





この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第142回)は、オープンソースで最高精度の「DeepSeek-V4」や、Claude Opus 4.5に迫る精度の270億パラメータであるマルチモーダルAIモデル「Qwen3.6-27B」を取り上げます。
また、情報密度を最大化して自己進化するAIエージェント「GenericAgent」や、テキストからプレイ可能なWebゲームを自動生成するオープンソースAI「OpenGame」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、検索するたびにAIがその場で画像を描き出し、クリックするたびに深掘りして画像をさらに描き続けてくれる新感覚のビジュアルブラウザ「Flipbook」を別の単体記事で取り上げています。
オープンソースで最高精度の「DeepSeek-V4」登場。競技プログラミングではClaude Opus 4.6やGPT-5.4に匹敵
DeepSeek-AIがオープンウェイトの大規模言語モデル「DeepSeek-V4」のプレビュー版を発表しました。
ラインアップには、総パラメータ数1.6兆(推論時にアクティブになるのは約490億)の「DeepSeek-V4-Pro」と、総パラメータ数2840億(アクティブ約130億)の軽量版「DeepSeek-V4-Flash」という2つのMoE(Mixture-of-Experts)モデルが用意されています。どちらも32兆トークンを超える多様なデータを用いて事前学習されています。
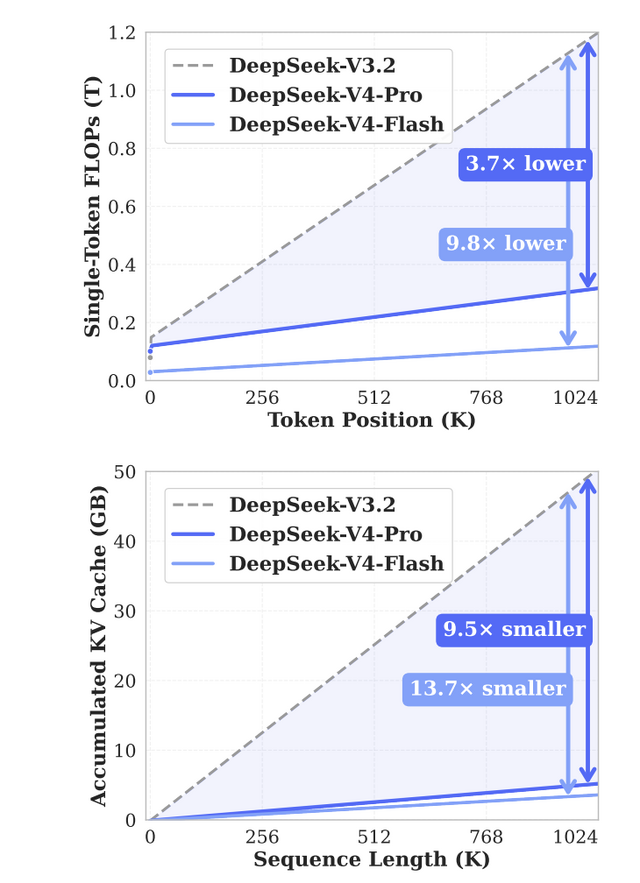
情報を圧縮して扱う2つの新しいアテンション機構(CSAとHCA)を組み合わせたハイブリッドアーキテクチャを採用したことにより、従来モデルのDeepSeek-V3.2と比較して、100万トークン処理時の計算量を約27%に抑え、メモリ消費の要因となるKVキャッシュを10%にまで削減することに成功しました。
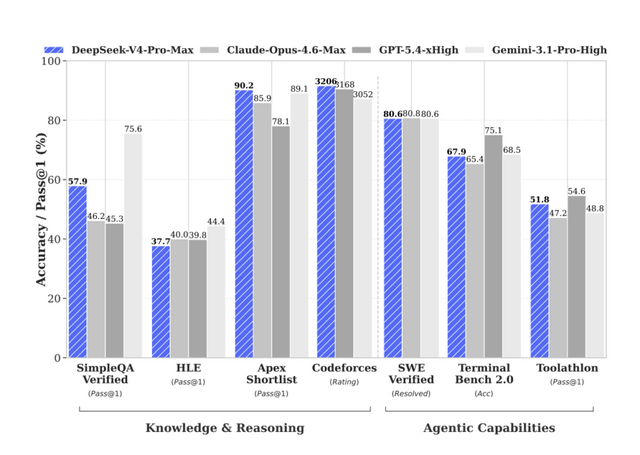
評価面では、最大推論モードの「DeepSeek-V4-Pro-Max」がオープンソースモデルにおける最高性能を更新しました。競技プログラミング系ではLiveCodeBenchで93.5点(Gemini 3.1 Pro 91.7、Claude Opus 4.6 88.8)、CodeforcesでElo 3206(GPT-5.4 3168、Gemini 3.1 Pro 3052)を記録し、クローズドモデルを上回っています。
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
DeepSeek-AI
