






この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第126回)は、画像1枚を各レイヤーに自動分解するAIモデル「Qwen-Image-Layered」や、音声を分離するMeta開発のAIモデル「SAM Audio」を取り上げます。
また、PDFやQAデータなどのノイズがあるデータを大規模言語モデル(LLM)の訓練用データに自動変換する「DataFlow」や、高品質を維持しながら動画生成AIを100~200倍高速化するフレームワーク「TurboDiffusion」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、主要なLLM同士をポケモンバトルで戦わせた総当たり戦の結果を示した論文を別の単体記事で取り上げています。

LLMの“学習データ作り”を効率化する統合ツール「DataFlow」 PDFやQAデータなどを訓練用の高品質データに自動変換
「DataFlow」は、北京大学などの研究機関が開発したデータ準備・処理のためのオープンソースシステムです。PDF、プレーンテキスト、低品質なQAデータといったノイズの多いソースから高品質なデータを抽出・精製することを目的としています。
DataFlowの特徴は、データ処理を「オペレーター」と呼ばれる部品単位で管理する点にあります。データの生成、品質評価、フィルタリング、修正といった約200種類のオペレーターが用意されており、これらを組み合わせて「パイプライン」を構築します。PyTorchに似た設計を採用しているため、機械学習に慣れた開発者には馴染みやすい作りになっています。
対応する領域は幅広く、テキスト処理、数学的推論、コード生成、Text-to-SQL、エージェント型RAG、知識抽出の6分野をカバーしています。また、DataFlow-Agentという機能を使えば、自然言語で目的を伝えるだけでパイプラインを自動生成することも可能です。
DataFlow: An LLM-Driven Framework for Unified Data Preparation and Workflow Automation in the Era of Data-Centric AI
Hao Liang, Xiaochen Ma, Zhou Liu, Zhen Hao Wong, Zhengyang Zhao, Zimo Meng, Runming He, Chengyu Shen, Qifeng Cai, Zhaoyang Han, Meiyi Qiang, Yalin Feng, Tianyi Bai, Zewei Pan, Ziyi Guo, Yizhen Jiang, Jingwen Deng, Qijie You, Peichao Lai, Tianyu Guo, Chi Hsu Tsai, Hengyi Feng, Rui Hu, Wenkai Yu, Junbo Niu, Bohan Zeng, Ruichuan An, Lu Ma, Jihao Huang, Yaowei Zheng, Conghui He, Linpeng Tang, Bin Cui, Weinan E, Wentao Zhang
Paper | GitHub
高品質を維持しながら動画生成AIを100~200倍高速化するフレームワーク「TurboDiffusion」
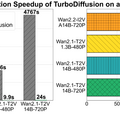
清華大学とUCバークレーの研究チームが、動画生成AIを100~200倍高速化するフレームワーク「TurboDiffusion」を発表しました。
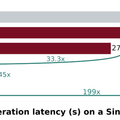
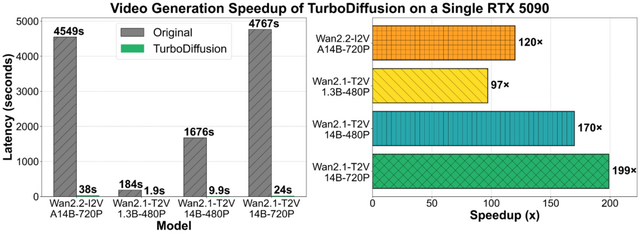
動画生成AIは高品質な映像を作れる一方で、処理に膨大な時間がかかることが課題でした。例えば140億パラメータのモデルで5秒の720p動画を生成するのに約80分かかっていました。TurboDiffusionはこれを24秒にまで短縮します。
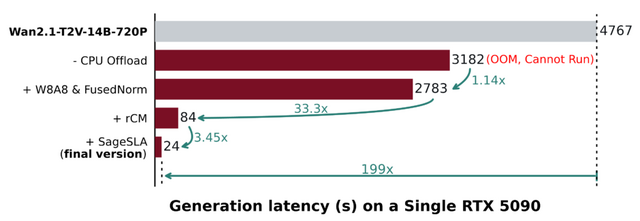
高速化の仕組みは主に4つあります。まず低ビット化した注意機構「SageAttention」で計算を効率化します。次に「Sparse-Linear Attention」(SLA)で不要な計算を省きます。さらにrCMという手法でサンプリングステップを100回から3~4回に削減します。最後にモデルの重みと活性値を8ビットに量子化してメモリ使用量を半減させつつ処理を高速化します。
実験はNVIDIAのGPU「RTX 5090」1枚で行われました。小型の1.3Bモデルでは184秒が1.9秒に、大型の14Bモデルでも4767秒が24秒になり、いずれも動画品質はほぼ維持されています。競合手法のFastVideoと比較しても、TurboDiffusionの方が高速かつ高品質という結果でした。




