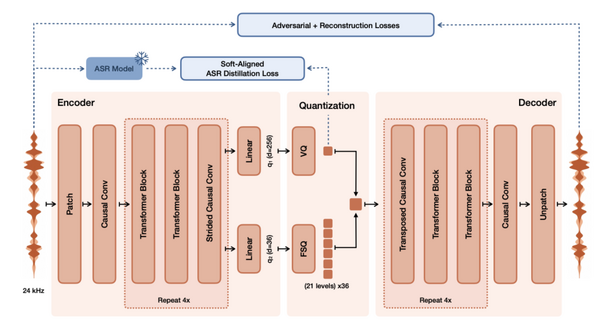





この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第138回)は、動画・音声・テキストを見ているときの脳反応を予測できるMeta開発の脳活動推測AI「TRIBE v2」や、人間には簡単でもAIには難しい新しいテスト「ARC-AGI-3」を取り上げます。
また、LTX-2.3越えの商用利用可能な日本語対応ローカル音声・動画生成AI「daVinci-MagiHuman」や、“自己改善の仕方”も自己改善するメタ認知型自己修正AI「HyperAgents」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、わずか3秒の参照音声から、自然で表現力豊かな音声を生成できる多言語対応の音声合成(TTS)モデル「Voxtral TTS」を別の単体記事で取り上げています。
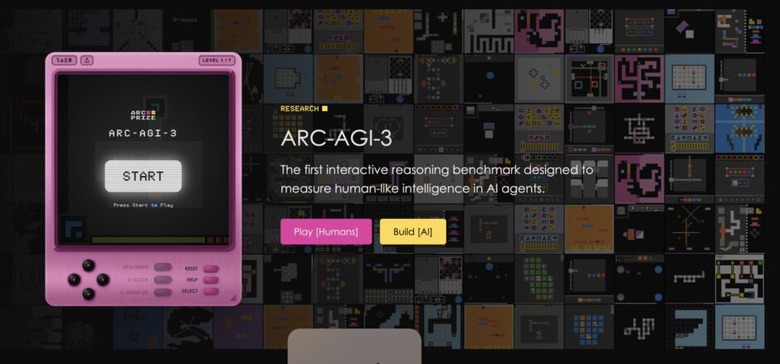
人間100% vs. AI 1%未満のスコア差——結果ではなく効率を見る新ベンチマーク「ARC-AGI-3」
ARC Prize Foundationは、汎用人工知能(AGI)の評価を目的とした新しいベンチマーク「ARC-AGI-3」を発表しました。
前身のARC-AGI-1と2は、少数の入出力例からパターンを推論する静的なグリッド課題でしたが、ARC-AGI-3はターン制のインタラクティブな環境へと大きく舵を切りました。エージェントは64×64のグリッド上で、目的も操作説明も一切与えられず、環境や仕組みを理解し、勝利条件を自力で推測して達成しなければなりません。
評価指標として導入されたのがRHAE(Relative Human Action Efficiency)です。単にクリアできるかではなく、どれだけ少ない手順でクリアできるかを測る仕組みです。
具体的には、AIがクリアするのに要したアクション数を、人間の基準値(10人中2番目に優秀な成績)と比較し、その比率を二乗してスコア化します。つまり人間の10倍のアクションを要した場合、得点は1%にしかなりません。
