








この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第132回)は、Nano Banana Proに迫る性能を示す画像内の文字を正確に生成するAIモデル「Qwen-Image-2.0」や、GPT-5.2やGemini 3.0 Proとやり合える成績を示す1960億パラメータの軽量AI「Step 3.5 Flash」を取り上げます。
またZ.aiが開発したオープンソースLLM「GLM-5」や、アリババのフィンテック企業が開発した画面を見て自律操作するGUIエージェントAI「UI-Venus-1.5」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、公開直後から国際的な著作権紛争を巻き起こしているByteDance開発の動画生成AI「Seedance 2.0」を別の単体記事で取り上げています。
GPT-5.2やGemini 3.0 Proとやり合える成績、1960億パラメータの軽量AI「Step 3.5 Flash」
StepFunが発表した「Step 3.5 Flash」は、総パラメータ数1960億のMoE(Mixture-of-Experts)モデルです。多数の専門家ネットワークの中から毎回一部だけを選んで使う仕組みにより、1トークンあたりの活性パラメータは110億に抑えられています。
大きな知識容量を持ちながら推論が軽いという設計で、Hopper GPU上で毎秒約170トークンの生成速度を記録しました。
学習には4096基の高性能GPU(NVIDIA H800)を使い、約17.6兆トークンという膨大なデータで訓練されました。学習後の仕上げ段階では、数学・プログラミング・ツールの使い方などの分野ごとに専門家モデルをまず作り、それらの知識を1つのモデルに統合するという方法を取っています。さらに「MIS-PO」という新しい強化学習の手法を開発し、学習を安定させました。
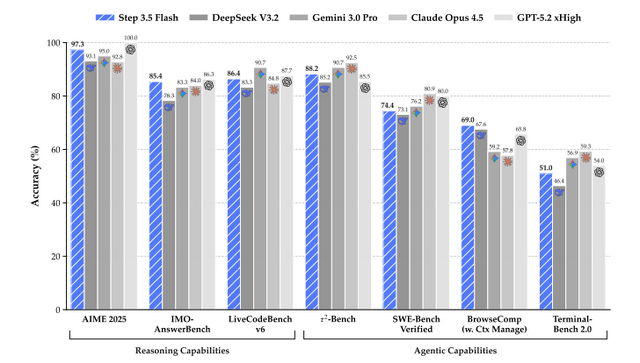
結果として、数学のベンチマーク「AIME 2025」で正答率97.3%、国際数学オリンピックレベルのベンチマーク「IMO-AnswerBench」で85.4%とGoogleのGemini 3.0 ProやClaude Opus 4.5を上回っています。また、プログラミングのベンチマーク「LiveCodeBench」で86.4%を達成しており、OpenAIのGPT-5.2 xHighに迫る勢いです。
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
StepFun Team
Paper | GitHub | Hugging Face
Z.ai、オープンソースLLM「GLM-5」を公開 7440億パラメータでフロンティアモデルに迫る
中国のZ.aiが、MoE(Mixture of Experts)を用いた大規模言語モデル「GLM-5」を発表しました。
前世代のGLM-4.5と比べると、総パラメータ数は355Bから744Bへ、アクティブパラメータは32Bから40Bへと拡大し、事前学習データも23兆から28.5兆トークンに増えました。
DeepSeekが開発したSparse Attentionを統合することで、長文処理を維持しつつデプロイコストを抑えています。後処理の面では、独自の非同期強化学習基盤「slime」を開発し、学習スループットと効率を大幅に改善しました。
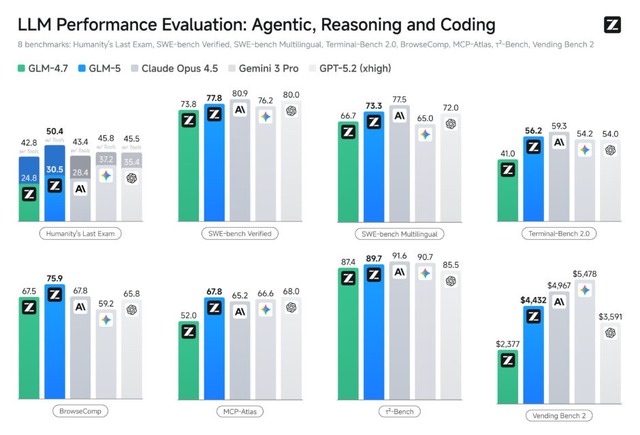
ベンチマークでは、推論・コーディング・エージェントの各タスクにおいてオープンソースモデルとしてトップクラスの性能を達成し、フロンティアモデルとの差を縮めたとしています。
また、仮想の自動販売機ビジネスを1年間運営するベンチマーク「Vending Bench 2」では、オープンソースモデル1位の4,432ドルを達成し、Claude Opus 4.5の4,967ドルに迫る結果となりました。
From Vibe Coding to Agentic Engineering
Z.ai Team
Project | GitHub | Hugging Face
Nano Banana Proに迫る実力、文字入り画像を高精度生成するAIモデル「Qwen-Image-2.0」をアリババが発表
AlibabaのQwenチームが画像生成モデル「Qwen-Image-2.0」を発表しました。最大の特徴は1kトークンの長い指示に対応した高品質のタイポグラフィ描画で、PPTやポスター、インフォグラフィック、漫画などを直接生成できます。
複数の書体の使い分け、画像内構成、カレンダーやコマ割り内のテキスト整列まで正確にこなします。2K解像度のフォトリアリズムも大幅に向上し、ガラスや布地など異なる素材上のテキストも照明・反射を含めて自然に描画します。
Qwen-Image-2.0は、テキストから画像への変換と画像から画像への変換の両方のベンチマークにおいて、同一モデルを用いた場合に優れたパフォーマンスを発揮することが示され、特に両者トップのGemini-3-Pro-Image-Preview(Nano Banana Pro)に迫る性能が示されました。





