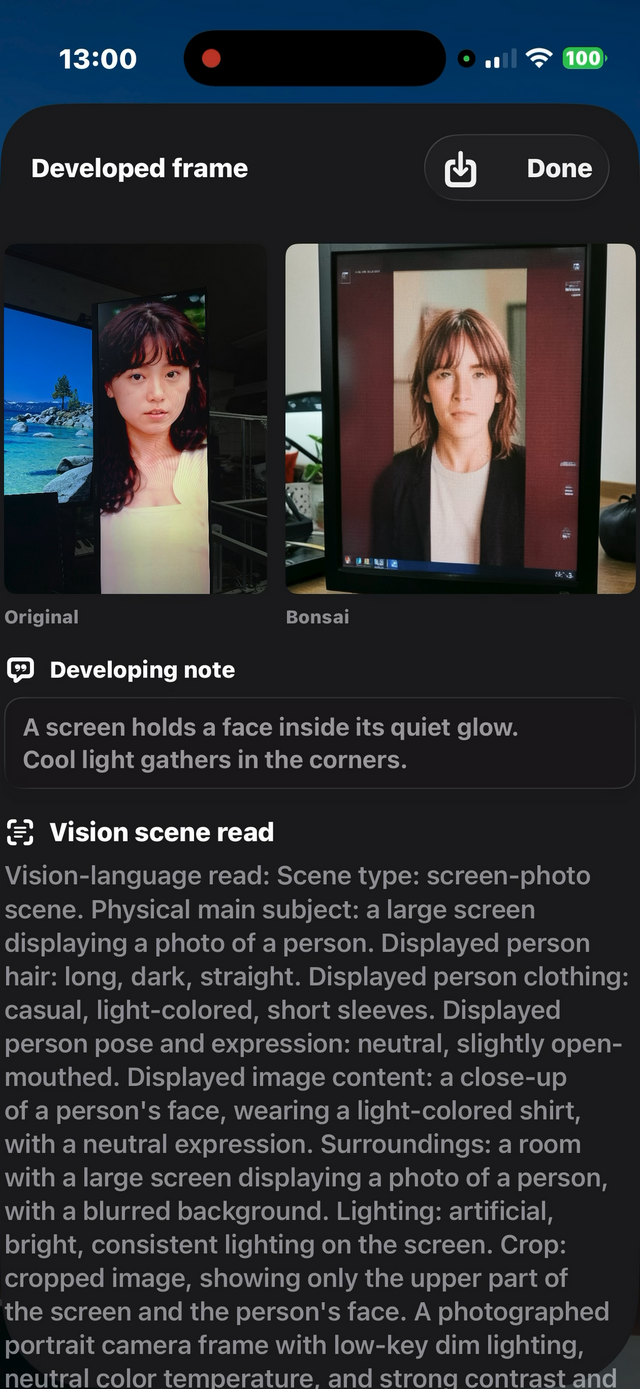
今回のアプリでは、カメラ画像をまずVisionモデルに読ませます。
ここで「これは人が写っている写真だ」と読むのか、「これはディスプレイに表示された人物写真を撮影したものだ」と読むのかで、生成結果は大きく変わります。
たとえば、実際には縦長ディスプレイに表示された人物写真を撮っているのに、Visionモデルが「部屋に人がいる」と解釈すると、生成画像も「部屋に人がいる写真」になってしまいます。

逆に、「物理的な主被写体はディスプレイで、その中に人物写真が表示されている」と読めれば、生成結果もかなり近づきます。

これはプロンプトの問題でもあります。生成モデルは、文章の中にある言葉の重みや曖昧さにかなり影響されます。「older portrait photograph」と書いたら、「古い写真」のつもりでも「年配の人物」と解釈されることがありました。「male-presenting person」と一度入ると、女性的な特徴が見えていても男性寄りに生成されてしまうこともありました。

そこで、プロンプト生成側では「見えている特徴を優先する」「人物の性別を必要以上に断定しない」「古い写真という意味ではvintageやlow-resolution display feelのように表現する」といった調整を入れていきました。
ローカル生成の手触り
このアプリの面白いところは、iPhoneのカメラで見て、iPhoneローカルで読み、iPhoneローカルで生成するところです。クラウドに投げて返ってくる画像生成とは違って、iPhoneの中でかなり重い処理が走ります。
生成中は数秒から十数秒待つことになります。その待ち時間も、ただスピナーを回すだけではつまらないので、Visionモデルが読み取ったキーワードやプロンプト素材が画面に浮遊するようにしました。
 |  |  |
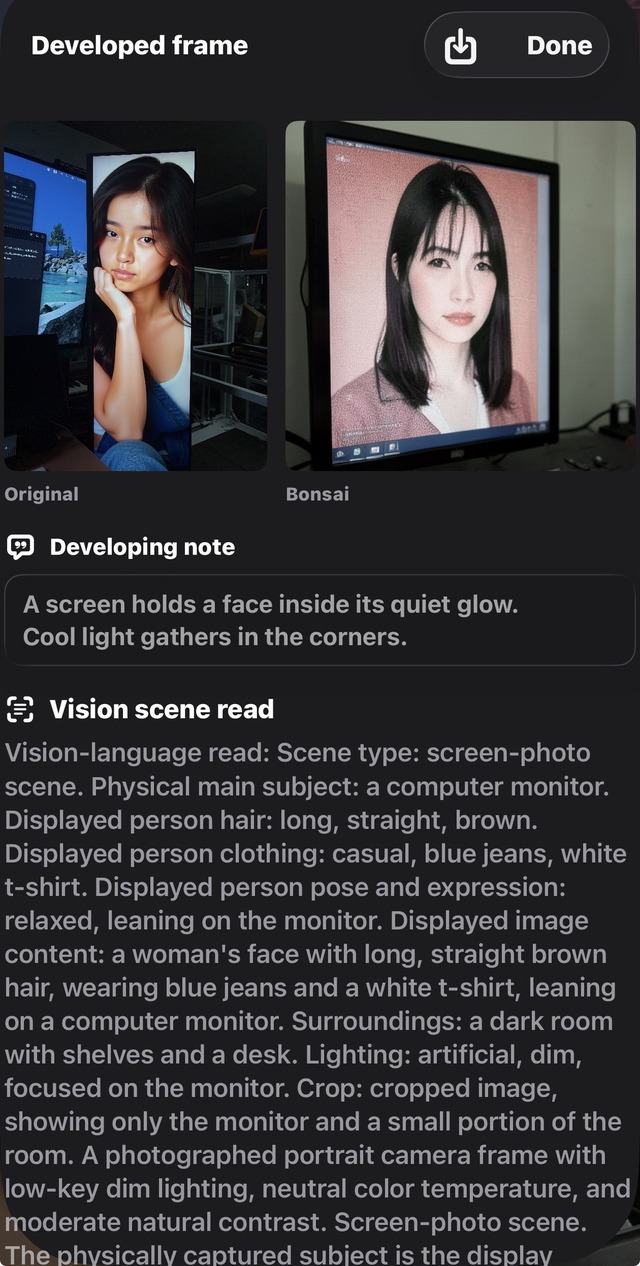
