
この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第123回)は、AIの嘘に表面上は騙されていても、脳波から抽出した神経信号からの判断ではその嘘を見破ることを示した研究や、画像や動画内の人や物を高精度にセグメンテーションするMeta開発モデル「SAM 3」を取り上げます。
また、国際数学オリンピックで金メダルレベルを達成したDeepSeekの新しい数学モデル「DeepSeekMath-V2」と、すべての大規模言語モデル(LLM)が抱える新しい情報を忘れる根本問題の解決アプローチ「Nested Learning」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、AI分野のトップカンファレンス(国際会議)において、査読者や論文著者などの個人情報が漏洩した事件を別の単体記事で取り上げています。
Meta、画像や動画内の人や物をセグメンテーションするAIモデル「SAM 3」発表
Meta AIからプロンプトに基づいて画像や動画内のオブジェクトを検出・セグメンテーション・追跡するモデル「SAM 3」が発表されました。
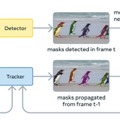
SAM 3は前作SAM 2の後継モデルで、最大の進化は「コンセプトプロンプト」への対応です。従来のSAMシリーズでは点やボックスをクリックして1つの物体を指定する方式でしたが、SAM 3では「黄色いスクールバス」のような短いフレーズや、参照画像を使って、画像や動画内の該当する全てのインスタンスを一度に検出・セグメンテーションできるようになりました。
この新機能を実現するため、研究チームは400万種類の概念ラベルを含む大規模データセットを構築しました。人間のアノテーターとAIアノテーターを組み合わせたデータエンジンを開発し、AIによる検証作業を導入することで、人間だけの場合と比べて2倍以上の効率でデータを収集しました。
モデルのアーキテクチャは、画像レベルの検出器とメモリベースの動画トラッカーで構成されており、両者が単一のバックボーンを共有しています。特に「Presence Token」という仕組みを導入し、物体の認識と位置特定を分離することで、検出精度を向上させています。
評価実験では、既存システムと比較して画像・動画の概念セグメンテーション精度が2倍に向上したと報告されています。

