


この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第127回)は、Sora 2 Pro越え性能でテキストから音声付き動画を生成するAI「LTX-2」や、スマホで撮った普通の動画を4Dシーンに変換するAIモデル「NeoVerse」を取り上げます。
また、研究者がAI登場によりどれくらい恩恵を受けているかを調査した研究や、20億パラメータ以下では最高性能のテンセントが開発した小型言語モデル「Youtu-LLM」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、ChatGPTなどのチャット内容を盗むChrome拡張機能が90万回以上ダウンロードされていると報告したレポートを別の単体記事で取り上げています。
Sora 2 Pro超えの性能、テキスト入力で音声付き動画を生成するAIモデル「LTX-2」、最長20秒の生成が可能
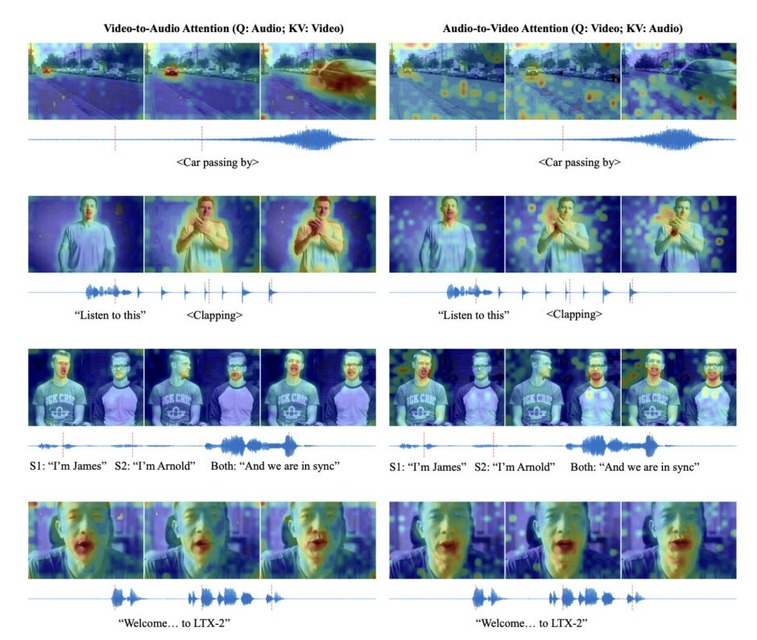
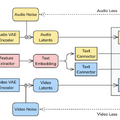
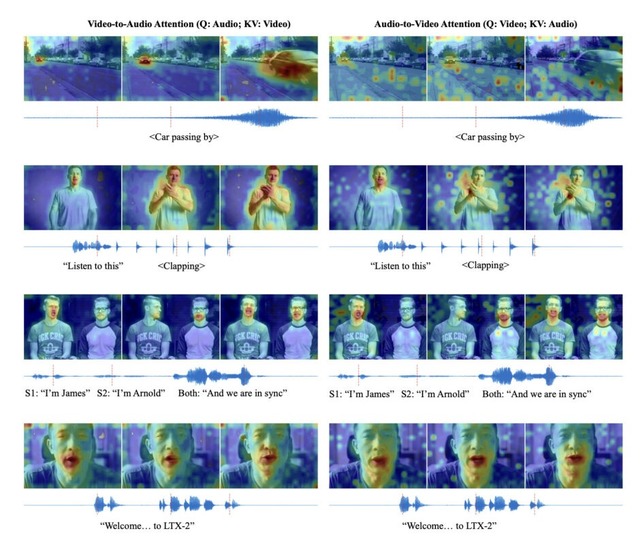
これまでの動画生成AIは映像のみで無音だったり、映像生成後に音声を別で生成して合成したりする手法が主流でしたが、「LTX-2」はテキストプロンプトから映像と音声を一つの統合されたモデルで同時に生成します。リップシンクや効果音のタイミングが自然に生成されます。
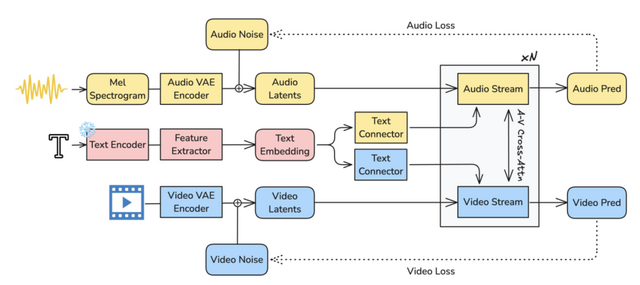
技術的には、140億パラメータの映像用ストリームと50億パラメータの音声用ストリームを組み合わせたデュアルストリーム構造を採用しており、映像と音声がお互いの情報をやり取りしながら生成を行うことで、自然な同期を実現しています。
また、Gemma 3を用いた多言語テキストエンコーダーや「Thinking Tokens」などを取り入れることで、複雑なプロンプトの理解や発音の精度を向上させ、話者のリップシンクや環境音の再現性を高めています。
性能面でも非常に効率的で、既存の動画生成AI「Wan 2.2」と比較して約18倍もの推論速度を誇ります。それでいて動画生成ベンチマークにおいて、Sora 2 Proより高いレベルに達しています。最長20秒の動画生成が可能です。