人間(486人)がARC-AGI-3を試した結果、解決率は100%でした。ところが最先端のAIはほぼ全滅で、Google、OpenAI、Anthropic、xAIの各社モデルがいずれもスコア1%未満という結果になりました。



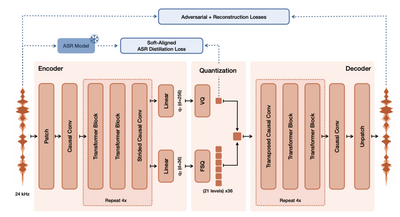
LTX 2.3越えのローカル音声・動画生成AI「daVinci-MagiHuman」が商用利用可能で無料公開。日本語にも対応
上海を拠点とするAI研究機関「SII-GAIR」と北京発のAIスタートアップ「Sand.ai」が共同で開発した「daVinci-MagiHuman」は、テキスト、動画、音声を統合して生成できる新しいオープンソースAIモデルです。
特徴は、150億パラメータと40層からなる単一ストリームのTransformerアーキテクチャを採用している点です。従来の複雑なクロスアテンションを排除し、セルフアテンションのみでテキスト、動画、音声を統合的に処理することで、簡略化と計算の効率化を実現しています。
このシンプルな構造により、生成速度は向上しており、単一のH100 GPUを使用した場合、5秒間の256p動画を2秒で生成でき、1080pの高解像度動画で38秒で出力が可能です。
特に人物の描写に優れており、豊かな顔の表情や、音声と自然に連動した話し方、リアルな体の動き、正確なリップシンクを実現しています。対応言語は、日本語をはじめ、中国語(普通話・広東語)、英語、韓国語、ドイツ語、フランス語の多言語をサポートしています。
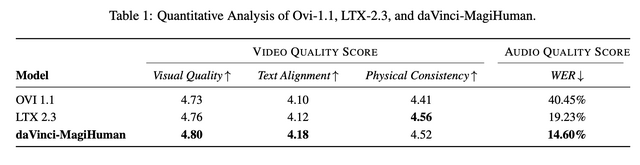
人間による比較評価(2000件)では、Ovi 1.1に対して80.0%、LTX 2.3に対して60.9%の勝率を達成しました。また自動評価では、視覚品質とテキスト整合性で最高を達成し、単語誤り率も14.60%と最も低い値を記録しました。
ベースモデルから蒸留モデル、超解像モデル、推論コードに至るまですべてのモデルスタックが商用利用可能でオープンソースとして公開されています。

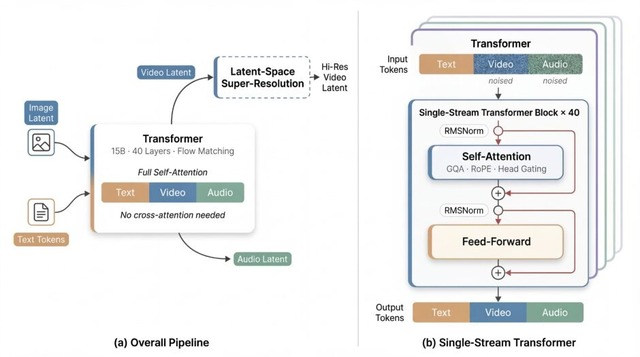
Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
SII-GAIR, Sand.ai
