

1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第7回目は、自律AIが暮らす街をシミュレートした研究など、5つの論文をまとめました。
生成AI論文ピックアップ
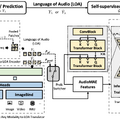
テキストから音声を生成する汎用性の高いAI「AudioLDM 2」
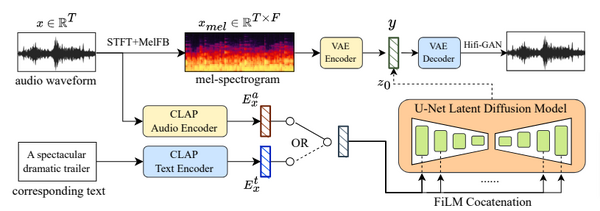
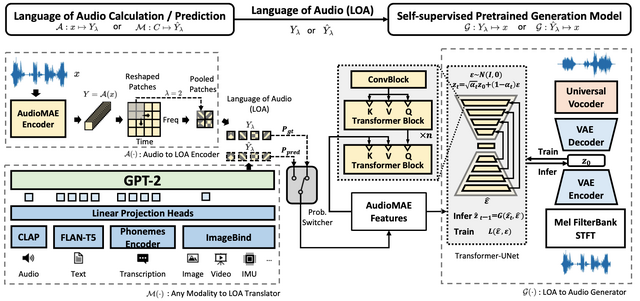
「AudioLDM 2」と呼ばれる新しい汎用フレームワークは、テキストから音声、音楽、効果音などあらゆるタイプのオーディオを生成する能力を持っています。
このフレームワークの中心には、「language of audio」(LOA)という革新的なコンセプトがあります。これはオーディオクリップの意味をベクトルとして捉えるもので、人間が理解できる情報を音の言語に変換し、それを基に音を生成することができます。
生成過程では、どんな形態のデータでもLOAに変換するためにGPTモデルを使用し、その後、潜在拡散モデルを使って自己教師付きで音声を生成します。
実験では、このAudioLDM 2がテキストからオーディオ(TTA)やテキストから音楽(TTM)生成のタスクで最先端の性能を達成。さらに、画像から音声への変換など、視覚的なデータを音声生成に利用可能です。
先代のAudioLDMと比較すると、AudioLDM 2は同じ機能を保持しつつ、音声の品質、応用範囲、明瞭さの面で大きな進展を遂げました。
プロジェクトページでは、テキスト指示とそれに応じて生成された音声を確認できます。
AudioLDM 2: A General Framework for Audio, Music, and Speech Generation
Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, Mark D. Plumbley
Project Page | Paper | GitHub | Hugging Face
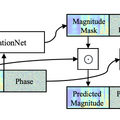
テキスト指示から音源を分離するAI「AudioSep」
「language-queried audio source separation」(LASS)は、自然言語の説明を使って特定の音源(例:楽器や特定クラスの音声イベント)を分離する技術分野です。最近のLASSの研究で進展が見られますが、オープンドメイン、すなわち特定の領域に限らない音声コンセプトの分離にはまだ到達していません。
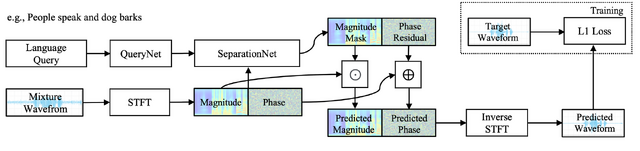
今回紹介するAudioSepは、この問題を解決するための基盤モデルです。オープンドメインの音声分離を自然言語の説明を用いて行うことができます。具体的には、テキストラベルや音声キャプションをクエリとして使用し、新しいシチュエーションにも対応可能なゼロショット分離を実現します。
AudioSepの中核となるのは2つの主要な部分です。一つは、テキストエンコーダとして「CLIP」や「CLAP」といったテキストと画像、オーディオの事前訓練モデルを使用します。もう一つは、分離のために周波数領域のResUNetモデルを適用する部分です。
