
生成AIグラビアをグラビアカメラマンが作るとどうなる? 連載記事一覧
ここのところ新しい画像生成モデルのリリースもなく……
3月に入ってLTX-2.3やSeedance 2.0など動画系は活発だが、画像系はオープンで特に目新しいのはなし。筆者の画像生成は、
Z-Image-Base → Z-Image-Fun-Lora-Distill-8-Steps-2602_UDCAI_ComfyUI(0.6)
のパターンが完全に定着している。
もちろんZ-Image-Baseがベストなのだが、Steps数も多く、CFGを1より大きくする関係でZ-Image-Turboより4倍以上の時間がかかる。といってZ-Image-Turboだと奥行き感がなく薄っぺらい絵になりそれは避けたい……のちょうど間をとった形で、CFG=1、Steps 8~10と、生成速度もZ-Image-Turboと同じに。
ただ過去のプロンプトでどうなるか? グラビアっぽいのを出したら? 顔LoRAを学習し当てた結果は? といった一通りのことはとっくに確認済み。では何を出すのか? 記事ネタ以外で思い付かなかったりする(笑)。
そこで意外性のある出力を求め実験したのが、前回ご紹介したLLMを使ってプロンプト拡張する方法。

ただしこれは、”ユーザーが入力した簡単なプロンプトからiPhoneで撮ったような日常スナップ写真”というだけで、被写体の個性などは含まれていない。
つまり指定するキーワードでファッションや場所、季節などは指定できるが、それをiPhoneで撮ったような……になるだけ。イマイチ意外性に欠ける。
AITuberのペルソナデータを使う
そうこうしてる先日、DataPilot/AItuber-Personas-Japan、 AITuberのペルソナデータ 195件がHugging Faceで公開された。各キャラクターのデータとして、
concept: キャラクターコンセプト設計書
system_prompt: LLM用システムプロンプト。キャラクターの話し方・性格・配信スタイル
thema: キャラクターのテーマ・配信ジャンル
などが含まれている。
話は少し戻るが、ひと月ほど前にXでAIアイドルのペルソナデータを作り、それをNano Banana(だったかな?)に入れ、キーワードを追加すると、その性格に基づいてさまざまなシーンを生成できるプロンプトを作っていたアカウントを見かけた。
面白そうだな、と思ったものの、ペルソナデータ自体を作るのが面倒(笑)で、忘れていたところAIアイドルではなく、AITuber 195人分ものペルソナデータが公開されたというわけだ。
これをベースにキーワードからLLMを使いプロンプト拡張すれば、195人分、Seedガチャとまた違う意外性を持ちつつ、そのキャラクタの個性に合わせた画像を生成することが可能となる。
大まかな流れは以下の通り、
1. キャラクター情報を取得(0から194の番号指定)
- concept フィールドからビジュアル情報(髪型・服装・色など)を抽出
- system_prompt フィールドからキャラクター定義部分を抽出2. 性別・眼鏡を判定
- テキストを解析して性別を自動判定 → プロンプト冒頭の主語を決定
- 眼鏡の記載があれば glasses としてメモ3. LLMへの指示を組み立て
- システムプロンプト:「英語のみ・160語以内・髪型必須・眼鏡は明記時のみ」などのルールと出力例2件
- ユーザーメッセージ:キャラクター定義 + ユーザーが入力したキーワード4. LLMが生成
- OpenAI互換APIに送信
- LLMがキャラクター情報とキーワードを組み合わせて英語プロンプトを生成
これなら例えばキーワードに”春、お花見”と入れ、キャラクタ番号を指定すれば、その性格に基づき、ルックスや背景など自動的にプロンプトへ反映可能なのがお分かりいただけるだろうか?