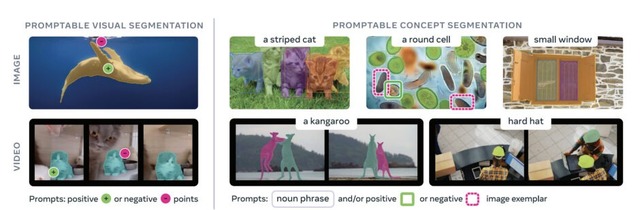

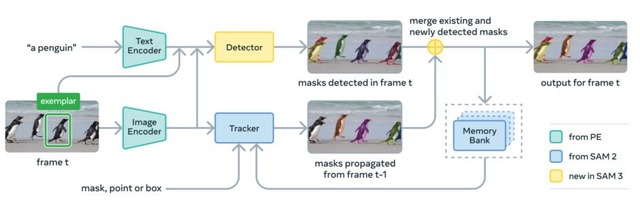

SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Liliane Momeni, Rishi Hazra, Shuangrui Ding, Sagar Vaze, Francois Porcher, Feng Li, Siyuan Li, Aishwarya Kamath, Ho Kei Cheng, Piotr Dollár, Nikhila Ravi, Kate Saenko, Pengchuan Zhang, Christoph Feichtenhofer
Project | Paper | GitHub
AIに騙されても“脳は騙されない”。見破れないAIの嘘は「脳波から抽出した神経信号」が見破る
人間とAIがチームを組んで意思決定を行う際、AIが誤った情報を提供すると人間のチーム全体が壊滅的な失敗に陥ります。しかし、脳波を使ったインタフェース(BCI)がこの問題を解決できるかもしれません。
実験ではVR空間でドローン監視タスクを行い、参加者は画面に映る物体がターゲットかどうかを判断しました。AIアシスタントが色付きの照準でターゲットを教えるのですが、意図的に間違った情報を与える条件が設けられました。
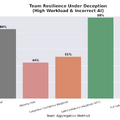
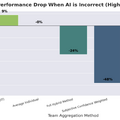
AIが嘘をつくと、多数決で決める従来型のチームは正答率が44%まで落ち込みました。チームが大きくなるほど全員が同じ誤りに引きずられ、集合知が逆に働いていました。ところが、参加者の脳波から抽出した神経信号だけを使って判断を決定するチームは、同じ条件下でも98%という正答率を維持しました。
なぜこのようなことが起きるのかを分析した結果、AIに騙された状態では人間の主観的な自信と実際の正解との相関が非常に弱くなっていました。つまり、自信はあるけど間違っているという状態に陥っていたのです。一方で脳波から読み取れる信号は、意識的な判断が歪められる前の段階で生成されるため、外部からの偽情報に汚染されにくいことがわかりました。
興味深いのは、脳波を読み取るシステムが状況に応じて戦略を切り替えていた点です。負荷の低い単純な状況では、脳が自動操縦モードで脳がスムーズに処理しているときの安定リズムを正解のサインと見なしていました。しかしAIに騙されるリスクのある高負荷状況では、「脳が懸命に考えている」を正解の手がかりとして使うように適応していました。
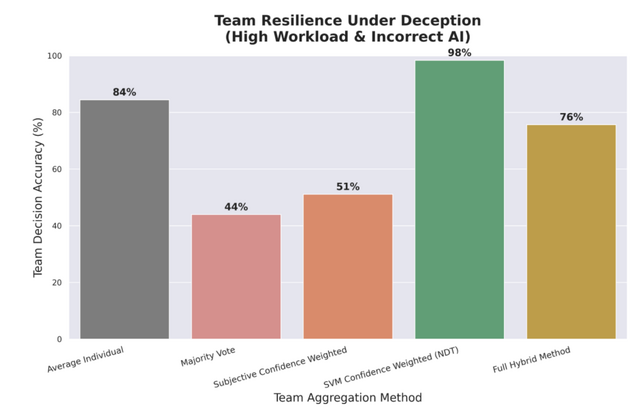
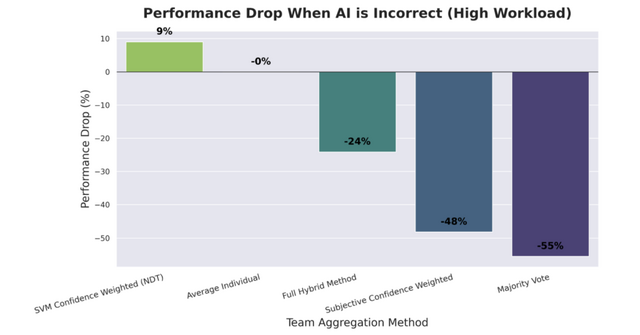
Human-AI Teaming Under Deception: An Implicit BCI Safeguards Drone Team Performance in Virtual Reality
Christopher Baker, Stephen Hinton, Akashdeep Nijjar, Riccardo Poli, Caterina Cinel, Tom Reed, Stephen Fairclough
Paper
Google、全LLMが抱える未解決問題「デジタル健忘症」を解決か
「Nested Learning」と名付けられたこのアプローチは、現在のすべての大規模言語モデル(LLM)が抱える根本的な問題に取り組みます。
LLMは一度学習を終えると基本的に新しい情報を与えても、それを長期的に覚えておくことができません。研究チームはこの状態を、新しい記憶を作れなくなる「前向性健忘」という症状に例えています。モデルは今見ているテキストか、学習時に覚えた古い知識しか使えないのです。
人間の脳が継続的に学習できる理由の一つは、脳の各部位が異なる時間スケールで情報を処理・更新している点にあります。ある部位は瞬時に反応し、別の部位はゆっくりと知識を定着させます。Nested Learningは、機械学習モデルとその訓練プロセス全体を、このような異なる更新頻度を持つ最適化プロセスの入れ子構造として捉え直すことにあります。
研究チームは、AIの学習プロセスをよく観察すると、実は似たような多層構造が隠れていることを発見した。例えば、AdamやSGDモメンタムといった学習アルゴリズムも、過去の情報を記憶する仕組みとして機能していることがわかりました。
研究チームはこれにヒントを得て、更新頻度の異なる複数の記憶層を持つ「HOPE」というモデルを開発しました。これにより、情報の重要度や時間的性質に応じて柔軟に記憶を管理できます。評価実験では、言語理解や常識推論のタスクで既存手法を上回る成績を収めています。
この研究は、機械学習分野のトップカンファレンス「NeurIPS 2025」に採択されています。

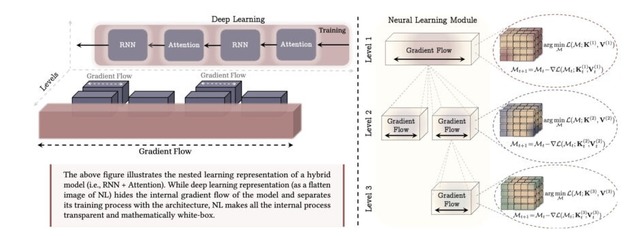
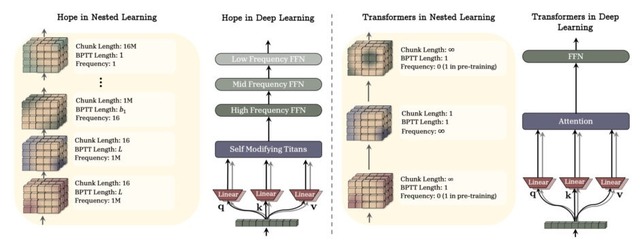
Nested Learning: The Illusion of Deep Learning Architectures
Ali Behrouz, Meisam Razaviyayn, Peiling Zhong, Vahab Mirrokni
Paper
DeepSeekの新数学モデル「DeepSeekMath-V2」が国際数学オリンピックで金メダルレベルを達成
「DeepSeekMath-V2」は、DeepSeek AIチームが新しく開発した数学推論モデルです。
従来の数学AIには、正しい答えを出しても、その推論過程が正しいとは限らない問題がありました。間違った論理で偶然正解にたどり着くこともありますし、定理証明のように答えではなく証明過程そのものが求められる問題には対応できませんでした。
DeepSeekMath-V2はこの問題を「自己検証」という仕組みで解決しています。証明を生成するモデルと、その証明をチェックする検証モデルの2つが協力して動作します。まず生成モデルが証明を作り、検証モデルがその論理的厳密性を評価します。問題があれば生成モデルが修正し、検証を通過するまでこのサイクルを繰り返します。
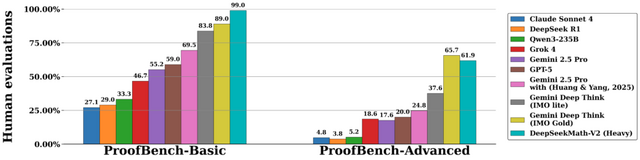
性能面では、IMO 2025とCMO 2024で金メダルレベルのスコアを達成し、Putnam 2024では120点中118点を獲得しました。Google DeepMindのDeepThinkモデルをIMO-ProofBenchベンチマークで上回る結果も出ています。