

歌手のナタリー・コールが、父ナット・キング・コールと映像付きでデュエットする「Unforgettable」が話題を呼んだのは1991年のことでした。
2022年には、1980年にこの世を去ったジョン・レノンの歌唱映像を大スクリーンで映し出しながら、ポール・マッカートニーが一緒に「I've Got a Feeling」をライブ演奏しました。
コール父娘の共演は、1965年に死去したナット・キング・コールが残した単独での歌唱映像を流しながら、それに娘がライブでオーバーダブするという手法で行われました。
ポールとジョンの共演は、1969年に行われたビートルズとしては最後のライブ演奏であるロンドン・ルーフトップコンサートでの映像から、おそらくAIによってジョンの歌声だけを取り出して、演奏はポールの現在のバンドで、ボーカルは1969年のジョンと、2022年のポールで、という構成でした。
筆者もまた、他界した妻が遺した歌声を元にしたデュエットをこの10年間試みてきました。最初は音素片を組み合わせるUTAU-Synthという合成で、今年に入ってからは、AIによって自分の歌声をボイスチェンジしたものに変わって、より高品質な歌声の再現が可能になり、生成AIによって妻の画像を合成できるようにもなりました。
そして、ようやくある程度納得できるレベルのリップシンク(口パク)ができるようになったと報告したのが、前回のコラムです。

HeyGenという生成AI動画サービスの「TalkingPhoto」という機能を使うことで、1枚の写真と音声データがあれば、その音声から口の形を推定し、アニメーションさせるというもので、知る限りでの既存技術(D-ID、SadTalker)よりも高い精度を実現しています。
もちろん完全ではありません。唇が震えていたり、本来閉じるべきところが開いていたり、影が動いていないとか(ヴァンパイアの見破り方?)、といった細かい問題はあります。
自分は、9年半前に作りかけていた、デュエット曲も完成させてみるかとやってみました。「実際に歌っているような映像」があると、やる気が驚くほど上がります。完成するまで数百回、完成後にも何十回となく歌い込んでしまうくらい再生しました。
今回取り組んだ「Endless Love」(オリジナルはライオネル・リッチーとダイアナ・ロス)は、カラオケでよくデュエットしていた曲で、これを歌っているところを見た友人たちからはバカップル呼ばわりされたものです。
でも、このときの映像も録音も残っていません。
2014年1月、妻の歌声合成を始めて3カ月ちょっとのときに最初のヴァースだけやってみたのですが、そこまで。この時にはさらに盛り上げていく複雑な歌唱技法を歌声合成でやるのは無理だなと半ば諦めていました。