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, Eitan Richardson, Guy Shiran, Itay Chachy, Jonathan Chetboun, Michael Finkelson, Michael Kupchick, Nir Zabari, Nitzan Guetta, Noa Kotler, Ofir Bibi, Ori Gordon, Poriya Panet, Roi Benita, Shahar Armon, Victor Kulikov, Yaron Inger, Yonatan Shiftan, Zeev Melumian, Zeev Farbman
Project | Paper | GitHub
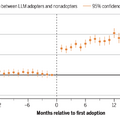
“母語が英語でない研究者”、AI利用で論文投稿数が最大89%増。ただし査読付きジャーナルへの掲載率は低下
研究チームはarXiv、bioRxiv、SSRNという3つの主要プレプリントサーバーから約210万件の論文(2018年~2024年)を分析し、ChatGPT登場後のLLM利用の広がりを追跡しました。
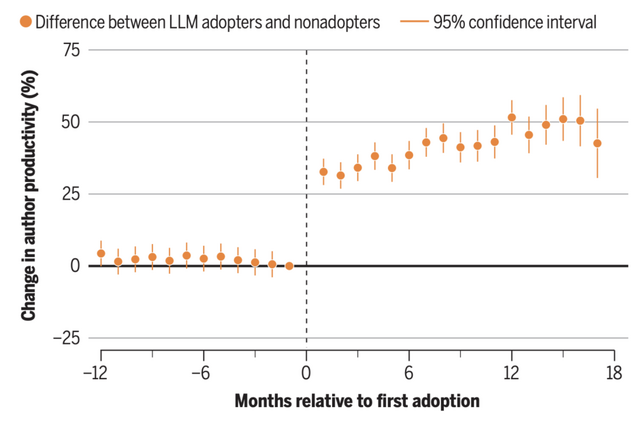
その結果、LLMを使い始めた研究者は論文の投稿数が36~60%(arXivで36.2%、bioRxivで52.9%、SSRNで59.8%)も増加することがわかりました。
特に顕著だったのは非英語圏の研究者への恩恵です。アジア系の名前を持ちアジアの機関に所属する研究者では、生産性の向上が最大89%に達しました。これは英語での執筆コストをLLMが大幅に削減するためと考えられます。
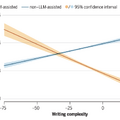
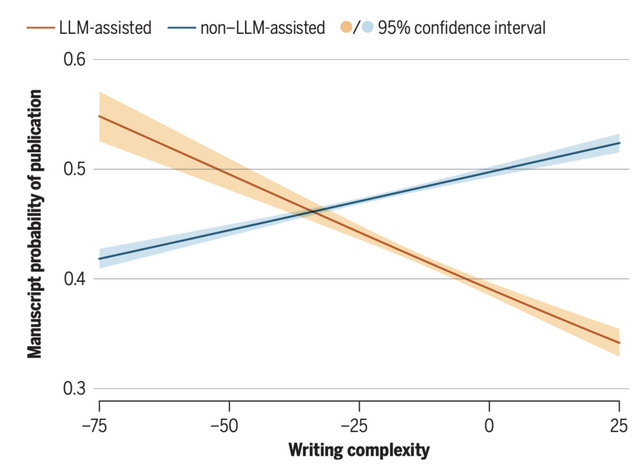
しかし、生産性の向上の一方で、文章の質が持つ意味合いには変化が生じています。従来、語彙や構文が複雑で洗練された英語論文は科学的な質も高いと評価される傾向にありましたが、LLMを使用した論文においては、この相関関係が逆転していることが判明しました。
つまり、LLMの支援を受けて言語的に複雑な文章を作成した論文ほど、査読付きジャーナルへの掲載確率や専門家による評価スコアが低くなるという傾向が確認されたのです。
