






今回は、表題にあるように、AI歌声合成への挑戦を開始するに至る過程について書いています。筆者はVOCALOIDに代表される歌声合成関連の記事を書いたり実践したりして15年くらいになるのですが、ついに自分で機械学習を使う歌声合成にトライする、その取り掛かる(まだやってはいない)までの経緯を説明するものです。
コンピュータを利用することで、存在しえない声や画像を再現すること。筆者はこの10年ほどこういったことに挑戦しています。ただし、自分で開発・研究するのではなく、一般的に入手できる方法で実践しています。
筆者がやっている、10年近く前に他界した妻の写真をAIに学習させ、新たな画像を生成していることは、和洋問わず神話でもやっちゃダメなことに挙げられているくらい自然の理に反したエキセントリックな例と思われがちですが、実は一般的に応用が効くものが多く、その意味で、この連載でお伝えする意味はあるのではないかと考えています。先週末に開催したテクノエッジのイベントでも、これを亡くなった家族で実践してみたいといった話も伺うことができました。

そして、「本当に必要な情報は、発信する人に集まる」というのを最近、実感しています。
例えば複数の人物写真から、機械学習によってその人物に似た画像を生成するAI作画の仕組み。筆者の場合には妻の写真から、まだ見たことのない写真や肖像画が無限に生み出される状況になったのは、AIプログラマーででAI漫画家でもある清水亮さんがMemeplexを始めたのがきっかけ。
「写真を読み込んで生成できるようにしてくださいよ」としつこくお願いしていたところ、すぐにMemeplexのサブスクサービスで実現し、論議を呼んだ一連の記事につながったわけです。

呪文と呼ばれる命令文「プロンプト」によるAI作画は順調に進化していて、画風も標準のStable Diffusionだけでなく、フォトリアリスティックなもの、アニメ特化型、日本の画風向けなど、さまざまな派生モデルが利用可能になりました。Memeplexでは、いつの間にか新モデルが使えるようになっていて、さらにカスタム学習が可能になったりするので、妻の写真を学習させたものだけで4種類あります。
呪文を共有できる仕組み
Memeplexの最近の取り組みで面白いのは、呪文を共有できる仕組み「呪文ラボ」がサブスクユーザー向けに追加されたこと。これが超便利。メニューからプルダウンしていくだけで必須だけど毎回入力するのは面倒だなというようなユーザー投稿による呪文(特にネガティブプロンプトと呼ばれる、絵に含みたくない要素を列記するもの)を簡単に呼び出せます。あとは自分が希望するものに集中できるというわけ。
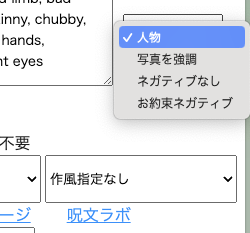
▲パワーユーザーが作成した呪文をプルダウンで利用できる
最近、自分でも進歩したなあと思うのは、希望する顔の要素を呪文(といってもただの英単語の組み合わせです)に記述し、出てほしくない要素をネガティブプロンプトに入れておけば、かなりの確率で希望する容貌の絵が出てくるようになってきたこと。
衣装や表情については、参考になる文献も多いのですが、顔の要素についてはなかなか見つけられないため、思い当たる要素の英語表現を探し出して、それで絞り込んでいきます。
顔の造作を言葉で表現する
例えば、妻の顔の特徴である、「薄い涙袋」は「narrow eye bags」、「二重瞼」は「double eyelids」、「ちょっと吊り目気味」は「slightly slanted eyes」をプロンプトに入れます。両目の間隔が離れすぎている絵が頻出するのをなくすには、ネガティブプロンプトに「distant eyes」を入れておく、といったことを最近学びました。参照している絵がアジア人だと見ると、一重瞼で離れ目になりがちという、ある意味、人種バイアスというか、学習元データの偏りがあると思うのですが、それを呪文で回避するわけです(しかし、離れ目の呪縛から逃れるのはなかなか困難でした)。