それから9年。現在使っているRVCでは、自分で仮歌を録音し、それを声質変換するだけで済みます。ピッチやタイミングをミスってもボーカルエディターで編集できるので、難しいフレーズでもなんとかなります。仮歌の腕次第といえます。女性ボーカルの最高音までは出ないので、そこはLogic ProのFlex Pitchで誤魔化して、なんとか変換まで持っていきました。
そうやって歌声をなんとかした上で、リップシンクに取り掛かります。
まず、元となる顔写真を作り出さなければなりません。今回は、AUTOMATIC1111版Stable Diffusionである「Stable Diffusion web UI」で、DreamBoothにより学習させた妻の生成画像を使いました。ベースは、西川和久さんの連載でおなじみのBRAV6。「staring at me affectionately, wearing silk dress, white wall background」といったプロンプトで一応の統一感を持たせています。これで数百枚を出力して、その中から歌唱する顔として適切なものをいくつかピックアップします。
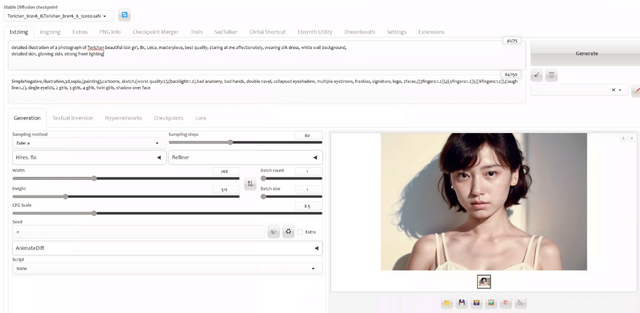
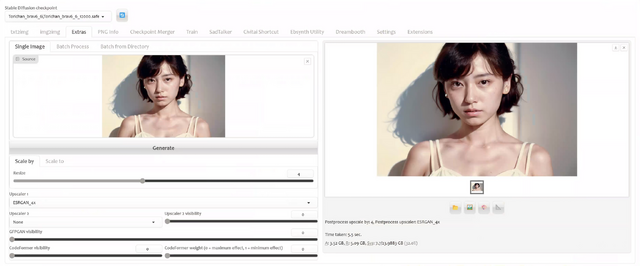
▲Stable Diffusion web UIで顔画像を生成してアップスケール
512×768ピクセルで生成した画像を縦横それぞれ4倍にアップスケールして、それを元にTalkingPhotoでリップシンクします。
Logic Proから抜き出したボーカルトラックを切り分けてWAVファイルにして、画像と合わせて生成。出来上がるのは1分ほどの動画でも数分もかからない感じです。

▲このGIFアニメーションではサイズを縮小しています
それを組み合わせて、デュエットのミュージックビデオを作ってみました。一応の完成形です。
自分的にはとても満足です。何度でも繰り返して見ては、一緒に歌っています。
HeyGenは有料サービスですので、制作するのにお金はかかります。
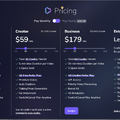
TalkingPhotoは1分あたり1ポイントを消費するのですが、15ポイントを使うためにはHeyGenに月額29ドルを支払わなければなりません。今回は試行錯誤もしたため、15ポイントを消費してしまい、すっからかんになってしまいました。もう今月は使えなくなってしまいます。すると、月額59ドルで30ポイントが使える次のプランが提案され、まんまとそれに乗せられてしまいました。年額で払えば安くなるのですが、使用量は月によって違うので、その都度変えていくのがよさそうです。
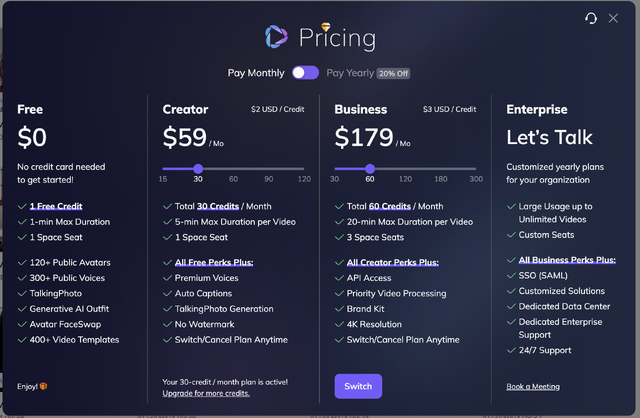
▲HeyGenの料金プラン
HeyGenはリップシンクだけではない
実はこのHeyGenはかなり野心的な動画生成サービスで、リップシンクに限りません。