このAudioSepモデルの性能を検証するため、様々な音源分離タスクにおけるLASSベンチマークを設計。その結果、オーディオイベントの分離や楽器の分離、音声の強調などのタスクで、既存のオーディオクエリ音源分離モデルや最先端のLASSモデルを大きく上回る結果を示しました。
Separate Anything You Describe
Xubo Liu, Qiuqiang Kong, Yan Zhao, Haohe Liu, Yi Yuan, Yuzhuo Liu, Rui Xia, Yuxuan Wang, Mark D. Plumbley, Wenwu Wang
Project Page | Paper | GitHub
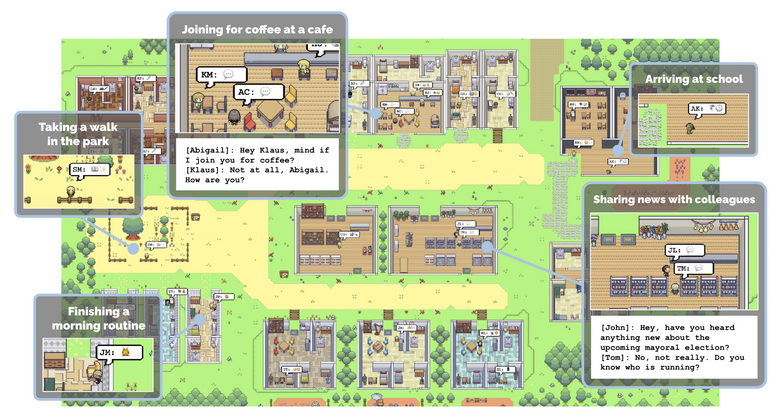
25体の自律AIが住む街をシミュレートした研究「Generative Agents」のオープンソースが登場
2023年4月に米スタンフォード大学とGoogle Researchに所属する研究者らが発表した論文「Generative Agents: Interactive Simulacra of Human Behavior」のオープンソースがこの度公開されました。
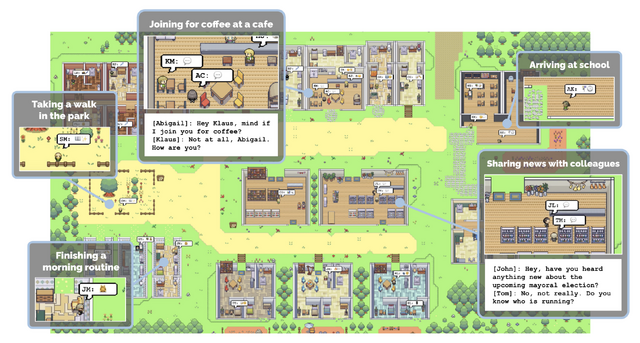
この研究は、25人のキャラクターが一つの街で共同生活する様子をシミュレートしたもので、それぞれのキャラクターはChatGPTなどで制御されています。キャラクターたちはレトロRPGゲーム風のバーチャル世界で、それぞれ異なる架空の人格を持ち、自発的な行動を展開します。
キャラクターたちは2Dアバターで表現され、それぞれ独自の生活パターンを持っています。起床から就寝、出勤、仕事、遊びなど、個々のキャラクターが独立して行動します。自然言語でキャラクターのプロフィールや相互関係が設定され、他のキャラクターとのコミュニケーションが可能になっています。
キャラクター同士の出会いや会話によって、日常生活や環境に関する情報が交換され、記憶が形成されます。これにより、キャラクターは今の環境を認識し、次の行動を決定することができるのです。さらに、内省する能力も持っており、新しい洞察や長期計画を立てることができます。
具体的な例として、キャラクターのイザベラ・ロドリゲスが企画したバレンタイン・パーティーが挙げられます。彼女は友人やお客さんを招待し、カフェを飾り付けました。さらに、彼女の片思いの相手であるクラウスも招待しました。このプロジェクトでは、キャラクターが自律的にパーティーを計画し、新しい知人を作り、タイミングを調整する様子が観察されました。
Generative Agents: Interactive Simulacra of Human Behavior
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, Michael S. Bernstein
Paper | GitHub
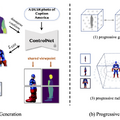
テキストから高品質な3Dアバターを生成するAI「AvatarVerse」
近年、3Dモデル作成の分野で注目されているのが、NeRFを使った高精細なモデリングです。これには、テキストと画像を生成する訓練済みのモデルを使用する手法が調査されています。しかし、いろいろなポーズや外観を持つ高品質な3Dアバターを安定して作るのは、今も難しい課題です。多くの場合、画質がぼやけたり粗くなったりし、高解像度のテクスチャなどの細部が欠けてしまいます。