これは、AIによって表面的な文章の流暢さは簡単に達成できるようになったものの、それが内容の乏しさを隠すために使われている可能性があり、文章力が研究の質の指標として機能しなくなっていることを意味します。
一方で、AIを利用した検索は、ユーザーをより多様な文献へと導いていることが分かりました。特に、書籍の引用や引用数がまだ少ないマイナーな論文も発見されやすくなっていました。この結果は、AIが特定の有名論文ばかりを強化するのではなく、むしろ研究者の視野を広げ、多様な知識へのアクセスを促進していることを示唆しています。
Scientific production in the era of large language models
Keigo Kusumegi, Xinyu Yang, Paul Ginsparg, Mathijs de Vaan, Toby Stuart, Yian Yin
Paper
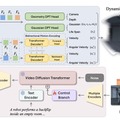
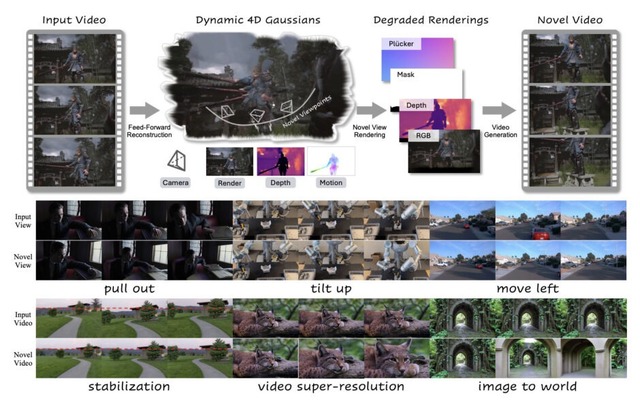
スマホで撮った動画を4Dシーンに変換するAIモデル「NeoVerse」、撮影後の視点変更が自在に
「NeoVerse」は単眼映像から4Dシーンを再構成し、新しいカメラ軌道でのビデオ生成を可能にするAIモデルです。スマホで撮った動画から3D空間+時間(4D)の世界を再現できます。
従来の手法では、高品質な4Dモデルを構築するために専用のマルチビュー動的映像が必要だったり、重い前処理をオフラインで実行する必要があったりと、スケーラビリティに大きな課題がありました。
NeoVerseはこれらの制約を取り払い、インターネット上で簡単に入手できる一般的な単眼映像(約100万クリップ)を学習に活用できる設計になっています。
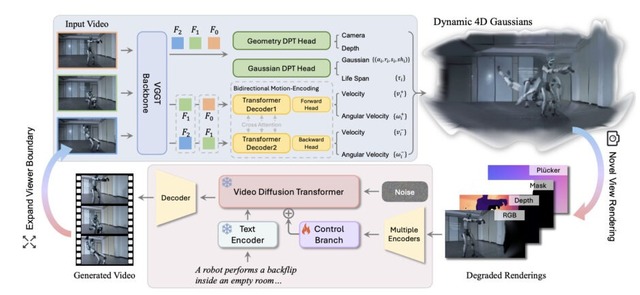
具体的には、カメラ位置の情報がない映像からでも瞬時に4Dガウシアン・スプラッティング(4DGS)を再構成できるフィードフォワード型モデルを採用し、双方向の動き予測を取り入れることで処理を高速化しました。
さらに学習プロセスにおいて、新しい視点へカメラを動かした際に生じる「オクルージョン」や「画像の歪み」といった劣化パターンをあえてシミュレーションし、それを生成モデルが補完・修復するように訓練する仕組みを導入しています。
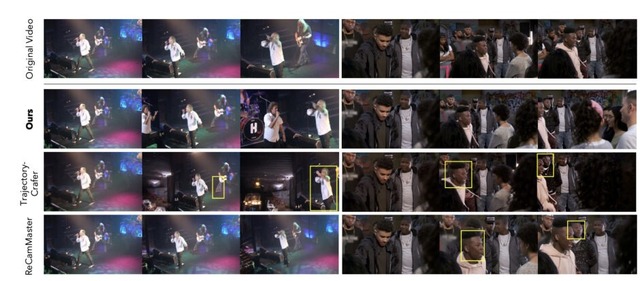