▲非カスタム学習モデルでは、同じプロンプトにしても、こうなることが多い(distant eyesをネガティブにしてもこうなってしまう)

▲妻の写真から学習したデータ(同じプロンプト)
Memeplexユーザーが集まるDiscordチャンネルも情報の宝庫で、Stable Diffusionで出がちな「和服だか中国服だかわからないけど洋装ではないアジア系の衣装が頻出する問題」は、ネガティブプロンプトに「kimono」を入れ、目が異様にデカすぎる問題は同様に「anime」を入れるといいといった情報も得られ、すぐに取り入れました。

▲謎の東洋風衣装(ネガティブにkimonoを入れて回避)
おかげでAI作画が捗り、妻の誕生日にミュージックビデオ制作を間に合わせることができました。4分を超える大作で、歌声合成ソフトのUTAU-Synthを使った妻の歌唱生成だけでなく、オケの制作(iPadのGarageBandでだいたい作って、Logic Proで最終調整)にもそれなりの手間がかかるため、サウンドにフォーカスできたのは大きいです。
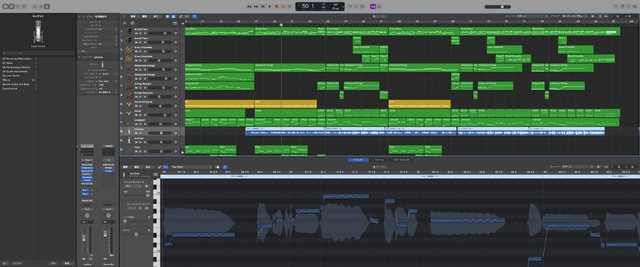
▲上がLogic Pro、下はUTAU-Synth
言葉で顔の造作を表現するスキルが達人レベルになると、元の写真を学習しなくてもその人の画像が出せたりするのかも、などと思いました。実際、似顔絵作家の方々は、被写体の特徴を捉え、それを筆で表現しているのですから、それを言語化できれば近いことは可能なのかもしれません。
今回カバーした小坂明子さんの「あなた」は、以前から妻の歌声でやりたいと思っていた曲なのですが、「小さな家だけど、大きな窓と小さなドアがあって、部屋の中には青い絨毯があり、古い暖炉まで設置されていて、庭には赤い薔薇と白いパンジーが咲き誇っており、子犬がいて」みたいな写真なり絵なりを探すのは大変だなと二の足を踏んでいました。
そこに妻がピアノを弾いている写真を何点か入れたいけど、そういった写真は数点しかないし、それらは過去の楽曲で使い尽くしています。「レースを編む妻」の写真もありません。好きだったんだけど。レースを編む歌詞はキー上げして再度登場するので、ミュージックビデオにする場合には必須でしょう(ちゃんと妻に似た顔の人が編んでいる写真が出てきたのはさすが)。


▲青い絨毯が敷かれた部屋にある古い暖炉(上)と、レース編み中の、妻に似た人の写真(下)
Stable Diffusionとその派生系ではこういうのは簡単で、さらにカスタム学習を駆使すれば、家の中に希望する人物を配置することもできます。ただし現状では問題もあり、ピアノの鍵盤の形がいびつだったり、指がこんがらがったりして、そこはトリミングでカットしてあります。