Paper | Hugging Face
Claude Opus 4.5に肉薄、270億パラメータのマルチモーダルAIモデル「Qwen3.6-27B」登場
Qwenチームは、画像や動画も処理できる270億パラメータのマルチモーダルモデル「Qwen3.6-27B」をオープンウェイトで公開しました。思考・非思考の両モードに対応しており、商用利用可能なライセンスで提供されています。
前世代のMoE構造とは異なり新たなDense構造を採用しているため、MoE特有のルーティング処理が不要で、扱いやすい設計となっています。
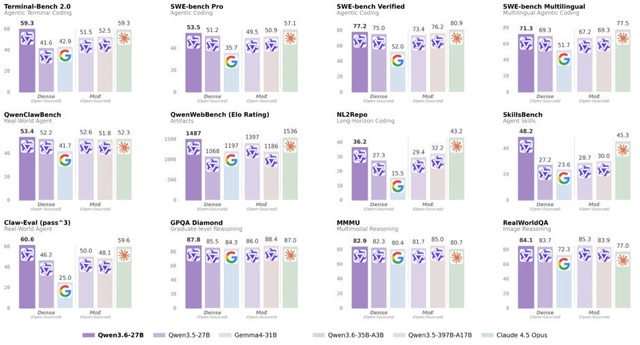
性能面ではコーディングタスクで卓越したパフォーマンスを示し、わずか270億パラメータでありながら、前世代の最上位モデル「Qwen3.5-397B-A17B」(総パラメータ数3970億)を、SWE-benchをはじめとする主要なコーディングベンチマークで上回る成果を達成しました。
Claude Opus 4.5との比較でも、コーディングタスク向けベンチマークのSkillsBenchなど一部の項目で上回り、全体としても肉薄する精度を示しています。

Qwen3.6-27B
Qwen
Blog | Hugging Face
量より質、情報密度を最大化して自己進化するAIエージェント「GenericAgent」
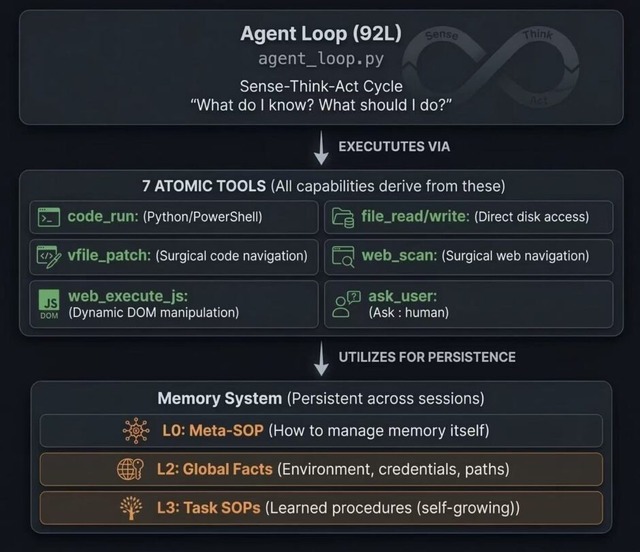
AIエージェントの活用が広がる一方で、作業が長引くとAIの記憶領域に不要な情報が蓄積し、意思決定に必要な情報が埋もれてしまうという課題がありました。この問題を解決する新たなシステム「GenericAgent」が発表されました。
このシステムの目的は、AIに与える情報の量を単に増やすのではなく、限られた容量の中にいかに価値の高い情報を詰め込むかを重視しています。
これを実現するために、主に4つのアプローチを採用しています。まず、AIが操作するツールを必要最小限に絞り込むことで、事前に読み込む無駄なデータを減らしています。
次に、普段は全体像がわかる最低限の記憶だけを保持し、詳細な情報は必要なときにだけ引き出すアプローチを導入しました。さらに、過去の成功体験を自動的にマニュアルやプログラムコードに圧縮して次に活かすメカニズムを備えています。そして、作業が長期化しても、古い情報や不要な部分を自動的に切り詰めて圧縮し、常に情報密度を高く保つ工夫が施されています。
検証テストの結果、GenericAgentは既存エージェントシステムと比較して、消費するデータ量を少なく抑えながら、同等以上の高いタスク成功率を達成しました。また、同じようなタスクを繰り返すごとに過去の経験から学習し、より少ない手順と時間で処理できるよう自己進化していくことも確認されています。