さらに、Visionモデルで得た情報から短い詩のようなDeveloping noteも生成します。たとえば、画面に映った人物写真なら「A screen holds a face inside its quiet glow.」のような一文が出てきます。マイクやシンセサイザーなら、それに応じた言葉が流れます。
画像生成の待ち時間を、現像中の暗室のような体験にしたかったのです。だからDeveloping note(現像メモ)。写真が浮かび上がるまでの間に、モデルが何を見て、どう解釈しているのかが、断片的な言葉として現れる。そこも含めて、このアプリの体験になっています。
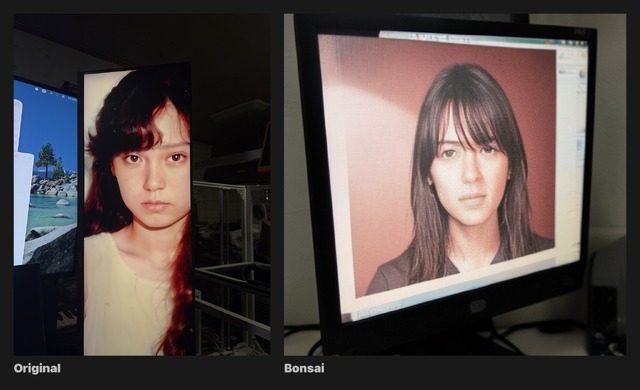
Codexと作ったことで見えたもの
今回のアプリは、Codexにアイデアを投げて、実装し、実機で試し、落ちたら原因を探り、また直す。その繰り返しでした。
その過程で、Diffusionモデルの構造や、VAE、Scheduler、Latent、Tokenizer、Transformerといった言葉が、少しずつ自分の中で実感を持つようになってきました。
本を読んで理解したというより、音が出ないシンセのパッチを一つずつたどっていくような感じです。ここをつなぐと音が出る。ここを間違えると発振する。ここを変えると質感が変わる。そういう身体的な理解に近いものがありました。
AIでアプリを作るというと、プロンプトを投げたら完成するように見えるかもしれません。でも実際には、細かい失敗の積み重ねでした。テンソルの形が違えば落ちるし、メモリが足りなければ止まるし、プロンプトの一語で生成結果が別物になります。
ただ、その試行錯誤をCodexと一緒に進められたことで、自分だけでは踏み込めなかった領域まで入っていけた、そんな気がします。
写真を撮るのではなく、写真を言葉で再演する
このアプリがやっていることは、写真を加工することではありません。写真を一度言葉にして、その言葉からもう一度写真を作ることです。
そこには当然、ズレがあります。完璧な再現ではありません。でも、そのズレが面白い。プロンプトの追加でさらに自分が好きな世界にできる。
カメラが見た世界を、Visionモデルが読み、言葉にし、画像生成モデルが再解釈する。人間が写真を見て記憶し、あとから絵に描くのと少し似ています。正確ではないけれど、どこか本質を拾っていることもある。
