



1週間の気になる生成AI技術・研究をいくつかピックアップして解説する連載「生成AIウィークリー」から、特に興味深いAI技術や研究にスポットライトを当てる生成AIクローズアップ。
今回は、中国企業のMeituanが公開した、1枚の画像と音声データから自然に話すアバター動画を生成するオープンソースAI「LongCat-Video-Avatar 1.5」を取り上げます。MITライセンスでの提供です。

▲LongCatのロゴ
進化のポイントは、音声を解析するシステムにOpenAIの「Whisper-large」を採用したこと。これにより、入力された音声とアバターの唇の動きが極めて正確に同期し、従来よりもはるかに滑らかで自然な口元の表現が可能になりました。

▲LongCat-Video-Avatar 1.5で生成したサンプル
さらに、人間の好みを反映させる強化学習の仕組みをトレーニングに取り入れたことで、長時間の動画でも顔の印象が変わってしまったり、体や手が不自然に歪んだりするAI特有のエラーを抑え込んでいます。
また、実写の人間だけでなく、アニメキャラクターや動物の画像にも対応できます。AIに学習させる動画データを厳選・整理することで、複数の人が会話する複雑なシーンや、発言していない無言状態での自然な待機モーション、さらには手と物が交差するような難しい状況でも違和感なく映像を生成できるようになりました。
AIの動画生成は計算が重くて遅いのが弱点ですが、動画を作り出すための計算手順を8ステップにまで圧縮することで、高速かつ低コストな生成を実現しました。
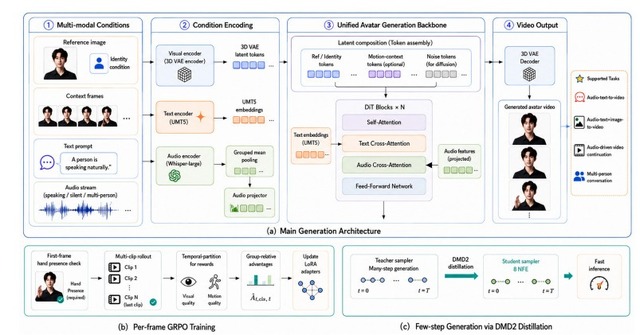
▲LongCat-Video-Avatar 1.5のアーキテクチャ
実力を測るため、ニュースや教育、日常、エンターテインメント、歌唱、商用プロモーションといった6つの利用シーンを想定した独自の評価ベンチマークを用意しました。中国語と英語の2言語、実写とアニメの2スタイルにまたがる計508組の画像と音声のペアを対象に、770名の評価者による主観評価と10名の専門家による客観評価を実施しました。
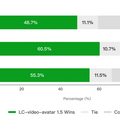
結果は、専門家による客観評価の4項目のうち、時間的安定性、物理的妥当性、同一性の維持の3つで、本モデルは他モデルを抑えてトップを記録。調和だけは他モデルが僅差でトップでした。
一般ユーザーによる比較テストでは、HeyGenやOmniHuman 1.5、Kling Avatar 2.0などの商用モデルを抑え、自然で人間らしいと支持されています。
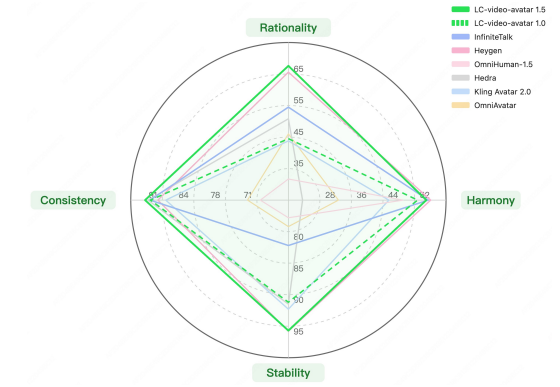
専門家による4項目の評価
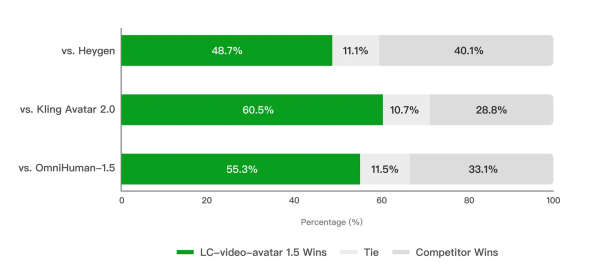
▲一般ユーザーによる評価結果
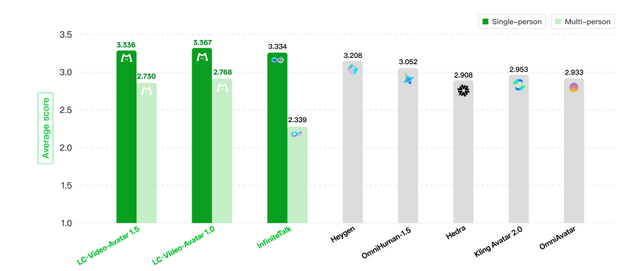
▲各モデルの平均スコア比較。濃い緑は人物1人、薄い緑は多人数

▲既存モデルとの比較