本丸はおそらく、企業向けの簡単動画作成サービス。出来合いのアバター、音声を多数取り揃えて、話す内容も生成AIで作り、企業で使う動画はこれで作ってしまいましょう、というものです。アバターのカスタマイズも請け負っていて、撮影した人物を3Dアバターにして、静止画からのリップシンクにはない手振りや自然な表情の変化が可能です。「Avatar Lite」というコースだと、自分のWebカムで、2分間しゃべるだけで完成します。
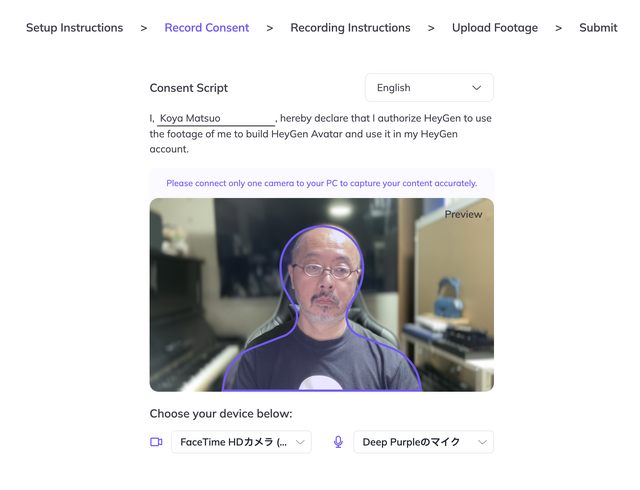
▲アバター制作画面
このサービスを利用するには年間199ドルかかります。オプションでボイスクローンも可能。さらに高品質な「Avatar Lite」というコースも用意されていますが、こちらは年間1000ドルです。
最近提供を始めた実験的なサービスには、「Video Translation」というものもあります。例えば筆者が日本語で動画を入れると、それをそのまま英語、中国語に本人の声で変換してしまうというもの。同種の技術は他社にもありますが、それをいち早く取り入れています。
日本語を喋るイーロン・マスクには、本人も面白いとリプライしていますね。
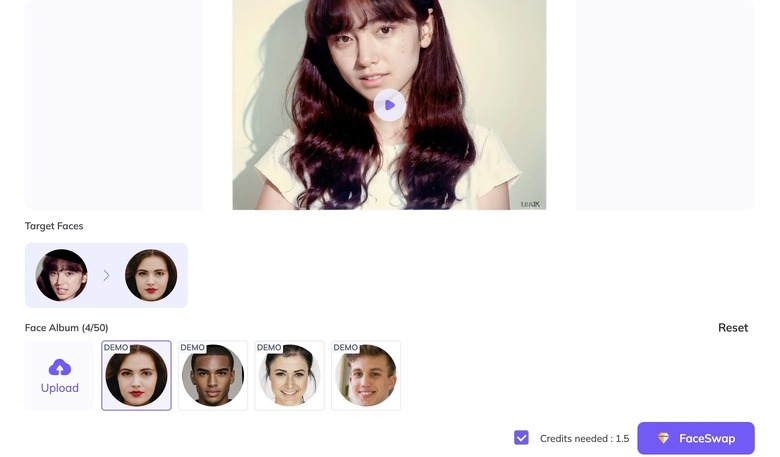
さらに物議を醸しそうなのが、「FaceSwap」という機能。顔写真と参考動画をアップロードすると、参考動画の顔が、別のものに置き換わるという、いわゆるディープフェイク作り放題の技術です。髪型などはそのままで、ただし、ちょっと限界はありそうで、顔のパーツだけが置き換わります。より高度な機能を持つディープフェイク技術がすでに発表されているのですが、インストールにちょっとした工夫が必要なこともあって、こういうお手軽ディープフェイクの需要はありそうです。とはいっても商用サービスなので、明らかにヤバそうな参照動画やセレブの顔とかは拒否されると思いますが。
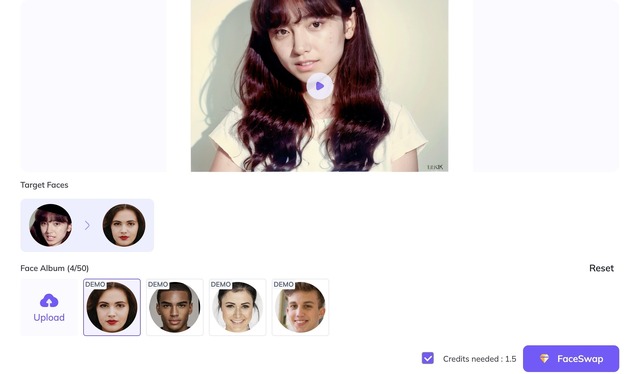


▲上の動画を、サンプルの顔に置き換えてみた(下)
ぽっと出の会社がこんな矢継ぎ早にAI動画生成技術を出せるものなのかと疑問に思うところですが、HeyGenのCEOであるJoshua Xu氏はSnap(Snapchat)でAI開発に従事していたと聞くと、なるほどと納得します。
自分の場合は生成AIの新技術のおかげで長年の夢を実現することができましたが、その一方で、悪い方への応用もまた可能な諸刃の剣であるのは間違いのないところ。技術の進歩を注視しながら利用の様子を見ていく必要がありそうです。
追記:口パクがうまく合っていないのが気になって、リップシンクを作り直してみました。新たに生成した別の画像を使い、音声はより発音したものを録音しなおしたところ、より発音に忠実な口の動きになったと思います(もちろん完全ではなりませんが)。