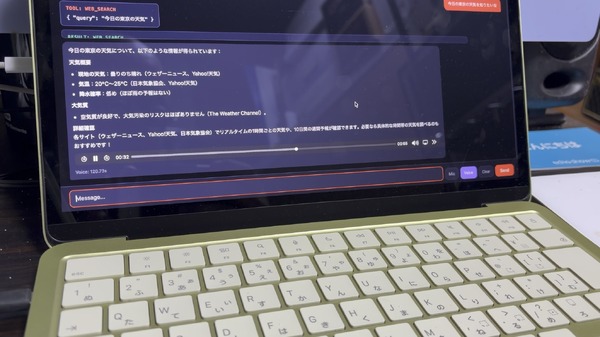


2週間前、「1ビットLLMのBonsai 8Bが8GBのMacBook Neoで爆速だった」という記事を書きました。1.1GBに8.2Bパラメータが詰まっていて、Tool Callingも完璧に動く。そして今日、Bonsai開発元のPrismMLが次の一手を打ってきました。
Ternary Bonsai。1.58ビット。Ternaryはラテン語の「3つずつ(terni)」を語源とする言葉で、「3つから成る」「3要素の」「3進法の」といった意味を持ちます。

1ビットから1.58ビットへ
「1ビットの次に1.58ビットって何だよ」と思った人もいるでしょうが、マイクロソフトのBitNetをご存知の方にはもうお分かりのはず。
1ビットBonsaiでは、すべてのウェイトが -1 か +1 の2値でした。Ternary(三値、といってもコズミックホラーTRPGではない)Bonsaiでは、{-1, 0, +1} の3値になります。log₂(3) ≈ 1.585 で、つまり1ウェイトあたり1.58ビットの情報量。0.58ビット増えただけ。
でもこの「0(何もしない)」という選択肢が加わることで、ネットワークの表現力が跳ね上がるのです。スパース性が入る。不要な接続を0にできる。脳のシナプスが「つながっている/つながっていない」だけでなく「つながっているけど使わない」も選べるようになった、みたいな話です。
スペック比較
Bonsai 8B (1-bit) | Ternary Bonsai 8B (1.58-bit) | Qwen3 8B (FP16) | |
メモリ | 1.15 GB | 1.75 GB | 16.38 GB |
ベンチ平均 | 70.5 | 75.5 | 78.2 |
MMLU Redux | -- | 高い | 最高 |
GSM8K | -- | 高い | 最高 |
HumanEval+ | -- | 高い | 最高 |
Tool Calling | OK | OK | OK |
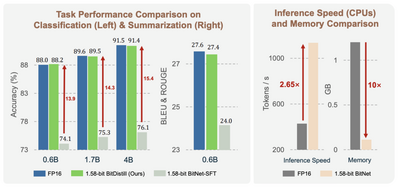
600MBの増加で、ベンチマークが5ポイント上がっています。1.15GBから1.75GBへの53%増に対して、品質は7%向上。FP16のQwen3 8B(16.38GB)にはまだ及ばないものの、メモリは9.4分の1です。MMLU Redux、MuSR、GSM8K、HumanEval+、IFEval、BFCLv3と広範なベンチマークで均等にスコアが伸びている、というのがPrismMLの説明です。
8GBのMacBook Neoで動かしてみる
前回のBonsai 8Bは、PrismMLフォーク版のllama-serverが必要でした。GGUF形式で、専用のQ1_0_g128カーネルを通して動きます。
Ternary BonsaiはMLX形式のみ。つまりApple Siliconネイティブです。HuggingFaceのモデルID は `prism-ml/Ternary-Bonsai-8B-mlx-2bit`。
動かし方は拍子抜けするほど簡単でした。
python3 -m mlx_lm server --model prism-ml/Ternary-Bonsai-8B-mlx-2bit --port 8082
これだけ。PrismMLのMLXフォークをソースビルドする必要もなく、pip で入る標準の `mlx-lm` パッケージで動きます。Xcodeも不要。初回実行時にHuggingFaceから1.75GBのモデルが自動ダウンロードされて、数秒後にOpenAI互換のAPIサーバが立ち上がります。
最初のテストの結果はこんな感じ:
Prompt: 18 tokens, 7.063 tokens-per-sec
Generation: 40 tokens, 19.328 tokens-per-sec
Peak memory: 2.365 GB
19.3 tok/s。ピークメモリ2.365GB。ミニマルな8GBマシンの中で、余裕で動いています。
mazzaineoへの統合:1行追加
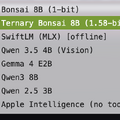
自作しているmazzaineoのエージェントシステムには、バックエンド切り替えの仕組みがあります。Ollama、llama.cpp(OpenAI互換)、SwiftLM(MLX)、Apple Intelligence と、すでに4つのバックエンドを使い分けています。
Ternary BonsaiのMLXサーバはOpenAI互換APIに対応しているので、agent.pyのMODEL_REGISTRYに1行追加するだけ:
"ternary-bonsai-8b": (BONSAI_BASE, "prism-ml/Ternary-Bonsai-8B-mlx-2bit", BACKEND_OPENAI),
ポート8082は1-bit Bonsai(llama-server)と共有ですが、どちらか一方を起動しておけばOK。サーバを再起動すると、モデルセレクタに「Ternary Bonsai 8B (1.58-bit)」が出現します。UIのサブタイトルも自動で「Ternary Bonsai 8B (1.58-bit) + MLX」に切り替え。
使ってみた印象
1-bit Bonsaiとの違いは、最初の数ターンの会話で感じます。日本語の応答が少し丁寧になった。文の接続がスムーズ。「8GBマシンで動いてるモデルの応答」という先入観を忘れる瞬間があります。
前回のBonsaiでは日本語に歯抜けが多くて、使いづらい部分が多かったのです。Gemma 4やQwen 3と比べるとやはり劣る。それが、同レベルとまではいかないまでも、かなり近い、実用的な領域に入ってきた感がします。
ベンチマーク5ポイントの差が、体感でどう出るかは正直まちまちです。短い質問への回答ではほとんど違いがわからない。差が出るのは、複数ステップの推論が必要な場面。「東京の天気を調べて、明日の予定と組み合わせて提案して」みたいな、Tool Callingを2回連鎖する場面で、Ternary Bonsaiの方が文脈を保持する力が強いです。エージェンティックAIではこの性能差は大きいです。
速度は1-bit Bonsai(llama-cpp、21.1 tok/s)と比べると19.3 tok/sでやや遅い。しかしこれはMLXサーバの初回テストの値で、PrismMLの発表によればM4 Proでは82 tok/s出るそうです。前世代のiPhoneレベルのSoCを搭載したMacBook Neoではまだそこまで回っていませんが、最適化の余地はありそうです。
8GBマシンの現在地
2週間前に書いた「おすすめ構成」を更新します。
用途 | おすすめ | 理由 |
品質最重視 | Ternary Bonsai 8B | 1.75GBで75.5点、Tool Calling完璧 |
品質重視 | Bonsai 8B (1-bit) | 1.15GBで70.5点、最小フットプリント |
速度重視 | Ollama Qwen3 8B | Ollamaのkv-cache量子化が効く |
Vision | Qwen 3.5 4B / Gemma 4 E2B | カメラ/スクリーンキャプチャ対応 |
軽量会話 | Qwen 2.5 3B | 最も軽い、エージェント不要時 |
mazzaineoのモデルセレクタには現在8つのモデルが並んでいます。8GBのMacBook Neoで、状況に応じて使い分けられる。贅沢な話です。
1.58ビットが示すもの
1ビットBonsaiのときに「8GBで十分」と書きました。Ternary Bonsaiは、その「十分」のラインをさらに引き上げてきました。
600MBの追加コストで、8Bパラメータモデルの品質がもう一段上がる。FP16モデルの9分の1のメモリで、ほとんどの実用シナリオを賄える品質。PrismMLはこれを「パレートフロンティアの拡張」と呼んでいますが、要するに「小ささと賢さのトレードオフで、今までありえなかった場所にモデルを置けるようになった」ということ。
1ビットから1.58ビットへ。0.58ビット分の進化が、8GBマシンの景色をまた少し変えてくれました。