Paper | GitHub
動画・音声・テキストを見ているときの脳反応を予測できる脳活動推測AI「TRIBE v2」をMetaなどが発表
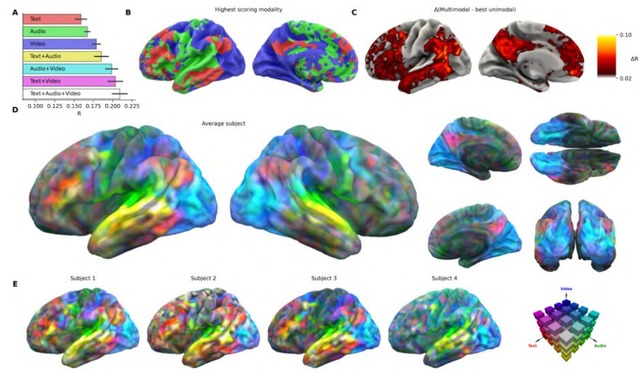
Metaなどが、人間の脳活動を予測する基盤モデル「TRIBE v2」を発表しました。映像・音声・言語の3つの入力を統合し、脳全体の反応を高精度に予測できるもので、720人分・計1000時間以上のfMRIデータで訓練されています。
従来の脳科学では、顔認識や言語処理といった個別の機能ごとに対応する脳部位を調べるのが主流でした。しかし日常の知覚は複数の感覚が同時に働いています。
TRIBE v2は映像・音声・テキストそれぞれに最先端のAIモデルを適用して特徴量を抽出し、Transformerで統合することで、こうした複合的な脳反応をまとめて予測します。
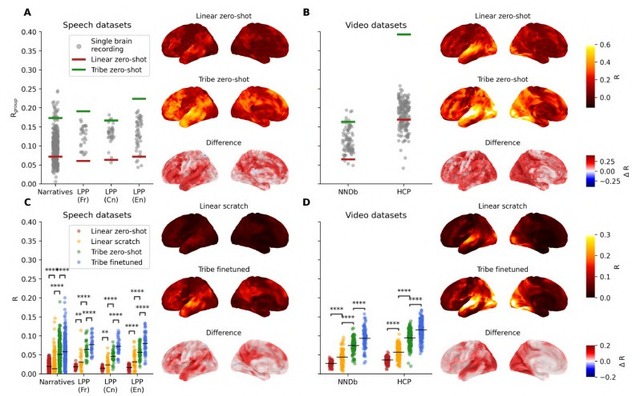
精度は従来の線形モデルを上回り、国際コンペAlgonauts 2025で263チーム中1位を獲得しました。未知のユーザーに対してもゼロショットで予測可能です。
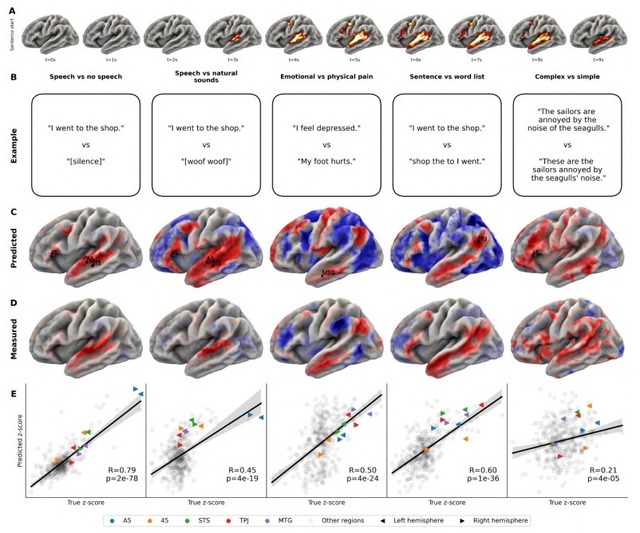
脳実験のコンピュータ上での再現は、顔・場所・身体・文字の画像提示実験をモデル上で試したところ、紡錘状顔領域(顔を見たときに反応するとされる部位)や海馬傍回場所領域(場所に反応するとされている部位)の反応など、数十年の研究で確立されてきた知見が正しく再現されました。
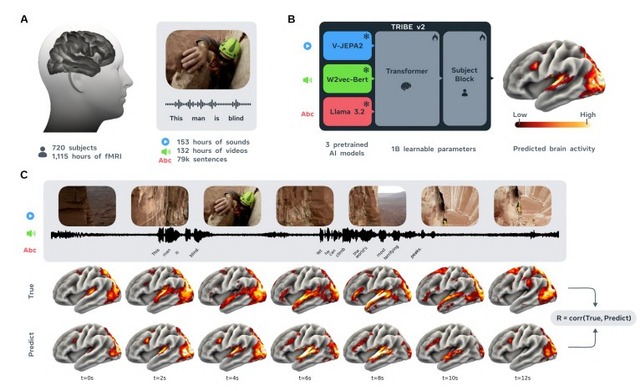
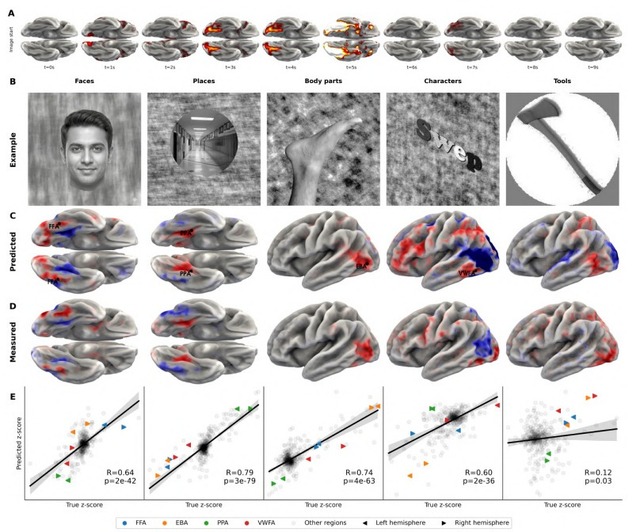
A foundation model of vision, audition, and language for in-silico neuroscience
Stéphane d’Ascoli, Jérémy Rapin, Yohann Benchetrit, Teon Brookes, Katelyn Begany, Joséphine Raugel, Hubert Banville, Jean-Rémi King
Paper | GitHub | Blog