ComfyUI_AITuberカスタムノード
と言うことで自作(笑)して公開したのがComfyUI_AITuberとなる。やってることは上記の通りだが、ComfyUIのカスタムノードは、修正したらComfyUIをリスタートしないとその結果が反映されずちょっと面倒。なので、全く同じロジックのCLI版も一緒に入っている。
これを使えば、ComfyUIに組み込まなくてもCLIでプロンプトを生成し、それをZ-Image-BaseのPromptへコピペ……という運用方法も可能に。CLI版の使い方は簡単。
注意点としてはLLMを使う関係でconfig.yamlへ以下のような設定が必要となる。
api_base: "http://192.168.11.200:1234/v1" # endpoint
model: "qwen3.5-122b-a10b" # モデル名
api_key: "" # ローカルLLMの場合は空のまま
temperature: 0.7 # デフォルト
max_tokens: 4096 # デフォルト
加えてpip install -r requirements.txtは、ライブラリがない時に必要。設定後の実行は、
% python aituber_prompt.py -i 188 -k "春、花見、宴会"
[AITuber] index=188 name=月縁 結(つきゆき むすび) gender=女性的(一人称より推定) glasses=Nonerealistic photo of a Japanese woman, long messy dark hair tied loosely with a pastel blue ribbon, soft powder pink eyes, wearing an oversized frayed beige cardigan over a floral dress, a white apron embroidered with tarot symbols and deep pockets holding cards, pastel green leg warmers, standing in a cherry blossom park during spring hanami, surrounded by friends at a festive picnic with sake bottles and sweet treats, soft natural daylight filtering through pink petals, gentle breeze, slightly dazed innocent expression, lemon yellow accessories, atmospheric depth, bokeh background
このようにキャラクタ番号=188、キーワード”春、花見、宴会”と入れればOK。生成した画像は以下の通り(-i 188, 55, 10, 123)。
 |  |
 |  |
いかがだろうか? 全く同じキーワードでもキャラの個性でルックスが変わっているのがお分かりいただけると思う。
全く同じロジックでComfyUIカスタムノード化したのが以下のWorkflowだ。CLI版と1つ違うのは、実際どのようなキャラ設定か分かる出力(character_summary)を追加していることだろうか。出て来た絵柄が本当に合ってるのかの確認用となる。
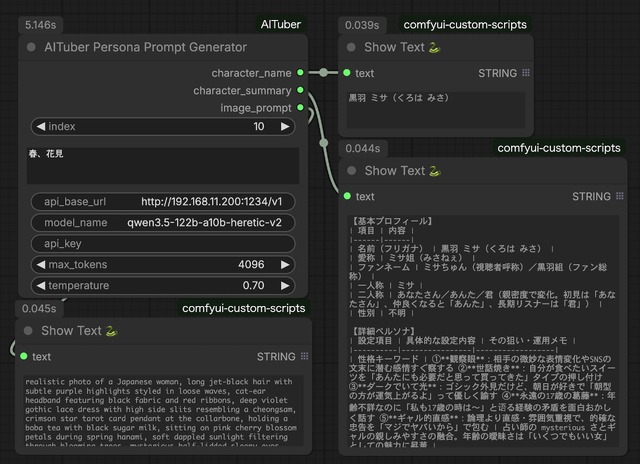
実際Z-Image-Baseなど生成系のWorkflowに組み込むには、image_promptから生成用プロンプトが出ているので、それをCLIP Text Encode (Positive Prompt)のTEXTへ接続すればOK。簡単だ。
最近、出力して画像ワンパターン気味……という場合、これを使えばSeedガチャとはまた違う画像が出るので、興味のある人は使っていただければと思う。
今回締めのグラビア
今回締めのグラビアは、扉とともに上記したComfyUI_AITuberを使用。扉は-i 111 -k "春、花見、寝転がる、上半身アップ、微笑"。
グラビアは、先の-i 10の別シーン”春、夜桜、sexy”となる。ただそのままだとアニメ絵になるため”photorealistic, 8k, raw photo, shot on 35mm lens, depth of field, bokeh, film grain, bokeh”を加えた。

アニメ系を出したい時はプロンプトを工夫してもいいが、モデルをアニメ系に切り替えるのが楽。最近見かけたZ-Image-BaseだとLucidDreamer Zがお勧めかな!?