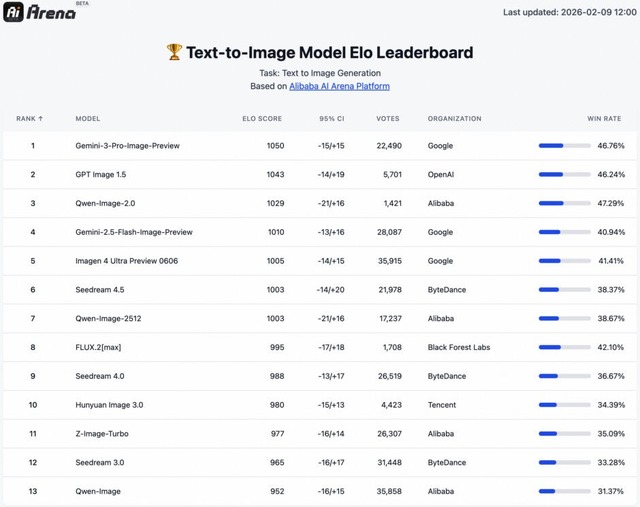
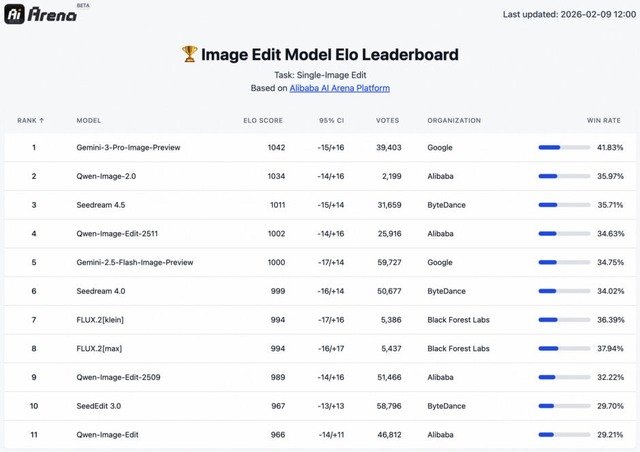
Qwen-Image-2.0
Qwen Team
Project
実機で学ぶ、画面を見て自律操作するAI「UI-Venus-1.5」をアリババのフィンテック企業が開発
アリババグループのフィンテック企業Ant Groupが開発した「UI-Venus-1.5」は、スマートフォンやウェブブラウザの画面を視覚的に認識し、人間の代わりに自律的に操作できるマルチモーダルAIです。2B、8B、30B-A3Bの3つのモデルサイズが用意されています。
主な改良点は、100億トークンによるGUI知識の中間学習、数千台の実機上でのオンライン強化学習、そして別々に訓練した専門モデル3つを1つに統合するモデルマージの3点です。従来のオフライン学習では個別ステップの精度は上がってもタスク全体の成功率が伸び悩む問題がありましたが、軌跡全体への報酬設計で改善しています。
ベンチマークではScreenSpot-Pro 69.6%、AndroidWorld 77.6%、WebVoyager 76.0%など多数で最高性能を達成し、8Bモデルが前世代72Bを上回る効率性も示しました。
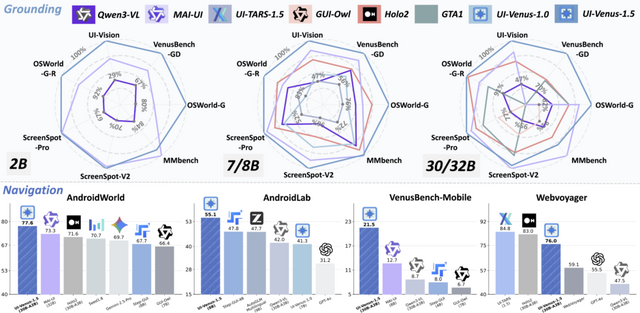







![イヤホン 有線 [HIFI音質]イヤホン 有線 3.5mmジャック ノイズ低減 通話/音楽 音量調節対応 防水 通勤・会議・運動 | 原音再現 MFi認証 重低音 遅延なし コンパクト 軽量 インイヤー 人体工学 image](https://m.media-amazon.com/images/I/31CBe3mkz-L._SL160_.jpg)