Ternary BonsaiはMacBook Neoのような低スペックMacだけでなく、iPhoneのようにスペック的にはNeoより上だけどiOSのメモリ制限があるスマートフォンにも有用です。
自作しているiPhone用のLLM音声対話アプリでは、メモリ制限によりBonsai 8Bは実用にはなりませんでしたが、今度は1.58bitの4B、2Bモデルも出たので、そちらが試せます。これもやらねばの娘。
すでにiPhone用LLMクライアントのLocally AI(LM Studioに買収されたばかり)では、Ternary Bonsai 8Bがダウンロードできるようになってます。仕事早い!

一方、Qwenも3.6が登場。1bit、1.58bit、量子化などで最適化が進む一方で、元となるAIモデルも進化。常に最適解は変わっていくのですね。
そして、最新のmacOSに最適化されたエージェンティックAI「Agent!」もオープンソースで登場。これベースにしたらさらに進化できるのでは?
Claude Codeに相談したら、mazzaineoをMCPエージェントにして、両方を動かすのが吉だと出たので、さきほどMCP実装を完了しました。なんか、今日はすごいな。
※この記事は、Claude Codeでの実装作業の記録を元に、筆者が修正・加筆したものです。
ちなみに、Ternary Bonsaiにやらせようとしていた「オイラーはドラマー」という小説。出たばかりのClaude Opus 4.7に完成させました。