Bonsai ImageとQwen系Vision-Languageモデルを組み合わせることで、Image to Imageではない、もうひとつの画像生成カメラができました。
まだ完成形ではありませんが、iPhoneを向けた先の世界が、いったん言葉になり、そこから別の写真として現像されるのは面白い感覚です。
妻の写真を学習してStable Diffusionで生成し始めた頃、プロンプトという量子通信を使って異世界にいる妻を異世界カメラマンに撮ってもらい、その写真を量子もつれでこちらの世界に送ってもらう、そんな空想をしていたのですが、そのブラックボックスの中をちょっとだけ覗けた。そんな気がしています。

じゃあ、外に出てフォトウォークでもしてみるかと家から10メートルのところにある公園で撮影してみたらあら不思議。
緑鮮やかな巨木が、訳のわからないデスクトップのスチールポールになっているではありませんか。
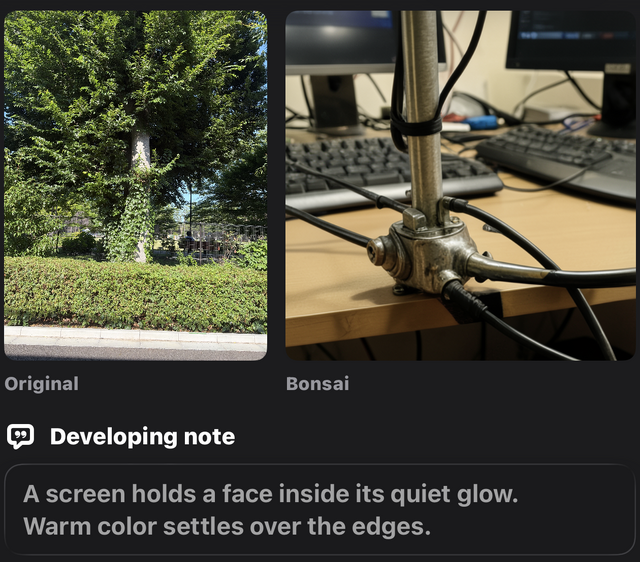
VLMが出したデータを整形するときにあまりにデスクトップ周りに最適化しすぎたせいで、こんなことになったみたい。
てなことも含めて楽しいものです。このバグを潰したついでに、新機能を導入。妻の顔を再現するためのプロンプトを適用することも可能にしたい。
VLMが女性の顔を認識したときに、浮遊しているTorichanボタンをタップすると、プロンプトの顔再現部分が追記されるというもの。
発動のための顔判定条件が厳しかったので、iPhoneをシェイクしてもボタンが流れてくるように改良。これで、フレーム内に表示された女性を、より妻の顔に近づけることが可能になりました。
 |  |
そんな感じで、現実からどんどん離れていく異世界カメラ、何か思いついたらiPhoneのChatGPTアプリのCodexにすぐ相談。iPhone AirをM4 Mac miniにつなげたら実機で試せます。楽しみがひとつ、増えました。
※この記事はCodex、Gemini、Claudeとの対話をもとに生成したテキストを筆者が整理・修正・加筆したものです。