実験では、静的・動的シーンの再構成ベンチマークと生成ベンチマークの両方で最先端の性能を達成しました。また、4D再構成以外にも、ビデオ編集、手ぶれ補正、超解像度、3Dトラッキング、単一画像からの3Dワールド探索など、多様な応用が可能です。
NeoVerse: Enhancing 4D World Model with in-the-wild Monocular Videos
Yuxue Yang, Lue Fan, Ziqi Shi, Junran Peng, Feng Wang, Zhaoxiang Zhang
Project | Paper | GitHub
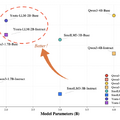
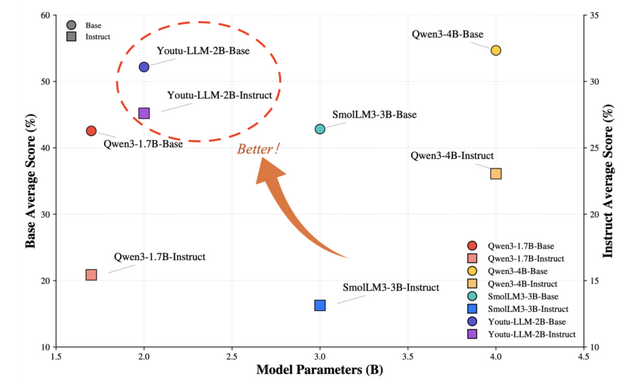
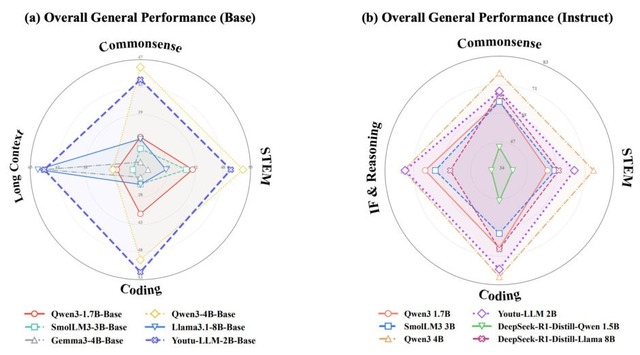
20億パラメータ以下では最高性能の小型言語モデル「Youtu-LLM」をテンセントが開発
テンセントのYoutuチームが、小型ながらエージェント能力に優れた言語モデル「Youtu-LLM」を発表しました。パラメータ数は約20億で、既存の小型モデルが大きなモデルからの蒸留に頼りがちな中、このモデルはゼロから事前学習することで本質的な推論・計画能力を獲得しています。
アーキテクチャにはDeepSeek-V3と同様のMLA(Multi-Latent Attention)を採用し、メモリ効率を高めつつ128kトークンの長いコンテキストに対応しています。トークナイザーも独自設計で、数学やコード領域での効率が従来比約10%向上しています。
学習プロセスでは約11兆トークンのデータを使用し、一般的な常識から複雑なSTEMタスク、そしてエージェントタスクへと段階的にデータを移行させる独自のカリキュラムが導入されました。
多くの小型AIは言われたことに答えるだけですが、Youtu-LLMは自分で計画を立て、ツールを使い、結果を振り返るというエージェント的な行動ができるように設計されています。
Youtu-LLMは、汎用ベンチマークとエージェントベンチマークの両方において、同規模の既存最先端モデルを大幅に上回り、いくつかの設定では、かなり大規模なモデルに匹敵する性能を示しています。20億パラメータ以下のモデルとして最高性能を達成しています。
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Youtu-LLM Team
Project | Paper | GitHub