







生成AIグラビアをグラビアカメラマンが作るとどうなる? 連載記事一覧
5月9日、t2i/i2i対応の新生「HiDream-O1」リリース!
HiDreamと言えば、I1が去年の4月にリリースされている。結構高性能で当初流行っていたFLUX.1 [dev]を超えるか?との見方もあったが、その後8月にQwen-Imageが登場し、吹き飛んでしまった感じだ。

それからほぼ1年後、完全に忘れた頃にO1となって再登場! もともとt2iはI1、i2i (Edit) はE1と分かれていたが、今回は一本化され、Full版とDev (蒸留) 版、二本立てになっている。特徴は、
8Bパラメータ
Full 50 steps / cfg 5.0
Dev 28 steps / cfg 1.0
最大4MP
2048×2048
2304×1728 / 1728×2304
2560×1440 / 1440×2560
2496×1664 / 1664×2496
3104×1312 / 1312×3104
2304×1792 / 1792×2304編集は1枚、リファレンスは複数枚(設定方法などは実装による)
MITライセンス
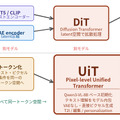
Pixel-level Unified Transformer (UiT) 採用
と、こんな感じだ。驚くべきポイントが2つある。1つは最大4MP! これまで1MPから2MP程度だったのが、いきなり飛び越えて来た感じだ。
そしてもう1つはPixel-level Unified Transformer (UiT) 採用。これ何の事かと言うと、従来方式ではTransformer / Text Encoder / VAEの3点セットだったのが、HiDream-O1では1つになっている。この1つはよくあるcheckpointで1つのファイルに3つ抱えたものでなく、純粋に1つ。言葉だけではわかりにくいと思うのでClaudeくんに図を作ってもらった(笑)。
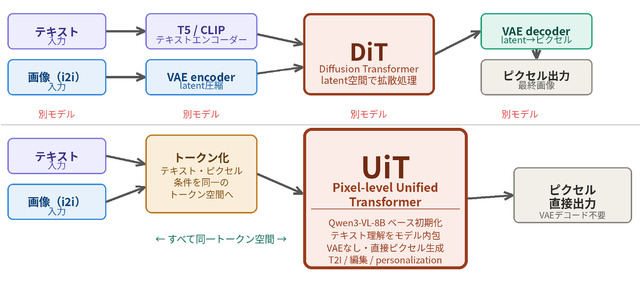
これで一目瞭然だろう。従来方式に慣れてると、こんな方法でできるの?的になるのも頷ける。利点と欠点は以下の通り。
利点
ロスがない
VAEのエンコード/デコードを経由しないので、細部の情報が失われない。テキストレンダリングが強いのはこれが理由タスク切り替えが不要
t2i・編集・personalizationが同じモデル・同じ経路で処理できる。FLUXでIP-AdapterやControlNetを別途載せる必要がない構造に相当するものが最初から内蔵
欠点
計算コストが高い
VAEはピクセルを64分の1に圧縮してからDiTに通すので、latent spaceはとても小さいが、UiTは2048×2048のピクセルパッチを直接処理するので、トークン数が桁違いに多くなる解像度の自由度がない
position embeddingsがプリセット解像度に固定されているため、任意解像度が使えないエコシステムが未成熟
VAE/テキストエンコーダーが独立していないので、既存の拡張資産が流用できず、全て専用設計が必要に生成速度
latent spaceを使えないので、同じステップ数でも1ステップあたりの計算量が多い
利点はなるほど的な感じだが、その分欠点も随分ある。他が採用していないのもこの辺りのバランスなのだろう。
さて、理屈はともかく、絵はどうなのか?をチェックしてみたい。
Dev Part1/生成
生成は何時ものComfyUIなのだが、実は執筆時段階で公式なWorkflowは出ていない。コアのエンジンがHiDream-O1に対応しただけの状況なのだ。
以下のWorkflowは筆者がいろいろなサイトから得た情報を組み合わせているだけで正解かどうかは不明。公式のWorkflowが出た時はそちらを参考にして欲しい。
またFullは謎な部分が多いため今回はDevだけを対象とした。予めご了承いただきたい。完全なWorkflowが分かった時に改めてご紹介する。
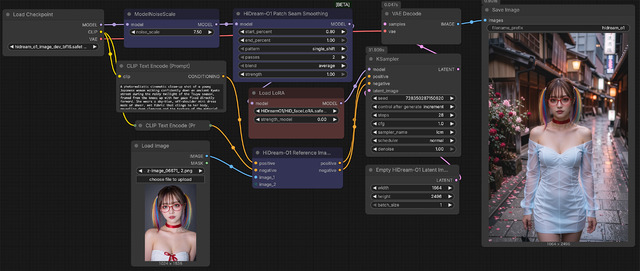
このWorkflowは参照画像を使い、HiDream-O1 Reference Imagesノードがイネーブルになっているが、単純なt2iの時はバイパスして使う。Load LoRAは顔LoRA用。すでにai-toolkitが対応している。ブルーのノードがComfyUIに搭載したHiDream-O1専用(ModelNoiseScaleは前からある)。それぞれ、
ModelNoiseScale: 7.50
HiDream-O1 Patch Seam Smoothing: 上から順に0.80/1.00/single shift/2/avarage/1.00
この値に固定。ただし、HiDream-O1 Patch Seam Smoothingは、ないWorkflowもあるのでどちらが正解かは不明。バイパスすると細部が若干異なる程度の差でしかない。KSamplerは、
ステップ数: 28
サンプラー: lcm
スケジューラ: normal
CFG: 1.0
必要なファイルはPixel-level Unified Transformer (UiT) なので1本だけ。この点は楽だ。ここにいろいろな量子化バージョンがあるので、VRAM容量などに合わせてピックアップしてほしい。今回はbf16版を使用している。
では早速作例を6つ。1つ目はいつもの”a young Japanese woman”。
 |  |
 |  |
 |  |
いかがだろうか? ギターのヘッドは微妙だが、ちょっとこれまでにはないテイストでDevでもなかなかのもの。日本語も含め文字も出る。気になる生成時間は1644x2496px、RTX 5090で12秒前後。約4MPと考えると逆に速い。
本家のリポジトリではgemma-4-31B-itを使ったPrompt拡張機能もあり、中国語だがここのSystem PromptをそのままLM StudioなどのSystem Promptにコピペすれば機能する。出力フォーマットがjsonになってることから、最近よく見かけるjson形式のPromptの方が相性は良さそうだ。
ただサンプラーがlcmなので細かい部分が情報不足気味。専用サンプラーが欲しいところ。全体的にくすんだ感じは蒸留モデル固有か? また他のモデルに比べて素のままだと美女度がちょっと低い(笑)。ここは顔LoRAで補えばバッチリとなる。
 |  |
ご覧のように肌の色も結構変わる。Pixel-level Unified Transformer (UiT) ならではなのだろうが、学習する素材は色も含めキッチリした画像を用意したいところか。
加えて顔LoRAを使うと画像全体のテイストも変わる。作例は油絵っぽい感じなのだが、顔LoRAを使うとリアルな写真っぽくなる(右側LoRAあり、扉、グラビア)。この点は今後の研究課題か!?
今回締めのグラビア
今回締めのグラビアは、扉もグラビアもHiDream-O1 Devと顔LoRAを使用。扉は2688x1536px、グラビアは1664x2495pxで出力し長辺を1920pxへ縮小、掲載した。

今回、生成だけで結構長くなったため、Part2のi2i/リファレンスに関しては次回に。加えてFullのWorkflowも判明しているはずだ。お楽しみに!



