▲未使用AI画像。人物の表情はいいのだけど、指と鍵盤の形が不自然だし、ピアノの構造もおかしい
YouTubeなどには、映像が存在しない名曲のミュージックビデオを、出どころがわからない写真のコラージュで勝手に作り上げたものがありますが、AI作画を使えば比較的容易かつ合法にそれが可能になります(音源の問題は別として)。将来の通信カラオケサービスでは、歌い手の写真を最初に取り込んで学習させ、それをリアルタイム生成したAI画像に埋め込んで、それを歌うなんてことも可能になるでしょう。
歌声もAIで
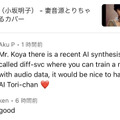
そしてようやく冒頭の話に戻るのですが、このミュージックビデオを公開してすぐに、海外のボカロPからコメントがつきました。
Mr. Koya there is a recent AI synthesis called diff-svc where you can train a model with audio data, it would be nice to have an AI Tori-chan ❤
そういえば、前回のミュージックビデオのときにもこんなコメントがついてました。
have you tried compiling her samples for an AI voicebank like Diff-SVC or NNSVS/ENUNU ?
これはもう挑戦しろということか、と「Diff-SVC」でググってみたところ、やり方を解説している日本語のブログが見つかりました。
・AI歌声合成?ボイチェン?Diff-SVCを徹底解説してみた!
ブログを書かれたアマノケイさんの解説によると、Diff-SVCは、1時間ほどの音声データがあれば、そこから声質を取り出してモデル化し、他の音声に適用することができる、声質変換の仕組み。以前、この連載で紹介した、「AI荒井由実」がやっていることと基本的に同じです。

同様の技術は、最新のVOCALOID6でも使われており、自分で歌うなり、他の歌声作成ソフトを使って歌詞付きの歌を作って、それに指定した歌声の声質を適用するというもの。「調教」の手間がいらないというか、それは自分の歌唱力次第というわけです。

先ほど紹介したブログには、Google Colabを使った作成方法が書かれているので、これから試してみます。1時間ほどの音声データが必要だということですが、妻音源とりちゃんには9年以上の蓄積があるので、データ量としては十分。
自分は数年前に、風邪をひいた後で声がちょっと枯れ気味になって、以前のようなクリスタルボイス(笑)ではなくなってしまい、ちょっとだけ残念に思っているのですが、以前の歌唱データを使えばこの辺もなんとかなりそう。妻のAI歌声と同様に、若返った声でデュエットができるのを楽しみに、まずはGoogle Colabってどうやって導入するんだっけ、というところからスタートです。
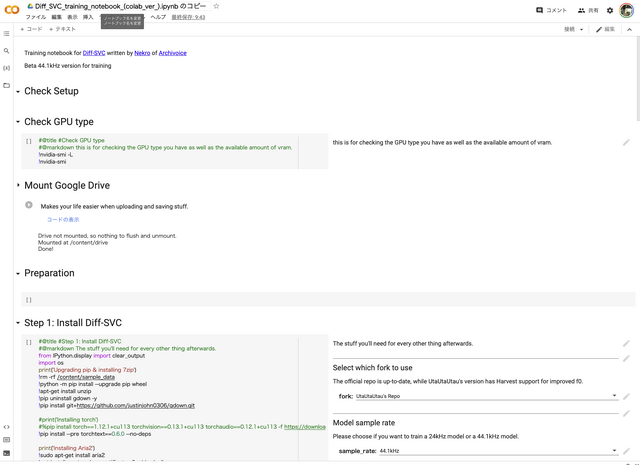
とりあえず、Google ColabでDiff-SVCのプロジェクトをインストールするところまではできました(ガイドに従っていくだけで、驚くほど簡単)。これから妻の歌声やら話し声やらを集めてzipにまとめてアップロードします。これが一番時間がかかりそうです。
そんなわけで、AI妻音源とりちゃん、はじめます。
▲10年前の筆者の声もDiff-SVCに利用可能
追記:2日でできるようになったので、本格稼働した記事を書きました。




















![Mia(ミーア)おしゃべり猫型ロボット ブラック・充電なしモデル 全国47都道府県の方言対応 AIペット 癒やし 家族 コミュニケーションロボット 高齢者 見守り ギフト プレゼント [性格カスタマイズ/リマインド機能搭載] image](https://m.media-amazon.com/images/I/31JfsEwtA0L._SL160_.jpg)
![Mia(ミーア)おしゃべり猫型ロボット ホワイト・充電なしモデル 全国47都道府県の方言対応 AIペット 癒やし 家族 コミュニケーションロボット 高齢者 見守り ギフト プレゼント [性格カスタマイズ/リマインド機能搭載] image](https://m.media-amazon.com/images/I/31PWkfpsEPL._SL160_.jpg)