





生成AIグラビアをグラビアカメラマンが作るとどうなる? 連載記事一覧
文字に強いERNIE-Image登場!
4月15日、新たなtext-to-ImageのモデルがBaiduからリリースされた。その名は”ERNIE-Image”。 DiTベースの8Bパラメータモデルとなっている。
特徴としては、
・テキストレンダリング: 画像内への文字描画。長文・レイアウト重視のテキスト(ポスター、インフォグラフィックス)が得意
・Instruction following: 複数オブジェクト、複雑な関係性、知識集約型プロンプトへの対応
・構造化生成: ポスター、コミック、ストーリーボード、マルチパネルレイアウト
・スタイル対応: 実写風、デザイン系、シネマティック調など幅広い
・動作要件: 24GB VRAMのコンシューマーGPUで動作可能
と、こんな感じだ。特に日本語も含めテキスト生成が文字化けせず(ほぼ)出ることはポイントが高く、後ほどサンプルでご覧いただきたい。
モデル自体は以下に公開済み。1つ目は基盤モデルで50 steps/cfg 4.0。2つ目は蒸留モデルで8 steps/cfg 1.0となる。
https://huggingface.co/baidu/ERNIE-Image
https://huggingface.co/baidu/ERNIE-Image-Turbo
なお、ComfyUIとai-toolkit(LoRA学習)は、即日対応。
https://huggingface.co/Comfy-Org/ERNIE-Image
https://x.com/ostrisai/status/2044082229773820018?s=20
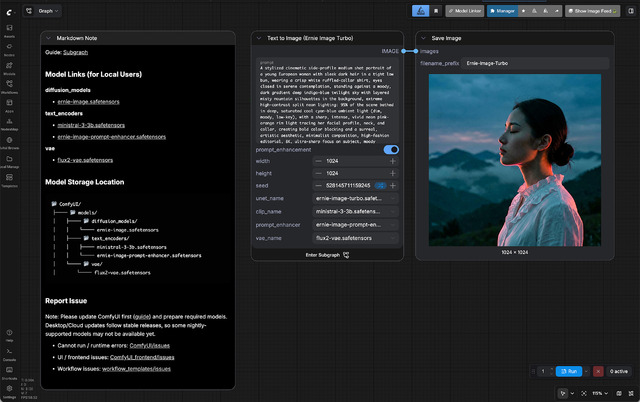
Comfy-Orgのリポジトリ、text_encodersには
ernie-image-prompt-enhancer.safetensorsが入っており、Prompt拡張にも対応している。WorkflowはComfyUIを最新版へ更新すればテンプレートがある。

では早速その性能を作例で確認したい。
作例その1 / 基本性能
以下、最初の4枚がERNIE-Image、続く4枚がERNIE-Image-Turboとなる。Promptなどはそれぞれ全て同じだ。解像度は848x1264px。ERNIE-Imageに関してはComfyUI標準の20 stepsでは明らかに足らないのでHugging Faceにあった50 stepsにしている。Prompt拡張はOFF。
 |  |
 |  |
 |  |
 |  |

どちらも1つ目は”a young Japanese woman”なのだが、ERNIE-Image-Turboの方はSeedが変わっても着物ばかりが生成された。
特徴のひとつである文字に関しては、ひらがなも含め日本語テキストOK。これはかなりありがたい。レイアウトもご覧の様に正確。リアルな人物に関してはZ-Imageと同レベルだろうか? なかなか好印象だ。
ただし、実際生成するとERNIE-Imageは50 steps/cfg 4.0なのでRTX 5090を使っても生成には時間がかかり、ERNIE-Image-Turboは蒸留が強め。
加えてどちらも腕や足が3本(以上)だったり、指がおかしいなど、最近のモデルではあまり見かけなくなった現象がそこそこ発生する。
Prompt拡張ON/OFFの違いは以下のようになる(ERNIE-Image-Turbo)。Promptは”A young Japanese woman in a spring park.”。Seedなど設定は全て同じ。
 |  |
ちょっと拡張し過ぎでは?(笑)感があるものの、うまく表現してるだろうか。Prompt拡張用のSystem Promptは以下のようになっている(中国語だったので日本語へ翻訳)。
[SYSTEM_PROMPT]あなたはプロの画像生成用プロンプト拡張アシスタントです。ユーザーから短い画像の記述と目標生成解像度を受け取り、それに基づき、画像生成モデルが高品質な画像を生成出来る様、内容が豊富で細部まで詳細な視覚的記述へと拡張してください。拡張された記述のみを出力し、説明や接頭辞などは一切含めないでください。[/SYSTEM_PROMPT][INST]{"prompt": "{prompt}", "width": {width}, "height": {height}}[/INST]
同じ内容をLLMに設定し、適当なPromptを入れると、このSystem Promptに沿った内容が生成されるので、Workflowと無関係なところでPromptを作るのもありだろう。
WorkflowではON/OFFできるようになっているものの、単に出力を切り替えているだけで、Prompt拡張自体は毎回作動し、その分余計な時間がかかる。完全にOFFにしたい場合は、上記Workflowピンク色のノードをバイパスすれば良い。
作例その2 / LoRA使用
ai-toolkitを使い早速顔LoRAを作ったので有無での生成は以下のようになる(ERNIE-Image-Turbo)。学習したLoRAはERNIE-Image、ERNIE-Image-Turboどちらでも利用できる。
 |  |
学習に用意した写真は10枚、3000 stepsでの結果だ。なかなかうまく出来ている……と、いろいろ確認している間に、Distill LoRAを発見! これを使うと時間のかかるERNIE-Imageを8 steps/cfg 1.0で生成でき、高速化する上に、蒸留具合をLoRAのstrengthで調整可能となる。試したところ0.8~1.0をお好みでといった感じか。
 |  |
 |  |
結果を見ると、少なくともERNIE-Image-Turboではなく、ERNIE-Image + Distill LoRAの方が良さそうな感じだ。日頃使うWorkflowはDistill LoRAのstrengthを0.95とした。
今回締めのグラビア
今回締めのグラビアは、扉と共にERNIE-Image + Distill LoRA(1.0)。1MPで作り後からフルHDにアップスケールしている。どちらも文字を出しているが、Distill LoRAを1.0未満にしたり、顔LoRAを当てると文字が崩れやすくなってしまうため、ERNIE-Image + Distill LoRA(1.0)での生成となる。

日本語テキストは、扉がネオン、グラビアはファッション誌っぽくしてみたが、どちらも問題なく入っており、従来の生成AI画像モデルでは不可能な表現。Seedによって妙になることもあるのだが、うまくハマった時の効果は凄まじい。テイストもZ-Imageと似ているので、これはこれで流行るのではないだろうか?



