GenericAgent: A Token-Efficient Self-Evolving LLM Agent via Contextual Information Density Maximization (V1.0)
Jiaqing Liang, Jinyi Han, Weijia Li, Xinyi Wang, Zhoujia Zhang, Zishang Jiang, Ying Liao, Tingyun Li, Ying Huang, Hao Shen, Hanyu Wu, Fang Guo, Keyi Wang, Zhonghua Hong, Zhiyu Lu, Lipeng Ma, Sihang Jiang, Yanghua Xiao
Paper | GitHub
“ちゃんと動いて遊べる”、テキストからプレイ可能なWebゲームを自動生成するオープンソースAI「OpenGame」
自然言語の指示から、プレイ可能なWebゲームを全自動で生成するオープンソースのAIエージェントフレームワーク「OpenGame」が発表されました。
AIによるコード生成技術は飛躍的に進化していますが、複数のファイルが複雑に絡み合い、リアルタイムの処理が求められるゲーム開発を最初から最後まで完成させることは、従来の汎用的なAIにとって困難な課題でした。
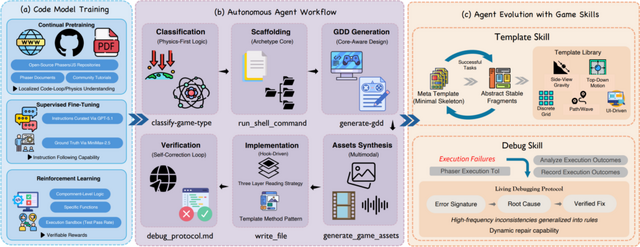
この問題を解決するため、研究チームは事前学習やファインチューニング、実行ベースの強化学習を行った独自の大規模言語モデル「GameCoder-27B」を開発しました。
さらに、過去の経験からプロジェクトの基礎構造をテンプレート化して安定させるスキルと、コンパイルや実行時のエラーに対する修正履歴を記憶し、自律的にデバッグを繰り返すスキルを搭載しています。
また、単にコードの正しさを測るだけでなく、ヘッドレスブラウザを用いて「実際にゲームが動くか」「視覚的に操作可能か」「ユーザーの指示通りか」を動的にテストする新たな評価システム「OpenGame-Bench」も構築しました。
150種類の多様なゲーム作成指示を用いたテストの結果、OpenGameは既存の主要なAIコーディングアシスタントを上回る最高水準の性能を達成しました。




OpenGame: Open Agentic Coding for Games
Yilei Jiang, Jinyuan Hu, Qianyin Xiao, Yaozhi Zheng, Ruize Ma, Kaituo Feng, Jiaming Han, Tianshuo Peng, Kaixuan Fan, Manyuan Zhang, Xiangyu Yue
Project | Paper | GitHub | Hugging Face