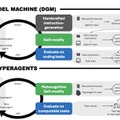
“自己改善の仕方”も自己改善するAI「HyperAgents」。Metaなどが汎用的なメタ認知型自己修正フレームワークを発表
ブリティッシュコロンビア大学やMetaなどの研究チームが「HyperAgents」という自己改善型AIの新しいフレームワークを発表しました。
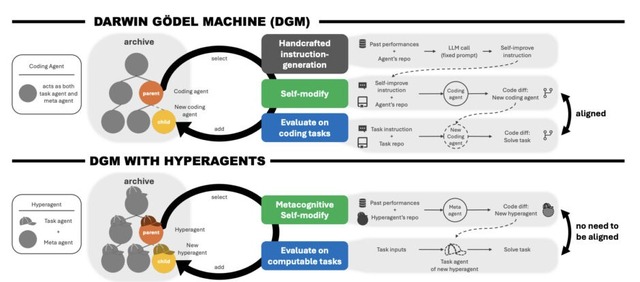
従来の自己改善型AI、例えばDarwin Gödel Machine(DGM)では、AIが自分のコードを書き換えて性能を上げていけますが、どう改善するかを決める上位の仕組みは人間が設計した固定のものでした。
コーディングの場合はタスクを解く能力と自己改善の能力が同じスキルなので問題になりませんが、論文査読やロボット制御のような別の領域ではこの前提が成り立たず、うまく機能しません。
HyperAgentsはこの問題を、タスクを解く部分(タスクエージェント)と改善方法を考える部分(メタエージェント)を一つの編集可能なプログラムに統合することで解決しました。改善を生み出す仕組み自体が改善の対象になる、メタ認知的自己修正が可能になります。
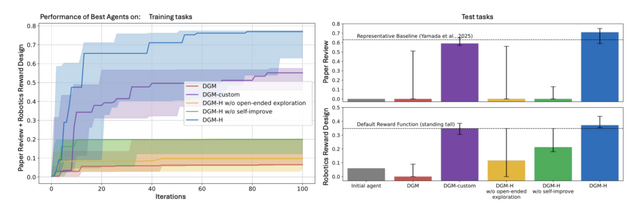
実験ではコーディング、論文査読、ロボットの報酬関数設計、数学オリンピックの採点という4分野で検証しました。従来の自己改善型AIはコーディング以外では領域固有のカスタマイズなしにあまり機能しませんでしたが、HyperAgentsはどの分野でも着実に性能を伸ばしています。
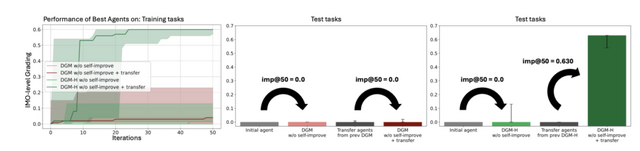
特に、メタレベルの改善がドメインを超えて転移しており、論文査読とロボット制御で鍛えたハイパーエージェントを未経験の数学採点タスクに転用したところ、初期エージェントでは不可能だった改善を生み出しました。
Hyperagents
Jenny Zhang, Bingchen Zhao, Wannan Yang, Jakob Foerster, Jeff Clune, Minqi Jiang, Sam Devlin, Tatiana Shavrina
Paper | GitHub