TurboDiffusion: Accelerating Video Diffusion Models by 100-200 Times
Jintao Zhang, Kaiwen Zheng, Kai Jiang, Haoxu Wang, Ion Stoica, Joseph E. Gonzalez, Jianfei Chen, Jun Zhu
Paper | GitHub
Meta、音声を分離するAIモデル「SAM Audio」を発表
Metaの研究チームが、音声分離のための汎用AIモデル「SAM Audio」を発表しました。これは、拡張版というわけではありませんが、同社の画像セグメンテーションAI「Segment Anything Model」(SAM)の音声版と言えます。
従来の音声分離モデルは、音声専用や音楽専用など特定の領域に限定されていたり、テキストのみでしか指示を受け付けなかったりする制限がありました。
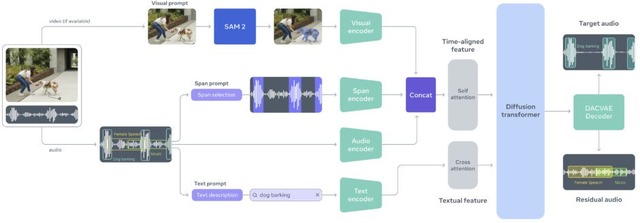
SAM Audioはこれらの課題を解決し、テキスト、映像中の視覚マスク、時間範囲という3種類のプロンプトを単一のモデルで扱えるようにしています。例えば「犬の鳴き声」とテキストで指定したり、動画内の犬をクリックして選択したり、特定の時間帯を指定することで、目的の音だけを抽出できます。
モデルはDiffusion Transformerアーキテクチャを採用し、フローマッチングという手法で訓練されています。音声、音楽、環境音を含む大規模データセットで学習しており、目的の音と残りの音を同時に生成する仕組みです。
評価実験では、一般的な音響分離、音声抽出、話者分離、楽器分離など幅広いタスクで従来の専門モデルや汎用モデルを大幅に上回る性能を達成しました。

SAM Audio: Segment Anything in Audio
Bowen Shi, Andros Tjandra, John Hoffman, Helin Wang, Yi-Chiao Wu, Luya Gao, Julius Richter, Matt Le, Apoorv Vyas, Sanyuan Chen, Christoph Feichtenhofer, Piotr Dollár, Wei-Ning Hsu, Ann Lee
Project | Paper | GitHub
1枚の画像をPhotoshop風レイヤーに複数分解するAI「Qwen-Image-Layered」
Alibabaなどの研究チームが、画像を複数のレイヤーに分解するAIモデル「Qwen-Image-Layered」を発表しました。
従来の画像編集AIには、画像はすべての視覚要素が1枚のキャンバスに融合されているため、一部を編集しようとすると意図しない箇所まで変わってしまう問題がありました。人物の表情を変えたら背景もずれる、物体を移動させたら周囲の色味が変わる、といった問題が頻発していました。
この問題に対し、研究チームはPhotoshopなどのプロ向けツールで使われるレイヤー構造に着目しました。Qwen-Image-Layeredは1枚のRGB画像を入力として受け取り、意味的に分離された複数のRGBAレイヤー(Aは透明度)に自動分解します。各レイヤーは独立して編集可能なため、対象のレイヤーだけを拡大縮小したり、色を変えたり、位置を動かしたりしても他の部分には一切影響しません。
技術的には3つの工夫があります。まずRGBとRGBA両方の画像を統一的に扱えるRGBA-VAEを開発しました。次に可変数のレイヤー分解に対応するVLD-MMDiTアーキテクチャを設計しました。そして事前学習済みの画像生成モデルを段階的にレイヤー分解器へと適応させる多段階学習戦略を採用しました。
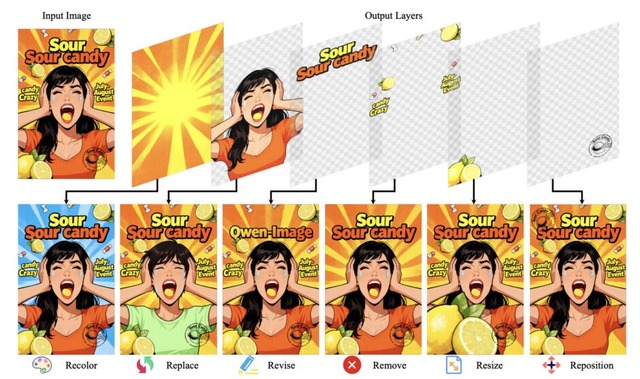

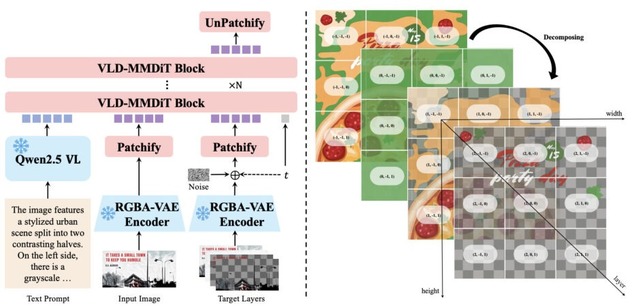
Qwen-Image-Layered: Towards Inherent Editability via Layer Decomposition
Shengming Yin, Zekai Zhang, Zecheng Tang, Kaiyuan Gao, Xiao Xu, Kun Yan, Jiahao Li, Yilei Chen, Yuxiang Chen, Heung-Yeung Shum, Lionel M. Ni, Jingren Zhou, Junyang Lin, Chenfei Wu
Paper | GitHub

