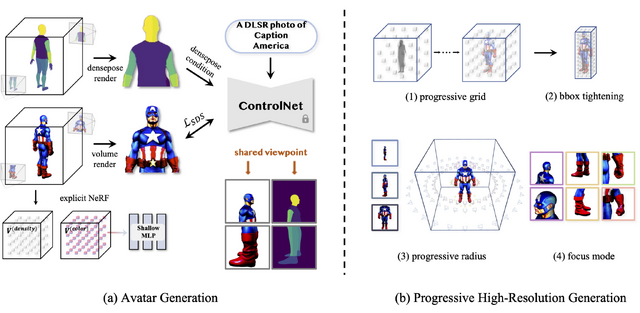
この問題を解決するための新しい提案が「AvatarVerse」です。このフレームワークは、テキストとポーズをガイドに、安定して高品質な3Dアバターを生み出します。
具体的な手順は以下の通りです。まず80万以上の画像を使って、人間のDensePose条件で新しいControlNetを訓練します。ControlNetに2D DensePose信号に基づいたSDS(スコア蒸留サンプリング)ロスを実装します。これによって、2Dビュー間や3D空間との正確な対応を得ることができます。
訓練したDensePose条件付きControlNetを使うと、NeRFの最適化を更に安定化し、部分的または全身の制御を容易にします。この方法により、徐々に高解像度を向上させる戦略のおかげで、生成された3Dアバターは素晴らしいテクスチャと幾何学的な品質を示します。
さらに、生成されたアバターはSMPLモデルと高い整合性を示し、アニメーション化も容易に行えます。
AvatarVerse: High-quality & Stable 3D Avatar Creation from Text and Pose
Huichao Zhang, Bowen Chen, Hao Yang, Liao Qu, Xu Wang, Li Chen, Chao Long, Feida Zhu, Kang Du, Min Zheng
Project Page | Paper
“チラつき”を抑えた動画合成を生成するAI「DiffSynth」
近年、画像合成の分野では拡散モデルが最も強力な手法として注目されています。だが、この手法をビデオ合成にそのまま使用すると問題が生じ、特に画像のチラつき(フリッカー)が顕著になることが課題となっています。一部の新しい方法ではちらつきを減少させることができますが、高品質な一貫したビデオを生成するのは依然として困難です。
この問題に対処するため、今回の研究では「DiffSynth」という新しい手法を導入します。DiffSynthの目標は、画像合成の流れをビデオ合成に適用することで、次の2つの主要構成要素から成り立っています。
1つ目のデフリッカリングフレームワークは、拡散モデルの潜在空間にビデオのチラつきを取り除く機能で、フリッカーの累積を効果的に防ぎます。2つ目のビデオデフリッカリングアルゴリズムでは、異なるフレームのオブジェクトを再マップし、ブレンドすることでビデオの一貫性を強化します。
DiffSynthはStable Diffusionに基づく多くのモデルと互換性があります。その結果、画像合成の研究成果を活用し、テキストガイドのビデオ合成、ファッションビデオ合成、画像ガイドのビデオ合成、ビデオの復元、3Dレンダリングなど、様々なタスクへの適用が可能になります。

DiffSynth: Latent In-Iteration Deflickering for Realistic Video Synthesis
Zhongjie Duan,Lizhou You,Chengyu Wang,Cen Chen,Ziheng Wu,Weining Qian,Jun Huang,Fei Chao
Project Page | Paper | GitHub